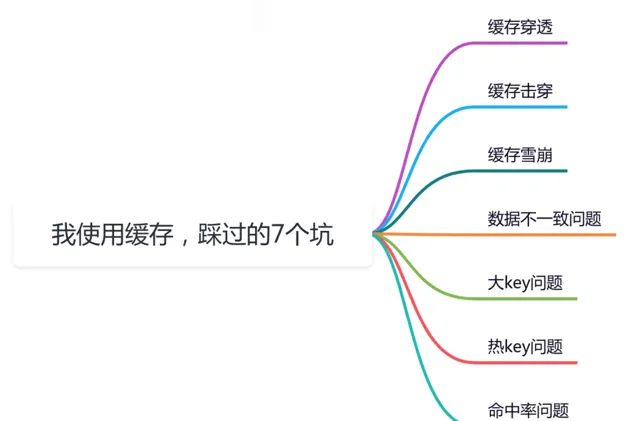
前言
緩存在我們日常工作中,經常會使用,但如果用不好坑也挺多的。
這篇文章總結了我工作中使用緩存遇到過的7個坑,還是非常有參考價值得,希望對你會有所幫助。
1 緩存穿透
大部份情況下,加緩存的目的是:為了減輕資料庫的壓力,提升系統的效能。
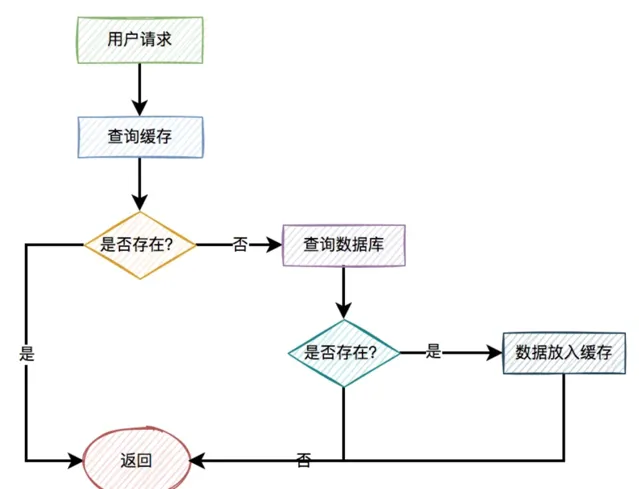
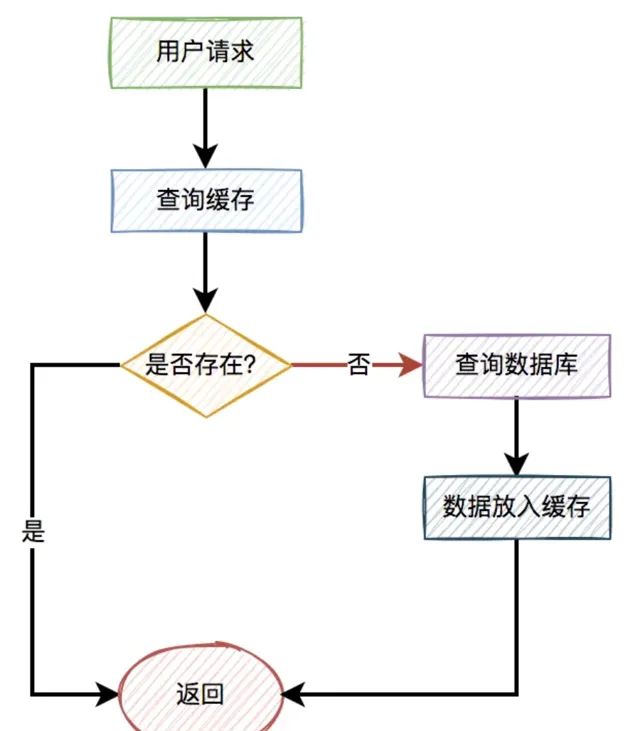
一般情況下,如果有使用者請求過來,先查緩存,如果緩存中存在數據,則直接返回。
如果緩存中不存在,則再查資料庫,如果資料庫中存在,則將數據放入緩存,然後返回。如果資料庫中也不存在,則直接返回失敗。
流程圖如下:
但如果出現以下這兩種特殊情況,比如:
使用者請求的id在緩存中不存在。
惡意使用者偽造不存在的id發起請求。
這樣的使用者請求導致的結果是:每次從緩存中都查不到數據,而需要查詢資料庫,同時資料庫中也沒有查到該數據,也沒法放入緩存。
也就是說,每次這個使用者請求過來的時候,都要查詢一次資料庫。
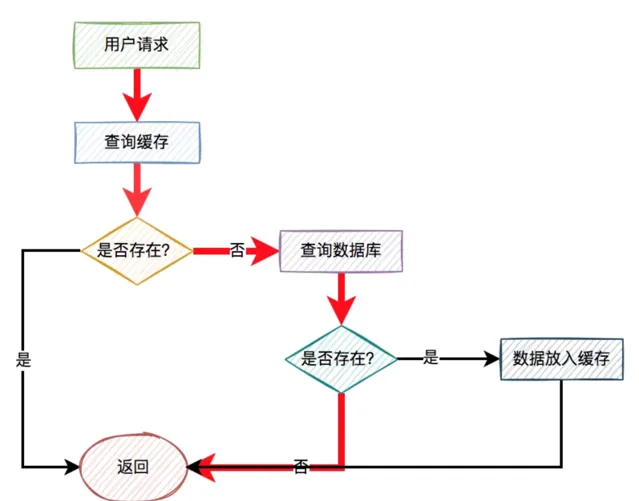
圖中標紅的箭頭表示每次走的路線。
很顯然,緩存根本沒起作用,好像被穿透了一樣,每次都會去存取資料庫。
這就是我們所說的:緩存穿透問題。
如果此時穿透了緩存,而直接資料庫的請求數量非常多,資料庫可能因為扛不住壓力而掛掉。嗚嗚嗚。
那麽問題來了,如何解決這個問題呢?
1.1 校驗參數
我們可以對使用者id做檢驗。
比如你的合法id是15xxxxxx,以15開頭的。如果使用者傳入了16開頭的id,比如:16232323,則參數校驗失敗,直接把相關請求攔截掉。這樣可以過濾掉一部份惡意偽造的使用者id。
