掃碼關註
「
後端架構師
」,選擇
「
星標
」
公眾號
重磅幹貨,第一時間送達!
責編:架構君 | 來源:Java知音
連結:juejin.cn/post/7350228838151847976
上一篇好文:
正文
大家好,我是後端架構師。
一. 問題描述
我們在設計表結構的時候,設計規範裏面有一條如下規則:
對於可變長度的欄位,在滿足條件的前提下,盡可能使用較短的變長欄位長度。
為什麽這麽規定?我在網上查了一下,主要基於兩個方面
基於儲存空間的考慮
基於效能的考慮
網上說
Varchar(50)
和
varchar(500)
儲存空間上是一樣的,真的是這樣嗎?
基於效能考慮,是因為過長的欄位會影響到查詢效能?
本文我將帶著這兩個問題探討驗證一下
二.驗證儲存空間區別
1.準備兩張表
CREATETABLE`category_info_varchar_50` (
`id`bigint(20) NOTNULL AUTO_INCREMENT COMMENT'主鍵',
`name`varchar(50) NOTNULLCOMMENT'分類名稱',
`is_show`tinyint(4) NOTNULLDEFAULT'0'COMMENT'是否展示:0 禁用,1啟用',
`sort`int(11) NOTNULLDEFAULT'0'COMMENT'序號',
`deleted`tinyint(1) DEFAULT'0'COMMENT'是否刪除',
`create_time` datetime NOTNULLCOMMENT'建立時間',
`update_time` datetime NOTNULLCOMMENT'更新時間',
PRIMARY KEY (`id`) USING BTREE,
KEY`idx_name` (`name`) USING BTREE COMMENT'名稱索引'
) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COMMENT='分類';
CREATETABLE`category_info_varchar_500` (
`id`bigint(20) NOTNULL AUTO_INCREMENT COMMENT'主鍵',
`name`varchar(500) NOTNULLCOMMENT'分類名稱',
`is_show`tinyint(4) NOTNULLDEFAULT'0'COMMENT'是否展示:0 禁用,1啟用',
`sort`int(11) NOTNULLDEFAULT'0'COMMENT'序號',
`deleted`tinyint(1) DEFAULT'0'COMMENT'是否刪除',
`create_time` datetime NOTNULLCOMMENT'建立時間',
`update_time` datetime NOTNULLCOMMENT'更新時間',
PRIMARY KEY (`id`) USING BTREE,
KEY`idx_name` (`name`) USING BTREE COMMENT'名稱索引'
) ENGINE=InnoDB AUTO_INCREMENT=288135DEFAULTCHARSET=utf8mb4 COMMENT='分類';
2.準備數據
給每張表插入相同的數據,為了凸顯不同,插入100萬條數據
DELIMITER $$
CREATEPROCEDURE batchInsertData(IN total INT)
BEGIN
DECLARE start_idx INTDEFAULT1;
DECLARE end_idx INT;
DECLARE batch_size INTDEFAULT500;
DECLARE insert_values TEXT;
