
KubeAdmiral v1.0.0 的釋出源於社群和開發人員在過去一年中取得的成就,感謝所有參與此版本的貢獻者。
來源 | KubeWharf 社群
計畫 | https://github.com/kubewharf/kubeadmiral
KubeAdmiral 是字節跳動於 2023 年 7 月正式開源的多雲多集群管理引擎,它孵化於字節跳動內部,從上線至今一直 強力支撐 抖音、今日頭條等大規模業務 的平穩執行,目前管理著超過 21 萬台機器、超過 1000 萬 Pod。
自正式開源以來,KubeAdmiral 自身也經歷了不斷發展和完善,在系統功能、擴充套件性、穩定性和執行效率均有大幅提升,也吸引了業界終端使用者的使用和貢獻。因此,我們相信 KubeAdmiral 已經準備好在生產環境落地,並很高興地宣布 1.0.0 版本正式釋出。
0 1
背景
多集群業務背景、KubeAdmiral 在字節的演進
在字節跳動內部,業務的高速發展促使集團在全球多個地區建設了大規模的機房,受限於單集群規模,研發團隊在每個機房都部署了多個集群。同時,字節跳動也 采購了多家雲廠商的公有雲資源,多雲架構進一步導致了多集群的現狀。
這種私有雲+多朵公有雲的資源配置情況,使得集群 橫跨物理機、裸金屬、虛擬機器等基礎設施, 不同雲廠商的標準各異,給運維增加了極大的復雜性。
同樣的, 出於隔離和安全的考慮,字節跳動內部各業務線獨占集群,業務和 集群深度繫結,並因此造成了集群資源孤島。 SRE 在營運資源上需要深度感知業務和集群,並在集群之間為套用人肉分配資源,最終導致資源在各個業務線之間的周轉慢、自動化效率低以及部署率不夠理想。
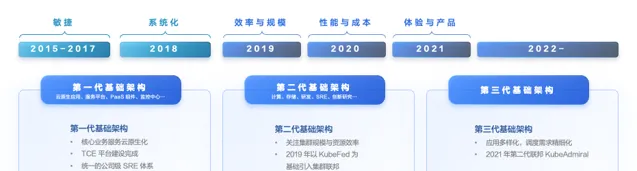
面對上述因多集群管理帶來的挑戰,字節跳動基礎架構團隊在 2019 年以社群 KubeFed V2 為基礎開啟集群聯邦的建設。但在具體落地時,發現 KubeFed 存在以下問題,並不能滿足生產環境的要求:
資源利用率低 :KubeFed 的副本排程策略 RSP 只能為每個成員集群設定靜態權重,無法靈活應對集群資源的變化,導致不同成員集群的部署水位不均;
變更不夠平滑 :擴縮容時經常出現例項分布不均的現象,導致容災能力下降;
排程語意局限 :只對無狀態類資源有較好的支持,對於有狀態服務、作業等多樣化的資源支持不足,排程擴充套件性差;
接入成本高 :需要透過建立聯邦物件進行分發,不相容原生API,使用者和上層平台需要完全改變使用習慣。
隨著架構的演進, 基礎架構團隊 對於效率、規模、效能與成本提出了更高的要求;同時隨著在離線融合,儲存和機器學習進一步雲原生化,支持相應場景的任務跨集群編排排程能力的需求愈發突出。
在上述背景下,我們在 2021 年底基於 KubeFed v2 研發了新一代集群聯邦系統 KubeAdmiral,重點包括相容原生 API、豐富排程策略和擴充套件能力、支持混合雲邊一體的超大規模多雲多集群套用編排排程能力。
02
計畫介紹
架構、核心功能
KubeAdmiral 命名引申自 Admiral(讀音[ˈædm(ə)rəl]),本意為艦隊司令,加上 Kube(rnetes) 字首,寓意該工具具有強大的 Kubernetes 多集群編排排程能力。
計畫架構
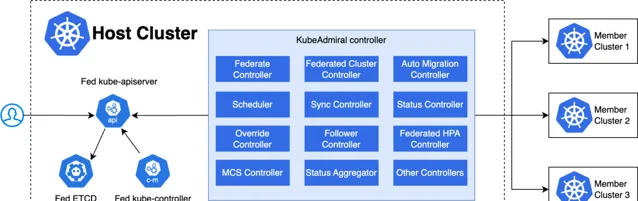
KubeAdmiral 控制面執行在 Host 集群中,包括以下元件:
Fed ETCD: 儲存聯邦層 Kubernetes 資源;
Fed Kube Apiserver: 原生Kubernetes API Server,聯邦層 Kubernetes 資源物件的唯一操作入口;
Fed Kube Controller Manager: 原生 Kubernetes 控制器,但只按需開啟部份controller,比如 namespace controller 和 gc controller,用於完成資源的垃圾回收工作;
KubeAdmiral Controller: KubeAdmiral 自研元件,為整個系統提供核心控制邏輯,完成諸如成員集群管理,資源排程與分發,故障遷移,狀態匯聚等核心功能。
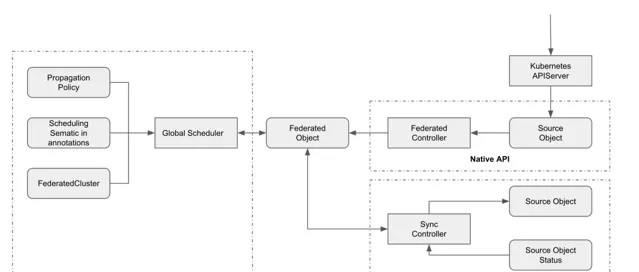
KubeAdmiral Controller 由排程器和各種控制器組成,下面列出了幾個核心的元件:
Federated Cluster Controller: 監聽 FederatedCluster 物件,負責管理成員集群的生命周期,包括成員集群的添加,移除,狀態采集等;
