來源:演算法進階
在平時的科研中,我們經常使用統計機率的相關知識來幫助我們進行城市研究。因此,掌握一定的統計機率相關知識非常有必要。
本文涉及的概念包括:
隨機變量(Random Variable)
密度函式(Density Functions)
白努利分布(Bernoulli Distribution)
二項式分布(Binomial Distribution)
均勻分布(Uniform Distribution)
卜瓦松分布(Poisson Distribution)
正態分布(Normal Distribution)
長尾分布(Long-Tailed Distribution)
學生 t 檢驗分布(Student’s t-test Distribution)
對數正態分布(Lognormal Distribution)
指數分布(Exponential Distribution)
威布爾分布(Weibull Distribution)
Gamma分布(Gamma Distribution)
卡方分布(Chi-square Distribution)
中央極限定理(Central Limit Theorem)
1. 隨機變量
離散隨機變量
隨機實驗的所有可能結果都是隨機變量。一個隨機變量集合用 表示。
如果實驗可能的結果是可數的,那麽它被稱為離散隨機變量。例如,如果你拋硬幣 10 次,你能得到的正面數可以用一個數位表示。或者籃子裏有多少蘋果仍然是可數的。
連續性隨機變數
這些是不能以離散方式表示的值。例如,一個人可能有 1.7 米高,1公尺 80 厘米,1.6666666...米高等等。
2. 密度函式
我們使用密度函式來描述隨機變量 的機率分布。
PMF:機率品質函式
返回離散隨機變量 等於 的值的機率。所有值的總和等於 1。PMF 只能用於離散變量。
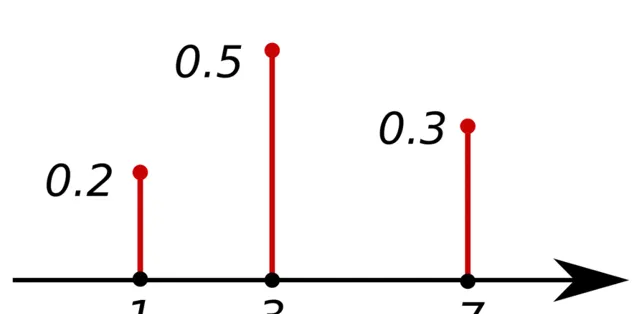
PMF。來源:https://en.wikipedia.org/wiki/Probability_mass_function
PDF:機率密度函式
它類似於連續變量的 PMF 版本。返回連續性隨機變數 X 在某個範圍內的機率。
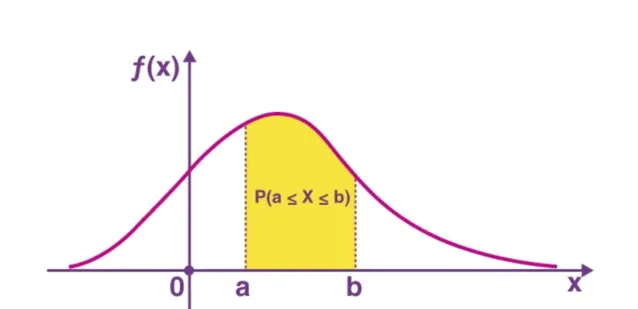
PDF。來源:https://byjus.com/maths/probability-density-function/
CDF:累積分布函式
返回隨機變量 X 取小於或等於 x 的值的機率。