SET end_idx = LEAST(total, start_idx + batch_size - 1);
WHILE start_idx <= total DO
SET insert_values = '';
WHILE start_idx <= end_idx DO
SET insert_values = CONCAT(insert_values, CONCAT('(\'name', start_idx, '\', 0, 0, 0, NOW(), NOW()),'));
SET start_idx = start_idx + 1;
ENDWHILE;
SET insert_values = LEFT(insert_values, LENGTH(insert_values) - 1); -- Remove the trailing comma
SET @sql = CONCAT('INSERT INTO category_info_varchar_50 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';');
PREPARE stmt FROM @sql;
EXECUTE stmt;
SET @sql = CONCAT('INSERT INTO category_info_varchar_500 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';');
PREPARE stmt FROM @sql;
EXECUTE stmt;
SET end_idx = LEAST(total, start_idx + batch_size - 1);
ENDWHILE;
END$$
DELIMITER ;
CALL batchInsertData(1000000);
3.驗證儲存空間
查詢第一張表SQL
SELECT
table_schema AS"資料庫",
table_name AS"表名",
table_rows AS"記錄數",
TRUNCATE ( data_length / 1024 / 1024, 2 ) AS"數據容量(MB)",
TRUNCATE ( index_length / 1024 / 1024, 2 ) AS"索引容量(MB)"
FROM
information_schema.TABLES
WHERE
table_schema = 'test_mysql_field'
and TABLE_NAME = 'category_info_varchar_50'
ORDERBY
data_length DESC,
index_length DESC;
查詢結果
查詢第二張表SQL
SELECT
table_schema AS"資料庫",
table_name AS"表名",
table_rows AS"記錄數",
TRUNCATE ( data_length / 1024 / 1024, 2 ) AS"數據容量(MB)",
TRUNCATE ( index_length / 1024 / 1024, 2 ) AS"索引容量(MB)"
FROM
information_schema.TABLES
WHERE
table_schema = 'test_mysql_field'
and TABLE_NAME = 'category_info_varchar_500'
ORDERBY
data_length DESC,
index_length DESC;
查詢結果
4.結論
兩張表在占用空間上確實是一樣的,並無差別
三.驗證效能區別
1.驗證索引覆蓋查詢
selectnamefrom category_info_varchar_50 wherename = 'name100000'