Federate Controller: 監聽 Kubernetes 資源,並為每個單獨的資源物件建立 FederatedObject 物件;
Scheduler: 負責把資源排程到成員集群中,在副本排程場景也負責計算每個集群中應得的副本;
Sync Controller: 監聽 FederatedObject 物件,負責將聯邦資源分發到各個成員集群中;
Status Controller: 負責采集聯邦下發到各個成員集群裏的資源的狀態。
核心功能
KubeAdmiral v1.0.0 版本支持如下核心功能:
多集群統一管理
支持納管公有雲服務商 Kubernetes 集群,如火山引擎、阿裏雲、華為雲等;
支持納管私有雲廠商 Kubernetes 集群;
支持納管使用者自建 Kubernetes 集群。
多集群套用分發
套用型別相容
Kubernetes 原生資源,如 Deployment、StatefulSet、ConfigMap 等;
CRD 資源,支持自訂狀態欄位收集、啟用副本模式排程等;
Helm Chart。
跨集群排程模式
多集群復制分發;
靜態權重副本模式分發;
動態權重副本模式分發。
集群選擇方式
指定成員集群;
所有成員集群;
集群標簽選擇。
關聯資源跟隨分發
內建跟隨資源,如工作負載參照 ConfigMap、Secret 等;
指定跟隨資源,工作負載可透過標簽指定跟隨資源,如 Service、Ingress 等。
重排程策略配置
支持關閉/開啟重排程行為;
支持配置重排程觸發條件,如部署策略語意修改、成員集群添加等。
存量單集群資源無縫接管
差異化策略覆寫成員集群資源配置
封裝覆寫語法: 包括: Image、Command、Args、Labels、Annotations 等。
資源狀態采集
使用者可以自訂資源狀態采集欄位;
支持部份資源的成員集群資源的狀態聚合到原生資源。
故障遷移
套用副本無法排程故障自動遷移
套用故障副本恢復遷回
集群故障套用手動驅逐;
套用故障跨集群自動遷移。
跨雲/集群彈性伸縮
支持套用副本在多集群場景下的 HPA 彈性伸縮能力;
相容原生及自訂 HPA 資源。
03
計畫特點
Kubernetes 原生支持
KubeAdmiral 提供符合 Kubernetes 單集群使用者使用習慣的設計,使用者可以透過 Kubernetes API 管理和操作Kubernetes原生資源。使用者建立原生資源(如Deployment)後,由 Federate Controller 將其自動轉化為聯邦內部物件(FederatedObject)供其他 controller 使用。
同時,KubeAdmiral 也提供無縫接管存量單集群資源的能力,可以幫助使用者平滑地將現有的單集群部署轉變為多集群架構,以實作更高的可延伸性和彈性。
全域資源狀態匯聚
在單 Kubernetes 集群環境中,原生的 controller 負責更新資源的狀態(status),這為使用者提供了關於部署和健康狀態等關鍵資訊。然而,在多集群部署中,這些狀態資訊分散於不同的集群,導致使用者在獲取全域檢視時面臨碎片化和運維效率低下的挑戰。
KubeAdmiral 透過以下最佳化功能解決了這一問題,提供了全面的多集群資源狀態管理和監控:
集中式狀態采集 :KubeAdmiral 的 Status Controller 允許使用者指定關心的自訂資源欄位,聯集中收集各成員集群中的資源狀態,這些狀態資訊被匯總至一個統一的 CollectedStatus 物件;
全域狀態聚合 :Status Aggregator 負責將來自不同成員集群的資源狀態進行綜合和協調,然後將聚合後的狀態資訊反饋至原生資源,讓使用者無需感知多集群拓撲,就可以一目了然地觀測到資源在整個聯邦中的狀態;
即時狀態監控 :KubeAdmiral 持續監控所有成員集群的資源狀態,提供即時的執行狀態、可用性和健康狀態更新,使使用者能夠及時獲取資源的最新情況;
故障檢測與恢復 :利用狀態監控,KubeAdmiral 能夠迅速辨識資源故障或異常,自動執行故障轉移等恢復措施,以維護集群的穩定性和可用性;
統一檢視和報告 :使用者現在可以在單一界面上檢視跨集群的資源狀態,並利用生成的報告來支持決策制定和深入分析。
豐富的排程能力
KubeAdmiral 提供豐富的開箱即用的排程策略,包括:
靈活的排程策略 :KubeAdmiral 支持靈活的排程策略和規則定義。使用者可以根據資源需求、地理位置、成本、集群標簽、汙點、權重等因素,自訂排程策略,以滿足特定的業務需求和最佳化目標。