CDF(指數分布的累積分布函式)。來源:https://en.wikipedia.org/wiki/Cumulative_distribution_function
3. 離散分布
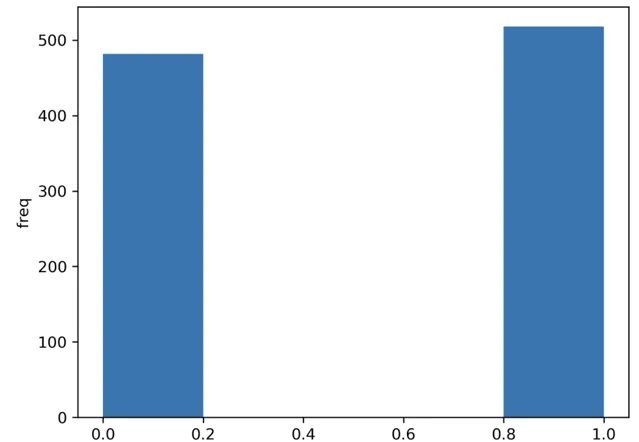
白努利分布
我們只有一個試驗(只有一個觀察結果)和兩個可能的結果。例如,拋硬幣。
我們有一個真的(1)的結果和一個假的(0)的結果。假設我們接受正面為真(我們可以選擇正面為真或成功)。那麽,如果正面朝上的機率是 ,相反情況的機率就是 。
import seaborn as snsfrom scipy.stats import bernoulli# 單一觀察值 # 生成數據 (1000 points, possible outs: 1 or 0, probability: 50% for each)data = bernoulli.rvs(size=1000,p=0.5)# 繪制圖形ax = sns.distplot(data_bern,kde=False,hist_kws={"linewidth": 10,'alpha':1})ax.set(xlabel='Bernouli', ylabel='freq')
二項式分布
白努利分布是針對單個觀測結果的。多個白努利觀測結果會產生二項式分布。例如,連續拋擲硬幣。
試驗是相互獨立的。一個嘗試的結果不會影響下一個。
二項式分布可以表示為 。 是試驗次數, 是成功的機率。
讓我們進行一個實驗,我們連續拋擲一枚公平的硬幣 20 次。
import matplotlib.pyplot as pltfrom scipy.stats import binomn = 20 # 實驗次數p = 0.5 # 成功的機率r = list(range(n + 1)) # the number of success# pmf值pmf_list = [binom.pmf(r_i, n, p) for r_i in r ]# 繪圖plt.bar(r, pmf_list)plt.show()

它看起來像正態分布,但請記住這些值是離散的。
現在這次,你有一枚欺詐硬幣。你知道這個硬幣正面向上的機率是 0.7。因此,p = 0.7。

帶有偏差硬幣的二項式分布
該分布顯示出成功結果數量增加的機率增加。
: 成功的機率 : 實驗次數 : 失敗的機率
均勻分布
所有結果成功的機率相同。擲骰子,1 到 6。

data = np.random.uniform(1, 6, 6000)
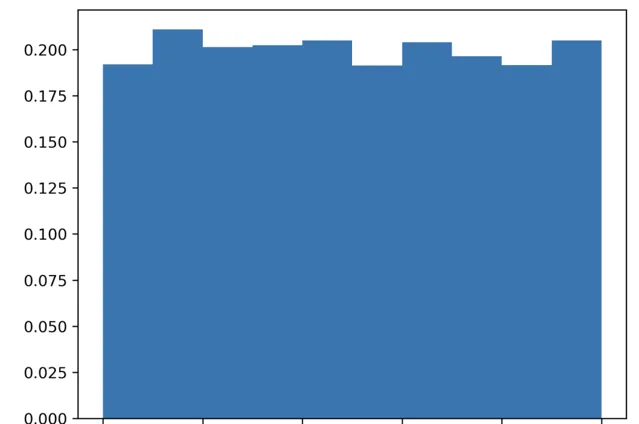
擲 6000 次。
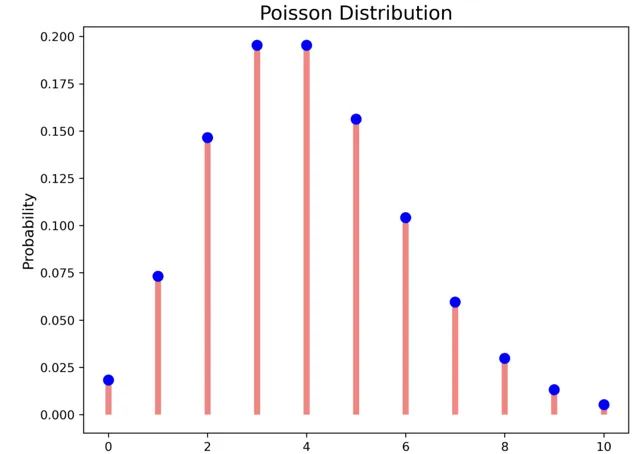
Poisson 分布
它是與事件在給定時間間隔內發生頻率相關的分布。
, 是在指定時間間隔內預期發生的事件次數。它是在該時間間隔內發生的事件的已知平均值。 是事件在指定時間間隔內發生的次數。如果事件遵循卜瓦松分布,則:
在卜瓦松分布中,事件彼此獨立。事件可以發生任意次數。兩個事件不能同時發生。
如每 60 分鐘接到 4 個電話。這意味著 60 分鐘內通話的平均次數為 4。讓我們繪制在 60 分鐘內接到 0 到 10 個電話的機率。
import matplotlib.pyplot as pltfrom scipy.stats import poissonr = range(0,11) # 呼叫次數lambda_val = 4 # 均值# 機率值data = poisson.pmf(r, lambda_val)# 繪圖fig, ax = plt.subplots(1, 1, figsize=(8, 6))ax.plot(r, data, 'bo', ms=8, label='poisson')plt.ylabel("Probability", fontsize="12")plt.xlabel("# Calls", fontsize="12")plt.title("Poisson Distribution", fontsize="16")ax.vlines(r, 0, data, colors='r', lw=5, alpha=0.5)
4. 連續分布
正態分布
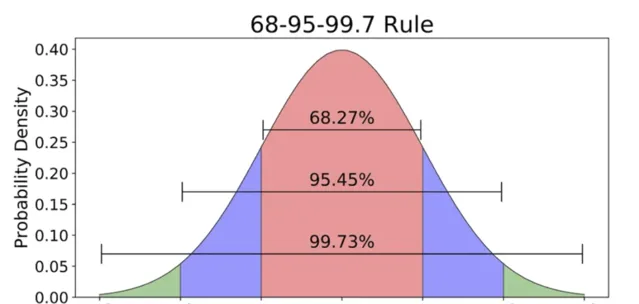
最著名和最常見的分布(也稱為高斯分布),是一種鐘形曲線。它可以透過均值和標準差定義。正態分布的期望值是均值。
曲線對稱。均值、中位數和眾數相等。曲線下總面積為 1。
大約 68%的值落在一個標準差範圍內。~95% 落在兩個標準差範圍內,~98.7% 落在三個標準差範圍內。
import scipymean = 0standard_deviation = 5x_values = np. arange(-30, 30, 0.1)y_values = scipy.stats.norm(mean, standard_deviation)plt.plot(x_values, y_values. pdf(x_values))

