大家好,我是程式設計師魚皮。
很多小夥伴都知道緩存的好處,從資料庫載入數據過慢時,直接上 Redis 緩存!
的確,Redis 高效能 KV 儲存是後端開發提升效能的一大利器,但是有沒有想過,如果使用姿勢不對,使用 Redis 後,效能反而會更慢呢?
今天就來盤下使用 Redis 效能變慢的幾個原因以及一些應對手段。
1、網路和通訊導致的延遲
比如我們現在要往 Redis 裏面寫入多個 key 和值:
| key | value |
|---|---|
| name | yupi |
| gender | male |
| base | shanghai |
| ... | ... |
很多同學會采取一條一條塞入的方式來完成這些鍵值對的寫入,如圖:
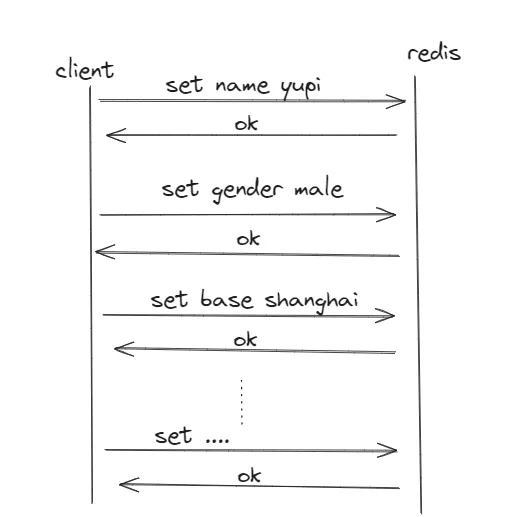
可以看到,下一條數據的寫入需要等待上一條的返回,這個等待時間除了命令的處理時間, 其實網路通訊的時間也占據了很大一部份 。
就好比我們網購了 5 件衣服,都送到了快遞驛站,此時我們是去驛站一件一件拿回家快呢?還是 5 件衣服一起拿快呢?
答案顯而易見,肯定是一起拿快,如果一件一件的拿,很多時間都消耗在路上了!
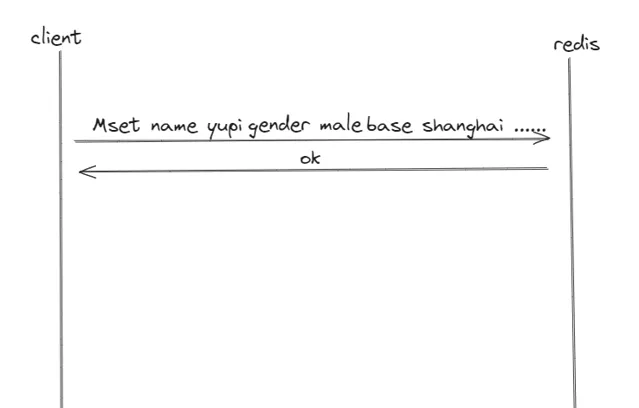
同理,對於上面 Redis 這種場景,我們需要使用 MSET 這樣的聚合命令,透過 批次操作 來提升效能。如圖,一趟搞定!
我本地寫了段指令碼來實際測試了一下,對比使用 for 迴圈插入 2W 條記錄,和利用 mset 命令一次性插入 2W 條數據的耗時。
結果,for 迴圈花了 5472 毫秒,mset 花了126 毫秒,它們之間差了 40 多倍 !
由此可見,這種聚合命令在某些時候下,提升效能的效果還是十分可觀的!
類似的聚合命令還有很多,比如 MGET、MHSET、HMGET 等等。
除此之外,也可以使用 Pipeline 一次性打包多條命令執行,更進階的還有 lua 指令碼,這裏就不多展開了。
2、忽略復雜度高的命令
很多同學都預設 Redis 很快,於是用起 Redis 沒啥負擔,就是幾行程式碼的事情嘛~
其實像一些普通命令,比如 SET 或 LPUSH 這種問題確實不大。
用我的一台小破機器測試,一條 set 命令消耗的時間在 10 毫秒以內。
但是有一些命令卻不是,比如 SORT、LREM、SUNION。舉個例子,比如有兩個大集合,存了很多很多數據,此時你要取它們的交集,想想是不是很耗時?
我在 200W 條數據量的情況下使用 SUNION 命令測試,耗時近 5000 毫秒,跟正常的一條 set 的10 毫秒可是差了 500 倍!
而且需要註意,Redis 執行命令是單執行緒的!如果你前面執行了一個比較耗時的命令,假設此時並行度很高,那麽就會有一堆命令排隊等著前面耗時的那條命令,這個時候就會產生阻塞。
想想看,本來 redis 能處理 500 條命令,現在只能處理一條了,這種情況頻繁一點,在高峰期對業務的影響就會很大。因此在生產環境中,需要慎重的使用這些命令,仔細評估集合的數據量,如果數據量不大,那麽才能使用。
對了,這裏需要特別強調一個命令:
keys
,很多生產環境的問題都是因為這條命令導致的。我對這個命令記憶尤其深刻,因為之前有個同事因為執行了這個命令導致線上服務雪崩了!
