背景
GeoHash 基本原理介紹
GeoHash如何套用到這個問題當中?
遺留問題
背景
不知道大家是否思考過一個問題,在一些場景下(如大家在使用高德地圖打車的時候,鄰近的司機是如何知道你在他的附近並將你的打車通知推播給他去接單的?)是如何實作的?
一般來講,大家也許會想到,首先肯定需要知道每位乘客的經緯度(lng,lat),也即是二維座標(當然這是在絕對理想的情況,不考慮上下坡度)。
而在知道了經緯度之後,一個暴力簡單且容易想到的思路就是將經緯度這個 「二元組」 都存放在一個 「陣列」 當中,然後當我們需要拿到離我們規定範圍內的使用者(如獲取當前位置方圓百米內正在打車的乘客),我們就可以去遍歷維護的那個陣列,以此去判斷陣列中的經緯度與自己所在經緯度的距離,然後判斷是否在範圍內。
顯然這種方法一定是能夠達到目的的,
但是值得註意的點是,維護的數據量一般來講是海量的
,因此如果每次都需要遍歷所有數據去進行計算,那這計算量以及儲存量目前是無法滿足的。那如何在此基礎上去最佳化效能呢??那麽這個內容就是本篇文章主要想探討的問題......
GeoHash基本原理介紹
首先我想先介紹一下GeoHash這種演算法 「基本原理」 ,再討論如何進行套用。
對於每一個座標都有它的
經緯度(lng,lat)
,而GeoHash的原理就是將經緯度先透過一個
二分
的思路拿到一個
二進制陣列
的字串,然後再透過
base32編碼
去進行壓縮儲存。
舉一個例子,比如經緯度為(116.3111126,40.085003),對其進行二分步驟如下:
經度步驟:
| bit | left | mid | right |
|---|---|---|---|
| 1 | -180 | 0 | 180 |
| 1 | 0 | 90 | 180 |
| 0 | 90 | 135 | 180 |
| 1 | 90 | 112.5 | 135 |
| 0 | 112.5 | 123.75 | 135 |
| 0 | 112.5 | 118.125 | 123.75 |
| 1 | 112.5 | 115.3125 | 118.125 |
| 0 | 115.3125 | 116.71875 | 118.125 |
| 1 | 115.3125 | 116.015625 | 116.71875 |
| 0 | 116.015625 | 116.3671875 | 116.71875 |
| 1 | 116.015625 | 116.19140625 | 116.3671875 |
| 1 | 116.19140625 | 116.279296875 | 116.3671875 |
| 0 | 116.279296875 | 116.323242188 | 116.3671875 |
| 1 | 116.279296875 | 116.301269532 | 116.323242188 |
| 0 | 116.301269532 | 116.31225586 | 116.323242188 |
緯度步驟:
| bit | left | mid | right |
|---|---|---|---|
| 1 | -90 | 0 | 90 |
| 0 | 0 | 45 | 90 |
| 1 | 0 | 22.5 | 45 |
| 1 | 22.5 | 33.75 | 45 |
| 1 | 33.75 | 39.375 | 45 |
| 0 | 39.375 | 42.1876 | 45 |
| 0 | 39.375 | 40.78125 | 42.1876 |
| 1 | 39.375 | 40.078125 | 40.78125 |
| 0 | 40.078125 | 40.4296875 | 40.78125 |
| 0 | 40.078125 | 40.25390625 | 40.4296875 |
| 0 | 40.078125 | 40.166015625 | 40.25390625 |
| 0 | 40.078125 | 40.1220703125 | 40.166015625 |
| 0 | 40.078125 | 40.1000976563 | 40.1220703125 |
| 0 | 40.078125 | 40.0891113282 | 40.1000976563 |
| 1 | 40.078125 | 40.0836181641 | 40.0891113282 |
「其思路就是不斷二分,如果原本值大於mid那本bit位就是1,以此往下遞迴,最終,我們遞迴二分得到緯度方向上的二進制字串為 101110010000001,長度為 15 位」
那此時就拿到了30bit位的字串,然後就開始進行拼接
結合經度字串
110100101011010
和緯度字串
101110010000001
,我們遵循先經度後緯度的順序,逐一交錯排列,最終得到的一維字串為
11100 11101 00100 11000 10100 01001
.
然後再進行Base32編碼,主要步驟就是首先會維護一個 「0-9A-Za-z」 中32個字元的陣列,如:['a','b','1','2','3','4','5','6','7','A'...],然後再將這30位的字串每五個一組(正好覆蓋0-31的索引)去索引到指定字元以此拿到30/5=6位的base32編碼去進行儲存。
「ps:註意並不一定是必要將經緯度都二分得到15位長度,多少位都可以,只是精度越高結果也就越精確,但是算力就越大,只需在此做出權衡即可」
GeoHash如何套用到這個問題當中?
上面講到了可以透過GeoHash將經緯度轉換成bit位的字串,那麽怎麽進行套用呢,其實答案很明顯,其實如果經緯度越接近,他們的字首匹配位數也就越長,比如
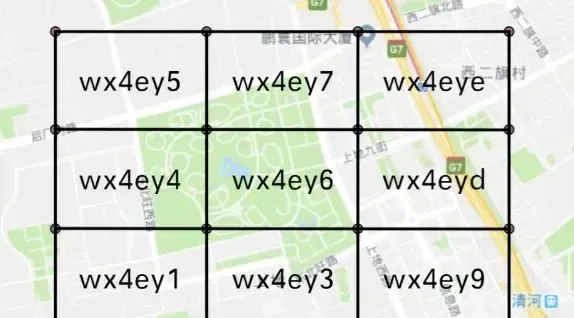
透過這個思路我們就比較容易得到我們想要的範圍內的乘客了。
遺留問題
但是其實僅僅如此是不夠的,因為一個base32其實是覆蓋了一片區域的,它並不是說僅僅代表一個精確的ip地址,那這其實就衍生出了一些問題,就比如
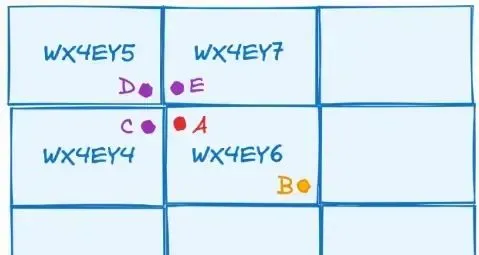
用geohash那結果顯然是AB更近,但是實際上A與B的距離比AE、AC、AD都遠。這其實是一個邊緣性的問題........後續我會更新如何去避免這種問題的出現
·END·
IT交流群
組建了程式設計師,架構師,IT從業者交流群,以
交流技術
、
職位內推
、
行業探討
為主

加小編 好友 ,備註"加群"