1.2 使用布隆過濾器
如果數據比較少,我們可以把資料庫中的數據,全部放到記憶體的一個map中。
這樣能夠非常快速的辨識,數據在緩存中是否存在。如果存在,則讓其存取緩存。如果不存在,則直接拒絕該請求。
但如果數據量太多了,有數千萬或者上億的數據,全都放到記憶體中,很顯然會占用太多的記憶體空間。
那麽,有沒有辦法減少記憶體空間呢?
答:這就需要使用布隆過濾器了。
布隆過濾器底層使用bit陣列儲存數據,該陣列中的元素預設值是0。
布隆過濾器第一次初始化的時候,會把資料庫中所有已存在的key,經過一些列的hash演算法(比如:三次hash演算法)計算,每個key都會計算出多個位置,然後把這些位置上的元素值設定成1。
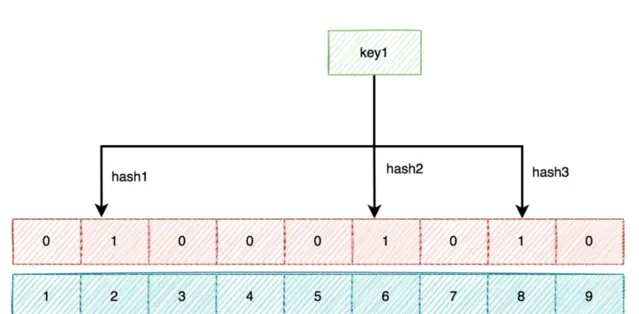
之後,有使用者key請求過來的時候,再用相同的hash演算法計算位置。
如果多個位置中的元素值都是1,則說明該key在資料庫中已存在。這時允許繼續往後面操作。
如果有1個以上的位置上的元素值是0,則說明該key在資料庫中不存在。這時可以拒絕該請求,而直接返回。
1.3 緩存空值
上面使用布隆過濾器,雖說可以過濾掉很多不存在的使用者id請求。但它除了增加系統的復雜度之外,會帶來兩個問題:
布隆過濾器存在誤殺的情況,可能會把少部份正常使用者的請求也過濾了。
如果使用者資訊有變化,需要即時同步到布隆過濾器,不然會有問題。
所以,通常情況下,我們很少用布隆過濾器解決緩存穿透問題。其實,還有另外一種更簡單的方案,即:緩存空值。
當某個使用者id在緩存中查不到,在資料庫中也查不到時,也需要將該使用者id緩存起來,只不過值是空的。
這樣後面的請求,再拿相同的使用者id發起請求時,就能從緩存中獲取空數據,直接返回了,而無需再去查一次資料庫。