正態分布的機率密度函式為:
是均值, 是常數, 是標準差。
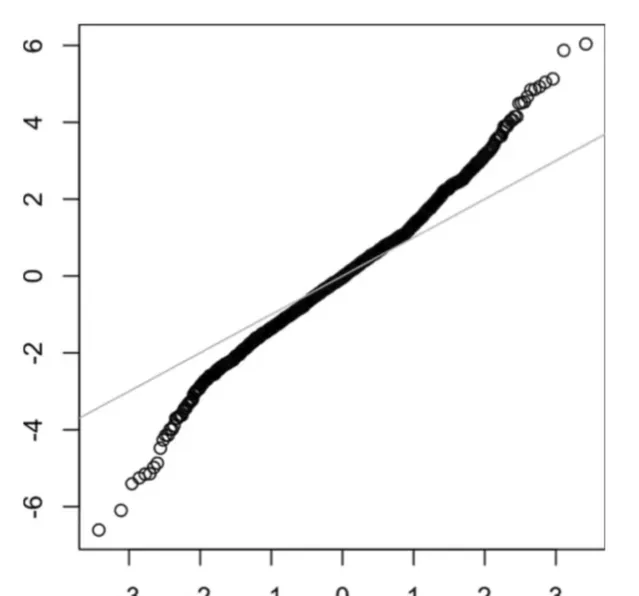
QQ 圖
我們可以使用 QQ 圖來直觀地檢查樣本與正態分布的接近程度。
計算每個數據點的 z 分數並對其進行排序,然後在 y 軸上表示它們。X 軸表示值的排名的分位數。
這個圖上的點越接近對角線,分布就越接近正態分布。
import numpy as npimport statsmodels.api as smpoints = np.random.normal(0, 1, 1000)fig = sm.qqplot(points, line ='45')plt.show()

長尾分布
尾巴是分布的長而窄的部份,離群值就位於其中。當一側尾巴不同於另一側時,就稱為偏斜。下圖是長尾分布的 QQ 圖。
import matplotlib.pyplot as pltfrom scipy.stats import skewnormdef generate_skew_data(n: int, max_val: int, skewness: int): # Skewnorm function random = skewnorm.rvs(a = skewness,loc=max_val, size=n) plt.hist(random,30,density=True, color = 'red', alpha=0.1) plt.show()generate_skew_data(1000, 100, -5) # negative (-5)-> 左偏分布

