作者:夢晨
轉自:量子位 | 公眾號 QbitAI
ChatGPT慘遭攻擊,參數規模終於被扒出來了——
很可能只有7B (70億) 。
訊息來自南加州大學最新研究,他們使用一種攻擊方法, 花費不到1000美元 就把最新版gpt-3.5-turbo模型的機密給挖了出來。

果然,OpenAI不Open,自有別人幫他們Open。

具體來說,南加大團隊三位作者破解出了未公布的gpt-3.5-turbo 嵌入向量維度 (embedding size) 為4096或4608。
而幾乎所有已知的開源大模型如Llama和Mistral,嵌入向量維度4096的時候都是約7B參數規模。
其它比例的話,就會造成網路過寬或過窄 ,已被證明對模型效能不利。
因此南加大團隊指出,可以推測gpt-3.5-turbo的參數規模也在7B左右, 除非是MoE架構 可能不同。

數月前,曾有微軟CODEFUSION論文意外泄露當時GPT-3.5模型參數為 20B ,在後續論文版本中又刪除了這一資訊。
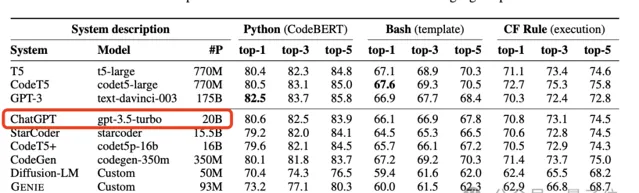
當時引起了一陣軒然大波,業界很多人分析並非不可能,先訓練一個真正的千億參數大模型,再透過種種手段壓縮、蒸餾出小模型,並保留大模型的能力。
而現在的7B,不知道是從一開始20B的訊息就不準確,還是後來又再次壓縮了。
但無論是哪一種,都證明OpenAI有很恐怖的模型最佳化能力。
撬開ChatGPT的保護殼
那麽,南加大團隊是怎麽扒出ChatGPT未公開配置的呢?
還要說到現代語言模型中普遍存在的「 Softmax瓶頸 」。
當Transformer網路處理完輸入,會得到一個低維的特征向量,也就是Embedding。這個特征向量再經過Softmax變換,就得到了最後的機率分布輸出。
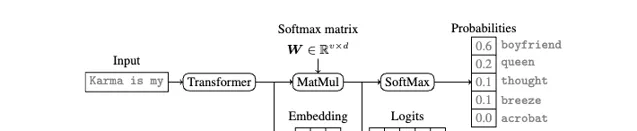
問題就出在Softmax這裏,因為矩陣的秩受限於特征向量的維度,所以大模型的輸出空間事實上被限制在了一個低維的線性子空間裏。

這就像是無論你的衣櫃裏有多少件衣服,最後能穿出去的搭配,其實是有限的。這個」衣櫃」的大小,就取決於你的「特征向量維度」有多大。
南加大團隊抓住了這一點,他們發現,只要從API呼叫中獲取到足夠多的輸出樣本,就足以拼湊出這個大模型的特征向量維度。
有了這個特征向量維度,可以 進一步推斷大模型的參數規模 、 還原出完整的機率輸出 , 在API悄悄更新時也能發現變化 ,甚至 根據單個輸出判斷來自哪個大模型 。
更狠的是,推測特征向量維度並不需要太多的樣本。
以OpenAI的gpt-3.5-turbo為例,采集到4000多個樣本就綽綽有余了,花費還不到1000美元。
在論文的最後,團隊還探討了目前的幾個應對這種攻擊的方法,認為這些方法要麽消除了大模型的實用性,要麽實施起來成本高昂。
不過他們倒也不認為這種攻擊不能有效防護是個壞事,
一方面無法用此方法完整竊取模型參數,破壞性有限。
另一方面允許大模型API使用者自己檢測模型何時發生變更,有助於大模型供應商和客戶之間建立信任,並促使大模型公司提供更高的透明度。
這是一個feature,不是一個bug。

論文:
https://arxiv.org/abs/2403.09539
參考連結:
https://x.com/TheXeophon/status/1768659520627097648
— 完 —
最後
前陣子IDE 來了一波大的更新,推出了 2023.3 正式版,做了不少最佳化,最重要的是大家期待已久的 AI Assistant 外掛程式本次更新也正式推出,助力大家提高 Coding 效率。但是很遺憾,目前我們無法使用,因為該外掛程式底層主要基於 OpenAi,大陸現在是未開放地區,未提供服務,但是經過一番折騰(白嫖不行)還是可以使用上的。
目前AI Assistant需要對帳號授權啟用。需要啟用的小夥伴可以掃描下方二維碼(備註: 購買 ),搶先啟用!,想白嫖的不要來,暫時不支持免費哦!機會稍縱即逝,錯過不再有!
讓AI Assistant為你的編程賦能,將你從乏味的工作中解放出來,前所未有地專註於重要事項。
後續我會繼續詳細分享更多實用的工具和功能。大家可以把微信公眾號,設定為
星標,這樣就不會錯過之後的精彩內容啦!
如果這篇文章對你有幫助的話,別忘了【在看】【點贊】支持下哦~
IT一線從業者抱團群
致力於幫助廣大開發者提供高效合適的工具,讓大家能夠騰出手做更多創造性的工作,也歡迎大家分享自己公司的內推資訊,相互幫助,一起進步!
組建了程式設計師,架構師,IT從業者交流群,以
交流技術
、
職位內推
、
行業探討
為主

加大佬 好友 ,備註"加群"