這個命令它會掃描 db 所有 key ,如果比較耗時,特別是當前 reids 有很多 key 的情況下,很容易造成服務的崩潰,從而引發雪崩!
做個狠點的測試,插入 1 億條數據,然後執行下 keys 來看看到底得耗時多久!開始!
10分鐘過去了....
20分鐘過去了...
???中間沒忍住想利用視覺化工具開啟看看已經插入了多少條,然後它崩了!!
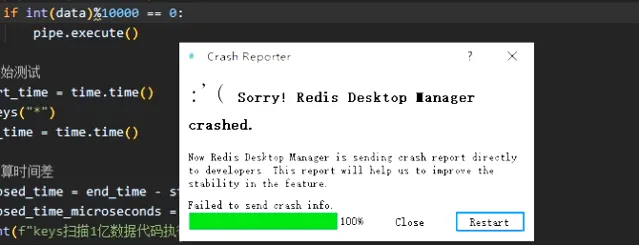
行吧,1 億數據確實有點多,我放棄,不插入了。
重新開機了 redis desktop manager 一看,已經插入了2900w條了

於是在 2900w 條數據時,執行 keys 命令,消耗了大概 50 多秒。
在執行 keys 命令的時候,哪怕執行一個普通的 get 命令,也要一直被阻塞。有的時候,單次查詢慢,不一定是查詢程式碼的問題。
所以,建議在生產上禁用這類命令,防止一些同學誤用產生重大事故!
3、key的集中過期
除了 keys 的問題,之前在生產環境還遇到一個莫名其妙的 Redis 問題。
當時排查的時候,把我頭都快搞禿了!
當時遇到的問題就是 key 的集中過期 。
Redis 淘汰鍵值對有兩種方式:
惰性淘汰。當命令請求到這個 key 時,看下它過期沒,如果過期則清理
主動淘汰。Redis 每 100 毫秒會隨機掃描 20 個 key,刪除其中過期的 key,如果過期率超過 25 % ,則會繼續這個過程,過期率超過 25 % ,則會繼續這個過程,過期率超過 25 % ,則會繼續這個過程。沒錯,會一直重復這個步驟,直到過期率低於 25 % 或者累計耗時超過 25 毫秒才會終止這個步驟。
就是這個主動淘汰機制,使得如果有大批的數據在同一時間到期, 那麽主要淘汰每次時長都要拉滿,這其實就等於主動給 Redis 加壓!
好家夥,這種時間的拉長在慢日誌裏面是查不到的,因為它不是因為命令本身的耗時長,所以當時排查了非常久,讓我摸不住頭腦的同時,也讓我摸不到頭發了。
所以在生產上要避免一大堆 key 同時到期,我們在設定過期時間的時候, 可以增加一些隨機數來打散它們 。比如下列程式碼:
expire(key, time + random(600))
4、bigkey
最後還有一個非常重要的問題點,也是大夥在使用上需要著重關註的點,就是 bigkey 問題。
可以理解為目前的 key 所占的記憶體比較大,可能是它的值比較多,或者每個值占用的記憶體比較多。
就好比一個刪除(DEL)操作,在我們眼裏它不像兩個集合交集這麽復雜,但是在 bigkey 場景下,它可能就會出現問題!
我們都知道 Redis 占用記憶體資源,而記憶體是有限的,因此如果有不需要的記憶體需要及時釋放,所以就會 DEL 某個 key 來釋放記憶體,然後這個 key 又是個 bigkey ,因此釋放的記憶體比較大,這樣一來耗時就會比較久,所以一個簡單的 DEL 命令都可能會在高峰期造成阻塞。
就好比咱們平日每天扔垃圾,早上出門把昨晚的垃圾一提一扔,輕松!
假設你假期在家蝸居了 7 天,點了 7 天的外賣,然後你這個懶鬼一點都不想出門,垃圾堆著就多了,此時長假結束,你要出門扔垃圾了,請問你能一趟扔完嗎?
針對刪除的命令,在 Redis 4.0 之後,可以透過 unlink 代替 del,unlink 釋放記憶體是放在後台執行緒執行的,不會阻塞主執行緒,6.0 版本開啟 lazy-free 後,釋放記憶體都是放在後台執行緒執行。
不過以上僅僅只是刪除的最佳化,在業務上我們還是需要避免 bigkey 的產生,對於一些已有的 bigkey,要及時做拆分。
以上就是本期分享,希望大家使用 Redis 的時候,多一個心眼,避免事故的發生~
👇🏻 點選下方閱讀原文,獲取魚皮往期編程幹貨。
往期推薦