generate_skew_data(1000, 100, 5) # positive (5)-> 右偏分布

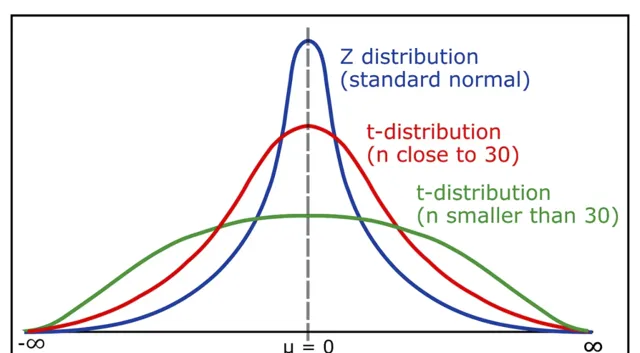
學生 t 檢驗分布
正態但有尾(更厚、更長)。
t 分布和 z 分布。來源:https://www.geeksforgeeks.org/students-t-distribution-in-statistics/
t 分布是具有較厚尾部的正態分布。如果可用數據較少(約 30 個),則使用 t 分布代替正態分布。
在 t 分布中,自由度變量也被考慮在內。根據自由度和置信水平在 t 分布表中找到關鍵的 t 值。這些值用於假設檢驗。
t 分布表情移步: https://www.sjsu.edu/faculty/gerstman/StatPrimer/t-table.pdf。
對數正態分布
隨機變量 X 的對數服從正態分布的分布。
import numpy as npimport matplotlib.pyplot as pltfrom scipy import statsX = np.linspace(0, 6, 1500)std = 1mean = 0lognorm_distribution = stats.lognorm([std], loc=mean)lognorm_distribution_pdf = lognorm_distribution.pdf(X)fig, ax = plt.subplots(figsize=(8, 5))plt.plot(X, lognorm_distribution_pdf, label="μ=0, σ=1")ax.set_xticks(np.arange(min(X), max(X)))plt.title("Lognormal Distribution")plt.legend()plt.show()
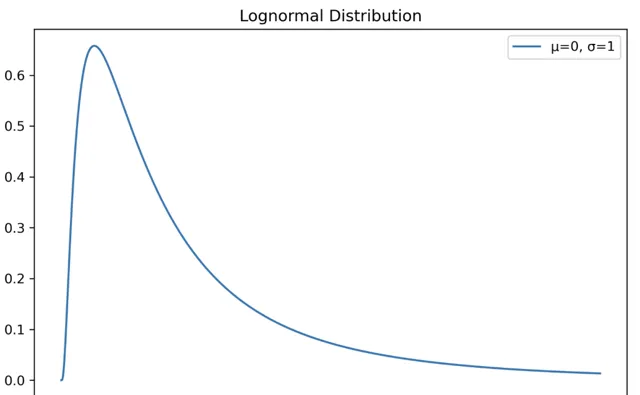
指數分布
我們在 Poisson 分布中研究了在一定時間間隔內發生的事件。在指數分布中,我們關註的是兩個事件之間經過的時間。如果我們把上面的例子倒過來,那麽兩個電話之間需要多長時間?
因此,如果 X 是一個隨機變量,遵循指數分布,則累積分布函式為:
是均值, 是常數。
from scipy.stats import exponimport matplotlib.pyplot as pltx = expon.rvs(scale=2, size=10000) # 2 calls# 繪圖plt.hist(x, density=True, edgecolor='black')
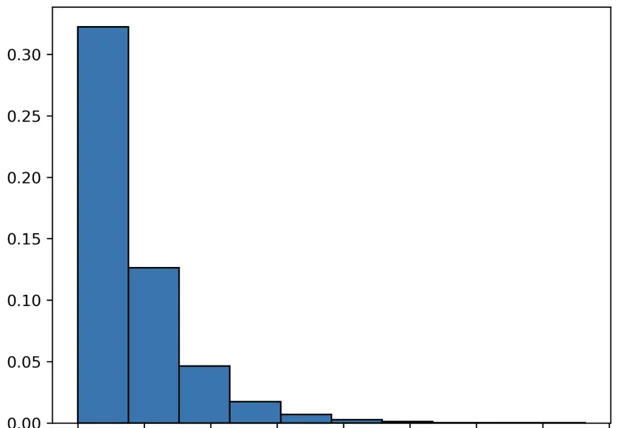
x 軸表示時間間隔的百分比
韋伯分布
它是指時間間隔是可變的而不是固定的情況下使用的指數分布的擴充套件。在 Weibull 分布中,時間間隔被允許動態變化。
是形狀參數,如果是正值,則事件發生的機率隨時間而增加,反之亦然。 是尺度參數。
import matplotlib.pyplot as pltx = np.arange(1,100.)/50.def weib(x,n,a): return (a / n) * (x / n)**(a - 1) * np.exp(-(x / n)**a)count, bins, ignored = plt.hist(np.random.weibull(5.,1000))x = np.arange(1,100.)/50.scale = count.max()/weib(x, 1., 5.).max()plt.plot(x, weib(x, 1., 5.)*scale)plt.show()å