-- 耗時0.012s
selectnamefrom category_info_varchar_500 wherename = 'name100000'
-- 耗時0.012s
selectnamefrom category_info_varchar_50 orderbyname;
-- 耗時0.370s
selectnamefrom category_info_varchar_500 orderbyname;
-- 耗時0.379s
透過索引覆蓋查詢效能差別不大
1.驗證索引查詢
select * from category_info_varchar_50 wherename = 'name100000'
--耗時 0.012s
select * from category_info_varchar_500 wherename = 'name100000'
--耗時 0.012s
select * from category_info_varchar_50 wherenamein('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗時 0.011s -0.014s
-- 增加 order by name 耗時 0.012s - 0.015s
select * from category_info_varchar_50 wherenamein('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗時 0.012s -0.014s
-- 增加 order by name 耗時 0.014s - 0.017s
索引範圍查詢效能基本相同, 增加了order By後開始有一定效能差別;
3.驗證全表查詢和排序
全表無排序
全表有排序
select * from category_info_varchar_50 orderbyname ;
--耗時 1.498s
select * from category_info_varchar_500 orderbyname ;
--耗時 4.875s
結論:
全表掃描無排序情況下,兩者效能無差異,在全表有排序的情況下, 兩種效能差異巨大;
分析原因
varchar50 全表執行sql分析
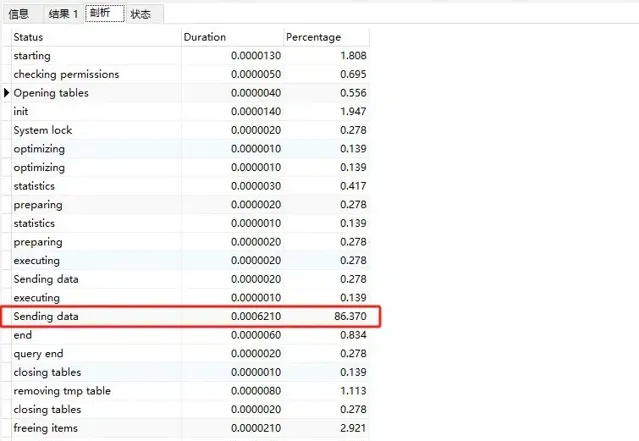
我發現86%的時花在數據傳輸上,接下來我們看狀態部份,關註Created_tmp_files和sort_merge_passes
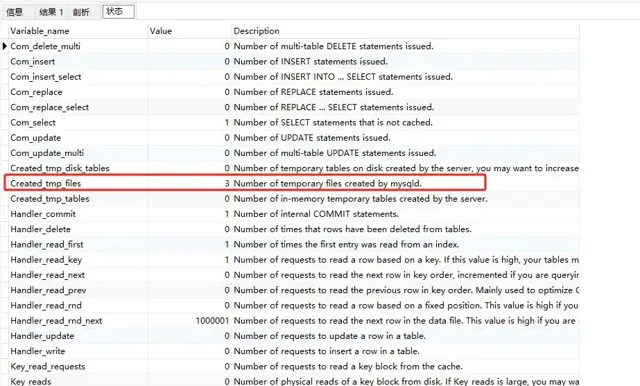
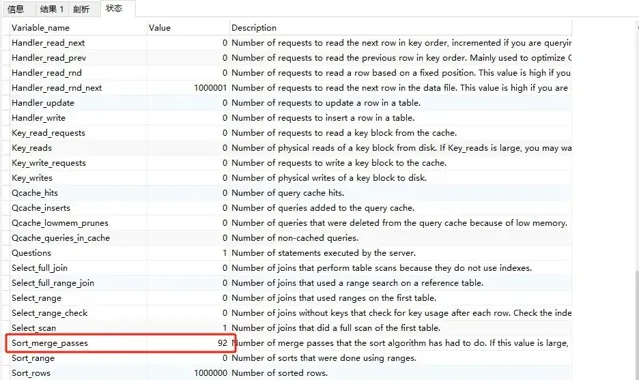
Created_tmp_files為3
sort_merge_passes為95
varchar500 全表執行sql分析
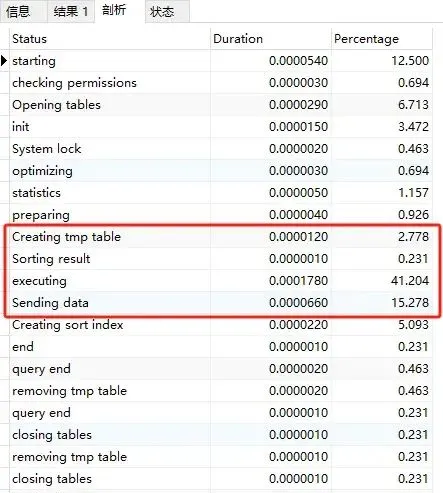
增加了臨時表排序
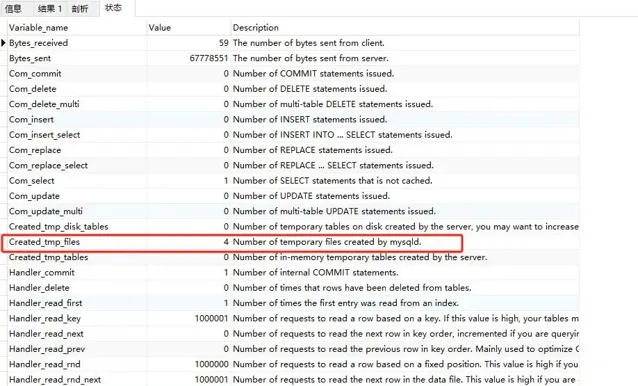
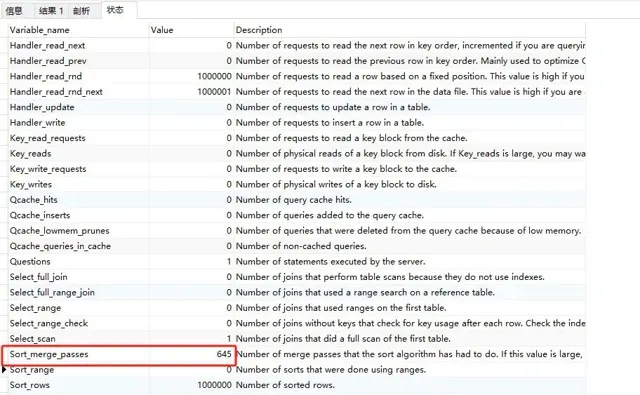
Created_tmp_files 為 4
sort_merge_passes為645
關於sort_merge_passes, Mysql給出了如下描述:
❝
Number of merge passes that the sort algorithm has had to do. If this value is large, you may want to increase the value of the sort_buffer_size.