最佳化之後的流程圖如下:
2 緩存擊穿
有時候,我們在存取熱點數據時。比如:我們在某個商城購買某個熱門商品。
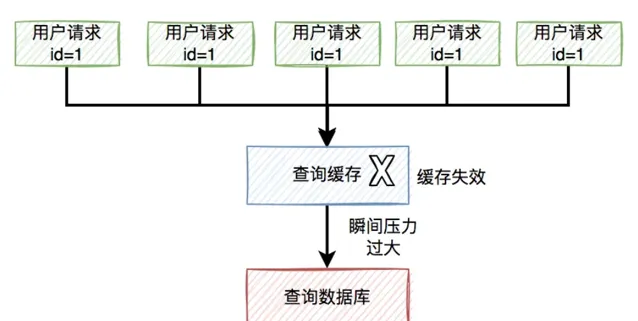
為了保證存取速度,通常情況下,商城系統會把商品資訊放到緩存中。但如果某個時刻,該商品到了過期時間失效了。
此時,如果有大量的使用者請求同一個商品,但該商品在緩存中失效了,一下子這些使用者請求都直接懟到資料庫,可能會造成瞬間資料庫壓力過大,而直接掛掉。
流程圖如下:
那麽,如何解決這個問題呢?
2.1 加鎖
資料庫壓力過大的根源是,因為同一時刻太多的請求存取了資料庫。
如果我們能夠限制,同一時刻只有一個請求才能存取某個productId的資料庫商品資訊,不就能解決問題了?
答:沒錯,我們可以用加鎖的方式,實作上面的功能。
虛擬碼如下:
try {
String result = jedis.set(productId, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return queryProductFromDbById(productId);
}
} finally{
unlock(productId,requestId);
}
returnnull;
在存取資料庫時加鎖,防止多個相同productId的請求同時存取資料庫。
然後,還需要一段程式碼,把從資料庫中查詢到的結果,又重新放入緩存中。辦法挺多的,在這裏我就不展開了。
2.2 自動續期
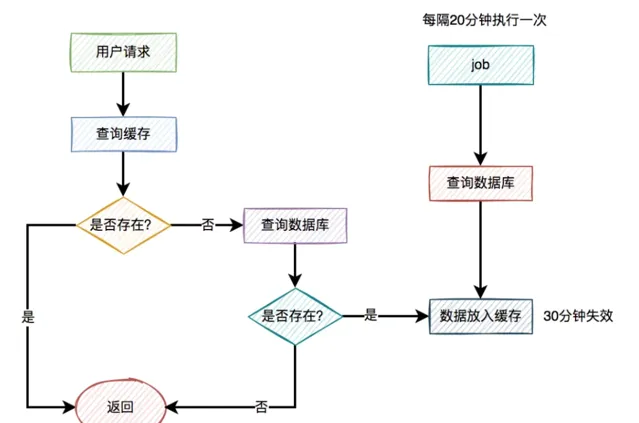
出現緩存擊穿問題是由於key過期了導致的。那麽,我們換一種思路,在key快要過期之前,就自動給它續期,不就OK了?
