JD-hotkey 是京東 APP 後台熱數據探測框架,歷經多次高壓壓測和 2020 年京東 618 大促考驗。
在上線執行的這段時間內,每天探測的key數量數十億計,精準捕獲了大量爬蟲、刷子使用者,另準確探測大量熱門商品並毫秒級推播到各個伺服端記憶體,大幅降低了熱數據對數據層的查詢壓力,提升了套用效能。
該框架歷經多次壓測,效能指標主要有兩個:
1 探測效能: 8核單機worker端每秒可接收處理16萬個key探測任務,16核單機至少每秒平穩處理30萬以上,實際壓測達到37萬,CPU平穩支撐,框架無異常。
2 推播效能: 在高並行寫入的同時,對外推播目前效能約平穩推播每秒10-12萬次,譬如有1千台server,一台worker上每秒產生了100個熱key,那麽這1秒會平穩推播100 * 1000 = 10萬次,10萬次推播會明確在1s內全部送達。如果是寫入少,推播多,以純推播來計數的話,該框架每秒可穩定對外推播40-60萬次平穩,80萬次極限可撐幾秒。
每秒單機吞吐量(寫入+對外推播)目前在70萬左右穩定。
在真實業務場景中,可用1:1000的比例,即1台worker支撐1000台業務伺服端的key探測任務,即可帶來極大的數據儲存資源節省(如對redis集群的擴充)。
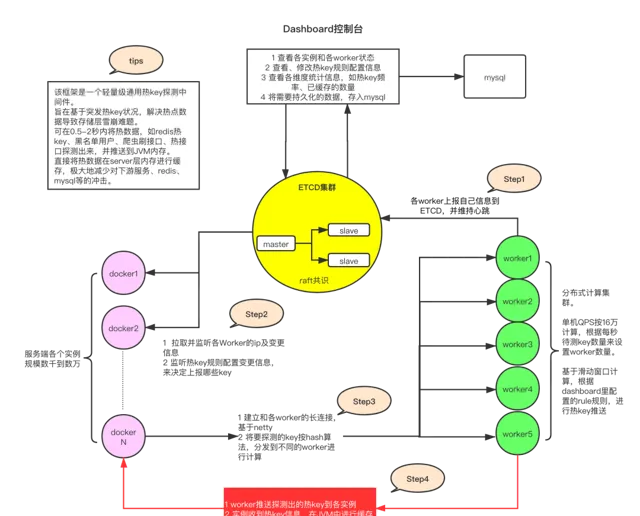
介紹
對任意突發性的無法預先感知的熱點請求,包括並不限於熱點數據(如突發大量請求同一個商品)、熱使用者(如爬蟲、刷子)、熱介面(突發海量請求同一個介面)等,進行毫秒級精準探測到。
然後對這些熱數據、熱使用者等,推播到該套用部署的所有機器JVM記憶體中,以大幅減輕對後端數據儲存層的沖擊,並可以由客戶端決定如何使用這些熱key(譬如對熱商品做本地緩存、對熱使用者進行拒絕存取、對熱介面進行熔斷或返回預設值)。這些熱key在整個套用集群內保持一致性。
核心功能: 熱數據探測並推播至集群各個伺服器。
適用場景:
mysql熱數據本地緩存
redis熱數據本地緩存
黑名單使用者本地緩存
爬蟲使用者限流
介面、使用者維度限流
單機介面、使用者維度限流限流
集群使用者維度限流
集群介面維度限流
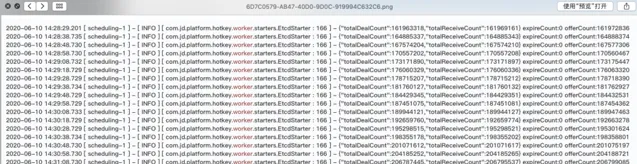
worker 端強悍的效能表現
每10秒打印一行,totalDealCount代表處理過的key總量,可以看到每10秒處理量在270萬-310萬之間,對應每秒30萬左右QPS。
僅需要很少的機器,即可完成海量key的即時探測計算推播任務。比擴容redis集群規模成本低太多。
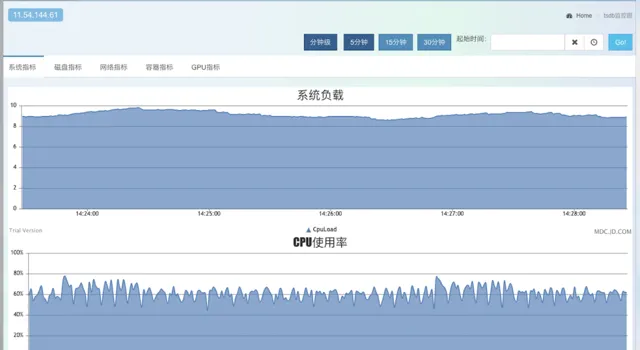
采用protobuf序列化後效能進一步得到提升。在秒級36萬以上時,能穩定在CPU 60%,壓測持續時長超過5小時,未見任何異常。30萬時,壓測時長超過數日,未見任何異常。
界面效果
來源:gitee.com/jd-platform-opensource/hotkey
>>
END
精品資料,超贊福利,免費領
微信掃碼/長按辨識 添加【技術交流群】
群內每天分享精品學習資料

最近開發整理了一個用於速刷面試題的小程式;其中收錄了上千道常見面試題及答案(包含基礎、並行、JVM、MySQL、Redis、Spring、SpringMVC、SpringBoot、SpringCloud、訊息佇列等多個型別),歡迎您的使用。
👇👇
👇點選"閱讀原文",獲取更多資料(持續更新中)