❞其實sort_merge_passes對應的就是MySQL做歸並排序的次數,也就是說,如果sort_merge_passes值比較大,說明sort_buffer和要排序的數據差距越大,我們可以透過增大sort_buffer_size或者讓填入sort_buffer_size的鍵值對更小來緩解sort_merge_passes歸並排序的次數。
四.最終結論
至此,我們不難發現,當我們最該欄位進行排序操作的時候,Mysql會根據該欄位的設計的長度進行記憶體預估, 如果設計過大的可變長度, 會導致記憶體預估的值超出sort_buffer_size的大小, 導致mysql采用磁盤臨時檔排序,最終影響查詢效能。
你還有什麽想要補充的嗎?
最後給大家推薦一個ChatGPT 4.0國內網站,是我們團隊一直在使用的,我們對接是OpenAI官網的帳號,給大家打造了一個一模一樣ChatGPT,很多粉絲朋友現在也都透過我拿這種號,價格不貴,關鍵還有售後。
一句話說明:用官方一半價格的錢,一句話說明:用跟官方 ChatGPT4.0 一模一樣功能,無需魔法,無視封號,不必擔心次數不夠。
最大優勢:可實作會話隔離!突破限制:官方限制每個帳號三小時可使用40次4.0本網站可實作次數上限之後,手動切換下一個未使用的帳號【相當於一個4.0帳號,同享受一百個帳號輪換使用許可權】
最後,再次推薦下我們的AI星 球 :
為了跟上AI時代我幹了一件事兒,我建立了一個知識星球社群:ChartGPT與副業。想帶著大家一起探索 ChatGPT和新的AI時代 。
有很多小夥伴搞不定ChatGPT帳號,於是我們決定,凡是這三天之內加入ChatPGT的小夥伴,我們直接送一個正常可用的永久ChatGPT獨立帳戶。
不光是增長速度最快,我們的星球品質也絕對經得起考驗,短短一個月時間,我們的課程團隊釋出了 8個專欄、18個副業計畫 :
簡單說下這個星球能給大家提供什麽:
1、不斷分享如何使用ChatGPT來完成各種任務,讓你更高效地使用ChatGPT,以及副業思考、變現思路、創業案例、落地案例分享。
2、分享ChatGPT的使用方法、最新資訊、商業價值。
3、探討未來關於ChatGPT的機遇,共同成長。
4、幫助大家解決ChatGPT遇到的問題。
5、 提供一整年的售後服務,一起搞副業
星球福利:
1、加入星球4天後,就送ChatGPT獨立帳號。
2、邀請你加入ChatGPT會員交流群。
3、贈送一份完整的ChatGPT手冊和66個ChatGPT副業賺錢手冊。
其它福利還在籌劃中... 不過,我給你大家保證,加入星球後,收獲的價值會遠遠大於今天加入的門票費用 !
本星球第一期原價 399 ,目前屬於試營運,早鳥價 149 ,每超過50人漲價10元,星球馬上要來一波大的漲價,如果你還在猶豫,可能最後就要以 更高價格加入了 。。
早就是優勢。 建議大家盡早以便宜的價格加入!

歡迎有需要的同學試試,如果本文對您有幫助,也請幫忙點個 贊 + 在看 啦!❤️
在 還有更多優質計畫系統學習資源,歡迎分享給其他同學吧!
PS:如果覺得我的分享不錯,歡迎大家隨手點贊、轉發、在看。
最後給讀者整理了一份BAT大廠面試真題,需要的可掃碼加微信備註:「面試」獲取。

版權申明:內容來源網路,版權歸原創者所有。除非無法確認,我們都會標明作者及出處,如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
END
最近面試BAT,整理一份面試資料【Java面試BAT通關手冊】,覆蓋了Java核心技術、JVM、Java並行、SSM、微服務、資料庫、數據結構等等。在這裏,我為大家準備了一份2021年最新最全BAT等大廠Java面試經驗總結。

別找了,想獲取史上最全的Java大廠面試題學習資料
掃下方二維碼回復「面試」就好了

歷史好文:

掃碼關註「後端架構師」,選擇「星標」公眾號
重磅幹貨,第一時間送達
嘿,你在看嗎?