答:沒錯,我們可以用job給指定key自動續期。
比如說,我們有個分類功能,設定的緩存過期時間是30分鐘。但有個job每隔20分鐘執行一次,自動更新緩存,重新設定過期時間為30分鐘。
2.3 永久有效
此外,對於很多熱門key,其實是可以不用設定過期時間,讓其永久有效的。
比如參與秒殺活動的熱門商品,由於這類商品id並不多,在緩存中我們可以不設定過期時間。
在秒殺活動開始前,我們先用一個程式提前從資料庫中查詢出商品的數據,然後同步到緩存中,提前做預熱。
等秒殺活動結束一段時間之後,我們再手動刪除這些無用的緩存即可。
3 緩存雪崩
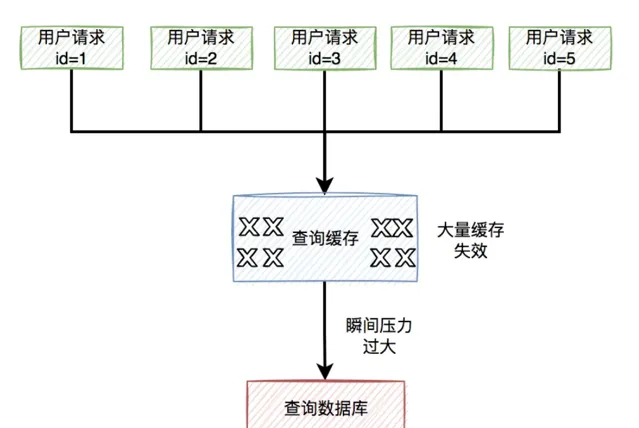
而緩存雪崩是緩存擊穿的升級版,緩存擊穿說的是某一個熱門key失效了,而緩存雪崩說的是有多個熱門key同時失效。
看起來,如果發生緩存雪崩,問題更嚴重。
緩存雪崩目前有兩種:
有大量的熱門緩存,同時失效。會導致大量的請求,存取資料庫。而資料庫很有可能因為扛不住壓力,而直接掛掉。
緩存伺服器down機了,可能是機器硬體問題,或者機房網路問題。總之,造成了整個緩存的不可用。
歸根結底都是有大量的請求,透過緩存,而直接存取資料庫了。
那麽,要如何解決這個問題呢?
3.1 過期時間加隨機數
為了解決緩存雪崩問題,我們首先要盡量避免緩存同時失效的情況發生。
這就要求我們不要設定相同的過期時間。
可以在設定的過期時間基礎上,再加個1~60秒的隨機數。
實際過期時間 = 過期時間 + 1~60秒的隨機數
這樣即使在高並行的情況下,多個請求同時設定過期時間,由於有隨機數的存在,也不會出現太多相同的過期key。
3.2 保證高可用
針對緩存伺服器down機的情況,在前期做系統設計時,可以做一些高可用架構。
比如:如果使用了redis,可以使用哨兵模式,或者集群模式,避免出現單節點故障導致整個redis服務不可用的情況。
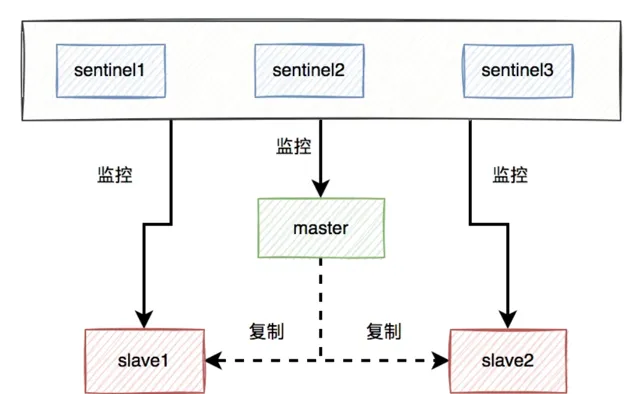
使用哨兵模式之後,當某個master服務下線時,自動將該master下的某個slave服務升級為master服務,替代已下線的master服務繼續處理請求。
3.3 服務降級
如果做了高可用架構,redis服務還是掛了,該怎麽辦呢?
這時候,就需要做服務降級了。
我們需要配置一些預設的兜底數據。
程式中有個全域開關,比如有10個請求在最近一分鐘內,從redis中獲取數據失敗,則全域開關開啟。後面的新請求,就直接從配置中心中獲取預設的數據。
當然,還需要有個job,每隔一定時間去從redis中獲取數據,如果在最近一分鐘內可以獲取到兩次數據(這個參數可以自己定),則把全域開關關閉。後面來的請求,又可以正常從redis中獲取數據了。
需要特別說一句,該方案並非所有的場景都適用,需要根據實際業務場景決定。
4 數據不一致
資料庫和緩存(比如:redis)雙寫數據一致性問題,是一個跟開發語言無關的公共問題。尤其在高並行的場景下,這個問題變得更加嚴重。
那麽,我們該如何更新緩存呢?
目前有以下4種方案:
先寫緩存,再寫資料庫
先寫資料庫,再寫緩存
先刪緩存,再寫資料庫
先寫資料庫,再刪緩存
4.1 先寫緩存,再寫資料庫
對於更新緩存的方案,很多人第一個想到的可能是在寫操作中直接更新緩存(寫緩存),更直接明了。
那麽,問題來了:在寫操作中,到底是先寫緩存,還是先寫資料庫呢?