跨集群資源分配 :KubeAdmiral 可以根據使用者的配置和策略,在多個成員集群之間動態分配和排程工作負載。它可以根據集群的負載和資源使用情況,智慧地進行資源排程,以確保每個集群的資源得到充分利用,並避免過度或不足的資源分配。
依賴資源跟隨排程 :確保負載依賴的配置資源在同一集群中排程,簡化應用程式的部署和管理。
高效的差異化配置 :對於排程到不同集群中的資源,支持透過差異化策略進行覆寫,為了方便使用者使用,KubeAdmiral 也封裝了常見的 Overrider,包括:Image、Command、Args、Labels、Annotations 等。
KubeAdmiral 排程的語意可以透過 PropagationPolicy 物件配置:
apiVersion: core.kubeadmiral.io/v1alpha1kind: PropagationPolicymetadata:name: mypolicynamespace: defaultspec: # 提供多種集群選擇方式,最終結果取交集placement: # 手動指定集群與權重-cluster: Cluster-01preferences:weight: 40-cluster: Cluster-02preferences:weight: 30-cluster: Cluster-03preferences:weight: 40clusterSelector: # 類似Pod.Spec.NodeSelector,透過label過濾集群IPv6: "true"clusterAffinity: # 類似Pod.Spec.NodeAffinity,透過label過濾集群,語法比clusterSelector更加靈活-matchExpressions:-key: regionoperator: Invalues:-beijingtolerations: # 透過汙點過濾集群-key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"schedulingMode: Divide # 是否為副本數排程reschedulePolicy: disableRescheduling: true # 僅在首次排程,適合有狀態服務或作業類服務maxClusters: 1 # 最多可分發到多少個子集群,適合有狀態服務或作業類服務disableFollowerScheduling: false # 是否開啟依賴排程
KubeAdmiral 差異化策略可以透過 OverridePolicy 物件配置:
apiVersion: core.kubeadmiral.io/v1alpha1kind: OverridePolicymetadata: name: example namespace: defaultspec:# 最終匹配的集群是所有rule匹配集群的交集 overrideRules: - targetClusters:# 透過名稱匹配集群 clusters: - member1 - member2# 透過標簽selector匹配集群 clusterSelector: region: beijing az: zone1# 透過基於標簽的affinity匹配集群 clusterAffinity: - matchExpressions: - key: region operator: Invalues: - beijing - key: provideroperator: Invalues: - volcengine# 在匹配的集群中,使用jsonpatch語法修改第一個容器的映像 overriders: jsonpatch: - path: "/spec/template/spec/containers/0/image"operator: replacevalue: "nginx:test" image: - imagePath: "/spec/templates/0/container/image"operations: - imageComponent: Registryoperator: addIfAbsentvalue: cluster.io - targetClusters: clusters: - member1 overriders: command: - containerName: "server-1"operator: appendvalue: - "/bin/sh" - "-c" - "sleep 10s" - containerName: "server-2"operator: overwritevalue: - "/bin/sh" - "-c" - "sleep 10s" - containerName: "server-3"operator: deletevalue: - "sleep 10s" - targetClusters: clusters: - member2 overriders: args: - containerName: "server-1"operator: appendvalue: - "-v=4" - "--enable-profiling" - targetClusters: clusters: - kubeadmiral-member-1 overriders: labels: - operator: addIfAbsentvalue: app: "chat" - operator: overwritevalue: version: "v1.1.0" - operator: deletevalue: action: ""
套用故障遷移
KubeAdmiral 可以幫助使用者實作多集群套用的故障遷移,確保應用程式的連續性和可用性。
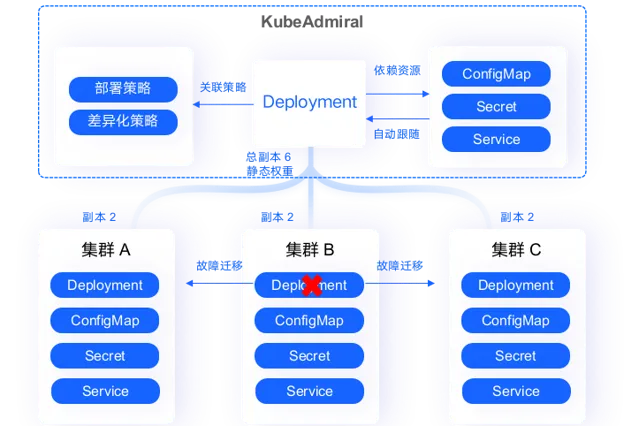
對於副本排程的資源,KubeAdmiral 透過聯邦排程計算出每個成員集群的應得副本數,並將副本數位段覆蓋後下發到各成員集群;
資源下發後,透過各成員集群的 kube-scheduler 把資源對應的pod分配給相應的node。
資源下發後,有時會出現因為節點下線、資源不足、節點親和性無法滿足等等情況造成單集群排程失敗的情況,如果不做處理,業務可用例項會低於預期。KubeAdmiral 提供排程失敗自動遷移的功能,開啟後可以辨識成員集群中不可排程的副本並遷移到可容納多余副本的集群,實作多集群資源周轉。
如 A、B、C 三集群相等權重分發 6 個副本,初次聯邦排程後每個集群分到 2 個副本。如果 C 集群中的 2 個副本在單集群排程失敗,則 KubeAdmiral 會自動將其遷移到 A 和 B 中。
當集群發生故障(不健康或失聯),或是不希望在某個集群上繼續執行工作負載(如集群下線、升級)時,KubeAdmiral 支持自動/手動進行集群套用驅逐,被驅逐的工作負載將被排程至其他健康的集群中。
排程能力可延伸
KubeAdmiral 具備可延伸的排程能力,可以有效地管理和排程大規模的多集群環境。KubeAdmiral 透過以下方式對排程能力進行擴充套件。
排程器外掛程式架構 :
KubeAdmiral 參考 kube-scheduler 的設計,提供了可拓展的排程框架,將排程邏輯抽象成 Filter、 Score、Select 和 Replica 四個步驟,並由多個相對獨立的外掛程式各自實作其在每個步驟的邏輯。 套用分發策略 PropagaionPolicy 中支持的策略都由獨立的內建排程外掛程式負責實作,各外掛程式之間互不幹擾,由排程器呼叫需要的外掛程式進行全域的編排。
排程外掛程式生態系 :
KubeAdmiral 的外掛程式生態系提供了豐富的內建外掛程式,同時也支持透過 HTTP 協定與外部外掛程式互動。使用者可以自行編寫並部署客製化的排程邏輯,滿足接入公司內部系統進行排程等需求。內建的外掛程式實作較為通用的能力,與外部外掛程式相輔相成,使用者可以以最小成本、不需要改動聯邦控制面的方式實作排程邏輯的拓展,並依賴 KubeAdmiral 強大的多集群分發能力將排程結果生效。
04
總結
在生態合作方面,KubeAdmiral 和火山引擎雲原生團隊達成合作,其分布式雲原生使用 KubeAdmiral 為核心引擎,提供多雲集群運維、多雲容災、跨雲遷移和混合部署等能力,在金融、互聯網等行業實作多場景套用。火山引擎雲原生團隊在實踐中積累的一些能力,也已經透過開源貢獻的形式反哺回社群。
KubeAdmiral v1.0.0 反映了社群和開發人員在過去一年中取得的成就,感謝所有參與此版本的貢獻者。我們非常期待更多開發者和使用者能加入到 KubeAdmiral 開源社群中,和我們一起交流和探討多雲多集群聯邦的相關話題。如需開源交流,添加字節跳動雲原生小助手,加入雲原生社群:

- END -
相關連結
[1]
[2]
[3]
[4]
關於 KubeWharf
KubeWharf 是字節跳動基礎架構團隊在對 Kubernetes 進行了大規模套用和不斷最佳化增強之後的技術結晶。這是一套以 Kubernetes 為基礎構建的分散式作業系統,由一組雲原生元件構成,專註於提高系統的可延伸性、功能性、穩定性、可觀測性、安全性等,以支持大規模多租集群、在離線混部、儲存和機器學習雲原生化等場景。
計畫地址: github.com/kubewharf