Gamma 分布
指與第 n 個事件發生所需的時間有關的分布,而指數分布則與首次事件發生的時間有關。
import numpy as npimport scipy.stats as statsimport matplotlib.pyplot as plt#Gamma distributionsx = np.linspace(0, 60, 1000)y1 = stats.gamma.pdf(x, a=5, scale=3)y2 = stats.gamma.pdf(x, a=2, scale=5)y3 = stats.gamma.pdf(x, a=4, scale=2)# plotsplt.plot(x, y1, label='shape=5, scale=3')plt.plot(x, y2, label='shape=2, scale=5')plt.plot(x, y3, label='shape=4, scale=2')#add legendplt.legend()#display plotplt.show()
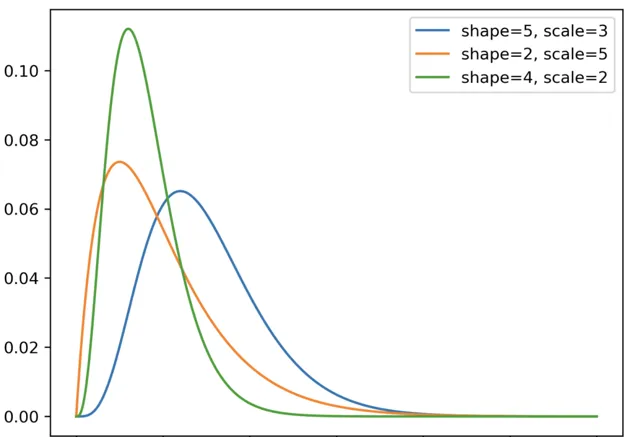
Gamma 分布。X 軸表示隨機變量 X 可能取到的潛在值,Y 軸表示分布的機率密度函式(PDF)值
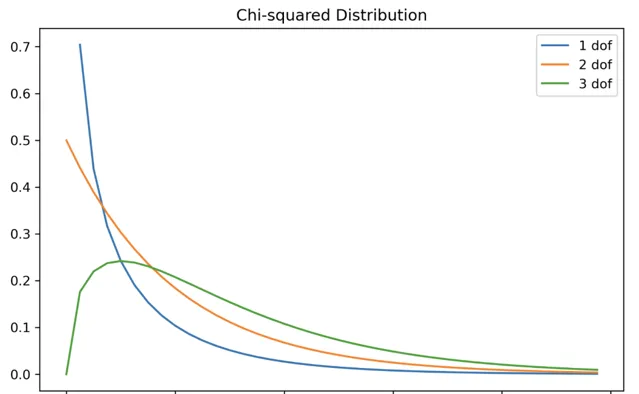
Gamma 分布
它用於統計檢驗。這通常在實際分布中不會出現。
# x軸範圍0-10,步長0.25X = np.arange(0, 10, 0.25)plt.subplots(figsize=(8, 5))plt.plot(X, stats.chi2.pdf(X, df=1), label="1 dof")plt.plot(X, stats.chi2.pdf(X, df=2), label="2 dof")plt.plot(X, stats.chi2.pdf(X, df=3), label="3 dof")plt.title("Chi-squared Distribution")plt.legend()plt.show()
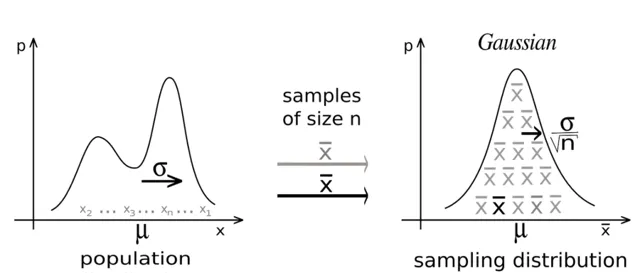
中央極限定理
當我們從人群中收集足夠大的樣本時,樣本的平均值將具有正態分布,即使人群不是正態分布。
我們可以從任何分布(離散或連續)開始,從人群中收集樣本並記錄這些樣本的平均值。隨著我們繼續采樣,我們會註意到平均值的分布正在慢慢形成正態分布。
加入知識星球【我們談論數據科學】
600+小夥伴一起學習!