我們在這裏先聊聊先寫緩存,再寫資料庫的情況,因為它的問題最嚴重。
某一個使用者的每一次寫操作,如果剛寫完緩存,突然網路出現了異常,導致寫資料庫失敗了。
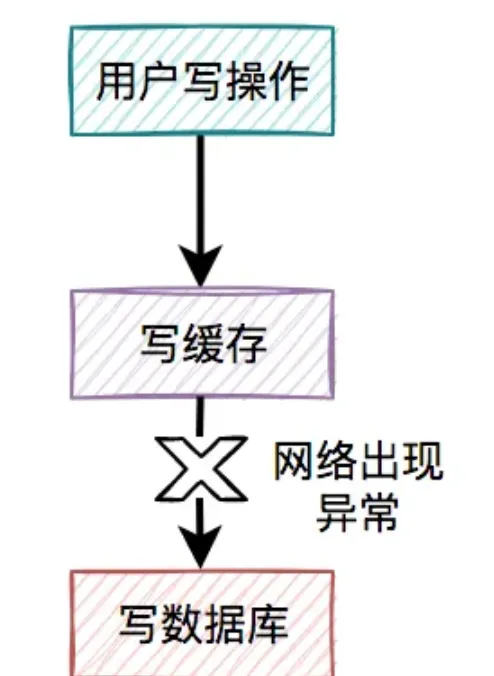
其結果是緩存更新成了最新數據,但資料庫沒有,這樣緩存中的數據不就變成臟數據了?如果此時該使用者的查詢請求,正好讀取到該數據,就會出現問題,因為該數據在資料庫中根本不存在,這個問題非常嚴重。
我們都知道,緩存的主要目的是把資料庫的數據臨時保存在記憶體,便於後續的查詢,提升查詢速度。
但如果某條數據,在資料庫中都不存在,你緩存這種「假數據」又有啥意義呢?
因此,先寫緩存,再寫資料庫的方案是不可取的,在實際工作中用得不多。
4.2 先寫資料庫,再寫緩存
既然上面的方案行不通,接下來,聊聊先寫資料庫,再寫緩存的方案,該方案在低並行編程中有人在用(我猜的)。
使用者的寫操作,先寫資料庫,再寫緩存,可以避免之前「假數據」的問題。但它卻帶來了新的問題。
什麽問題呢?
4.2.1 寫緩存失敗了
如果把寫資料庫和寫緩存操作,放在同一個事務當中,當寫緩存失敗了,我們可以把寫入資料庫的數據進行回滾。

如果是並行量比較小,對介面效能要求不太高的系統,可以這麽玩。
但如果在高並行的業務場景中,寫資料庫和寫緩存,都屬於遠端操作。為了防止出現大事務,造成的死結問題,通常建議寫資料庫和寫緩存不要放在同一個事務中。
也就是說在該方案中,如果寫資料庫成功了,但寫緩存失敗了,資料庫中已寫入的數據不會回滾。
這就會出現:資料庫是新數據,而緩存是舊數據,兩邊數據不一致的情況。
4.2.2 高並行下的問題
假設在高並行的場景中,針對同一個使用者的同一條數據,有兩個寫數據請求:a和b,它們同時請求到業務系統。
在這個過程當中,可能會出現請求b在緩存中的新數據,被請求a的舊數據覆蓋了。
也就是說:在高並行場景中,如果多個執行緒同時執行先寫資料庫,再寫緩存的操作,可能會出現資料庫是新值,而緩存中是舊值,兩邊數據不一致的情況。
4.2.3 浪費系統資源
該方案還有一個比較大的問題就是:每個寫操作,寫完資料庫,會馬上寫緩存,比較浪費系統資源。
為什麽這麽說呢?
你可以試想一下,如果寫的緩存,並不是簡單的數據內容,而是要經過非常復雜的計算得出的最終結果。這樣每寫一次緩存,都需要經過一次非常復雜的計算,不是非常浪費系統資源嗎?
尤其是cpu和記憶體資源。
還有些業務場景比較特殊:寫多讀少。
如果在這類業務場景中,每個用的寫操作,都需要寫一次緩存,有點得不償失。
由此可見,在高並行的場景中,先寫資料庫,再寫緩存,這套方案問題挺多的,也不太建議使用。
4.3 先刪緩存,再寫資料庫
說白了,在使用者的寫操作中,先執行刪除緩存操作,再去寫資料庫。這套方案,可以是可以,但也會有一樣問題。
4.3.1 高並行下的問題
假設在高並行的場景中,同一個使用者的同一條數據,有一個讀數據請求c,還有另一個寫數據請求d(一個更新操作),同時請求到業務系統。
在這個過程當中,有可能會出現請求d的新值,並沒有被請求c寫入緩存,同樣會導致緩存和資料庫的數據不一致的情況。
4.4 先寫資料庫,再刪緩存
在高並行的場景中,有一個讀數據請求f,有一個寫數據請求e。
在高並行的場景中,有一個讀數據請求,有一個寫數據請求,更新過程如下:
請求e先寫資料庫,由於網路原因卡頓了一下,沒有來得及刪除緩存。請求f查詢緩存,發現緩存中有數據,直接返回該數據。請求e刪除緩存。在這個過程中,只有請求f讀了一次舊數據,後來舊數據被請求e及時刪除了,看起來問題不大。
但如果是讀數據請求先過來呢?
請求f查詢緩存,發現緩存中有數據,直接返回該數據。
請求e先寫資料庫。
請求e刪除緩存。
這種情況看起來也沒問題呀?
答:對的。
但就怕出現下面這種情況,即緩存自己失效了。如下圖所示:
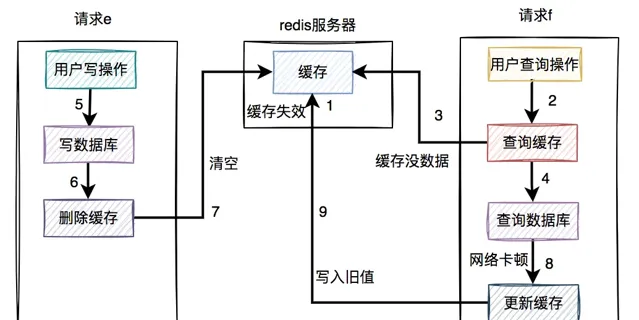
緩存過期時間到了,自動失效。
請求f查詢緩存,發緩存中沒有數據,查詢資料庫的舊值,但由於網路原因卡頓了,沒有來得及更新緩存。
請求e先寫資料庫,接著刪除了緩存。
請求f更新舊值到緩存中。
這時,緩存和資料庫的數據同樣出現不一致的情況了。
但這種情況還是比較少的,需要同時滿足以下條件才可以:
緩存剛好自動失效。
請求f從資料庫查出舊值,更新緩存的耗時,比請求e寫資料庫,並且刪除緩存的還長。
我們都知道查詢資料庫的速度,一般比寫資料庫要快,更何況寫完資料庫,還要刪除緩存。所以絕大多數情況下,寫數據請求比讀數據情況耗時更長。
由此可見,系統同時滿足上述兩個條件的機率非常小。
如果大家想更詳細的了解數據和緩存雙寫一致性問題,可以看看我之前寫的一篇文章【 】,裏面有非常詳細的介紹。
5 大key問題
我們在使用緩存的時候,特別是Redis,還有一個經常會遇到的問題是大key問題。
可能系統剛上線時,數據量少,在Redis中定義的key比較小,開發人員在做系統設計時,也沒考慮這個問題。
系統執行了很長一段時間也沒有問題。
但隨著時間的推移,使用者的數據越來越多,慢慢形成了大key問題。
可能在突然的某一天之後發現,線上某個介面耗時越來越長了。
追查原因,發現是大key問題導致的。
大key問題是指:緩存中單個key的value值過大。
之前我開發過一個分類樹查詢介面,為了效能考慮,使用job提前將分類樹,保存到緩存中。
剛開始分類不多,只有幾百個,分類樹查詢介面的響應挺快的。
但用了幾年之後,分類數據漲到了上萬個,該介面出現了效能問題,一查發現是大key引起的。
我們需要做最佳化,那麽如何最佳化呢?
5.1 縮減欄位名
為了最佳化在Redis中儲存數據的大小,我們首先需要對數據進行瘦身。
只保存需要用到的欄位。
例如:
@AllArgsConstructor
@Data
public classCategory{
private Long id;
private String name;
private Long parentId;
private Date inDate;
private Long inUserId;
private String inUserName;
private List<Category> children;
}
像這個分類物件中inDate、inUserId和inUserName欄位是可以不用保存的。
修改自動名稱。
例如:
@AllArgsConstructor
@Data
public classCategory{
/**
* 分類編號
*/
@JsonProperty("i")
private Long id;
/**
* 分類層級
*/
@JsonProperty("l")
private Integer level;
/**
* 分類名稱
*/
@JsonProperty("n")
private String name;
/**
* 父分類編號
*/
@JsonProperty("p")
private Long parentId;
/**
* 子分類列表
*/
@JsonProperty("c")
private List<Category> children;
}
由於在一萬多條數據中,每條數據的欄位名稱是固定的,他們的重復率太高了。
由此,可以在json序列化時,改成一個簡短的名稱,以便於返回更少的數據大小。
5.2 數據做壓縮
這還不夠,需要對儲存的數據做壓縮。
之前在Redis中保存的key/value,其中的value是json格式的字串。
其實RedisTemplate支持,value保存byte陣列。
先將json字串數據用GZip工具類壓縮成byte陣列,然後保存到Redis中。
再獲取數據時,將byte陣列轉換成json字串,然後再轉換成分類樹。
這樣最佳化之後,保存到Redis中的分類樹的數據大小,一下子減少了10倍,Redis的大key問題被解決了。
6 熱key問題
不知道大家聽說過
二八原理
沒有。
80%的使用者經常存取20%的熱點數據。
這樣帶來的結果是數據的傾斜,不能均勻分布,尤其是高並行系統中問題比較大。
比如你現在搞了一個促銷活動,有幾款商品價效比非常高,這些商品數據在Redis中按分片保存的,不同的數據保存在不同的伺服器節點上。
如果使用者瘋狂搶購其中3款商品,而這3款商品正好保存在同一台Redis伺服端節點。
這樣會出現大量的使用者請求集中存取同一天Redis伺服器節點,該節點很有可能會因為扛不住這麽大的壓力,而直接down機。
這個就是熱key問題帶來的危害。
那麽,如何解決這個問題呢?
6.1 拆分key
在促銷活動開始之前,我們要提前做好評估,分析這些商品哪些是熱點商品。
然後將熱點商品分開保存,不要集中保存到同一台Redis伺服器節點。
這樣不同的Redis伺服器節點,可以分攤一些使用者的請求壓力。
6.2 增加本地緩存
對應熱key,我們可以增加一層本地緩存,能夠提升效能的同時也能避免Redis存取量過大的問題。
但帶來的壞處是,可能會出現數據不一致問題,要根據實際的業務場景選擇。
7 命中率問題
緩存的命中率問題,是一個讓人非常頭疼的問題。
前面的章節已經介紹過。
一般情況下,如果有使用者請求過來,先查緩存,如果緩存中存在數據,則直接返回。
如果緩存中不存在,則再查資料庫,如果資料庫中存在,則將數據放入緩存,然後返回。如果資料庫中也不存在,則直接返回失敗。
流程圖如下:
緩存命中
:直接從緩存中獲取數據。
緩存不命中
:無法從緩存中獲取數據,而要從資料庫獲取其他途徑獲取數據。
我們肯定是希望緩存命中率越高越好,這樣介面的效能越好,但實際工作中卻經常啪啪打臉。
因為可能會出現緩存不存在,或者緩存過期等問題,導致緩存不能命中。
那麽,如何提升緩存的命中率呢?
7.1 緩存預熱
我們在API服務啟動之前,可以先用job,將相關數據先保存到緩存中,做預熱。
這樣後面的使用者請求,就能直接從緩存中獲取數據,而無需存取資料庫了。
7.2 合理調整過期時間
有時候,我們給緩存設定的過期時間太短,導致後面會產生大量的過期緩存。
會導致緩存命中率非常低。
這時需要合理調整過期時間,比如:之前設定1秒的,現在改成5秒,10秒,30秒或者1分鐘等等。
7.3 增加緩存記憶體
如果我們部署的Redis伺服器的記憶體太小,很容易出現記憶體不足的情況,從而會頻繁觸發記憶體淘汰機制。
也會影響緩存的命中率。
這種情況下,我們需要增加緩存記憶體。
緩存的記憶體過小問題,也經常會出現。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:蘇三
來源:蘇三說技術
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











