為什麽標題我講這是個文本轉「音效」模型, 其實是轉音訊的,但更精確點來說,主要是用來生成一些擬音效果,比如刮風下雨、銀針落地的聲音、飛機起飛的轟鳴聲。
不知道你們看沒看過影視配音的場景,各種工具去模擬。
不知道後面影視配音會不會大批次被AI取代。
再講一個概念問題。 TTS大家都知道,文本轉語音,給一段文字AI給讀出來,像是今天給大家介紹的TangoFlux就是TTA,文本轉音訊。
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

計畫簡介
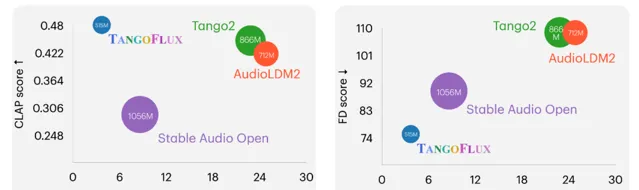
TangoFlux是由新加坡科技設計大學和NVIDIA聯合開發的高效文本到音訊生成模型。 該模型擁有5.15億參數,能在單個A40 GPU上僅用3.7秒生成長達30秒的44.1kHz音訊。 TangoFlux透過流匹配和Clap排名偏好最佳化(CRPO)技術,解決了傳統文本到音訊模型在對齊方面的難題,顯著提升了生成音訊與文本描述的匹配度。與現有頂尖模型相比,TangoFlux在音訊品質、生成速度和參數數量上均展現出優越效能。
DEMO
提示詞: 生成一段煙花表演的聲音:煙花在夜空中綻放,發出耀眼的光芒,人群在下方歡呼雀躍,背景中還隱約傳來輕柔的音樂,營造出慶祝新年的熱鬧氛圍!
提示詞: 旋律優美的人類口哨聲與自然的鳥鳴聲相得益彰
提示詞: 觀眾歡呼鼓掌
技術特點
1.高效生成能力:
TangoFlux能夠在單個A40 GPU上僅用3.7秒生成長達30秒的44.1kHz音訊。相比其他模型,它在生成速度上具有顯著優勢,能夠在更短的時間內提供高品質的音訊輸出,極大地提高了音訊生成的效率。
2.流匹配與直流量化流:
該模型采用流匹配框架,特別是直流量化流(Rectified Flows),這是一種從雜訊到目標分布的直路線徑,能夠在減少采樣步驟的同時保持音訊品質。這種技術使得模型在生成過程中更加高效和穩定,減少了對計算資源的需求.
3.Clap排名偏好最佳化(CRPO):
TangoFlux引入了CRPO技術,利用CLAP模型作為代理獎勵模型,透過叠代生成和最佳化偏好數據來增強模型的對齊能力。CRPO能夠有效地提升生成音訊與文本描述的匹配度,使音訊內容更加符合使用者的意圖和期望.
4.多模態擴散變換器架構:
模型基於多模態擴散變換器(MMDiT)和擴散變換器(DiT)構建,結合了文本提示和時長嵌入,能夠生成具有不同長度和豐富細節的音訊。這種架構使得模型在處理復雜的文本描述和生成多樣化的音訊內容方面具有更強的能力.
計畫連結
https://github.com/declare-lab/TangoFlux
試用連結
https://huggingface.co/spaces/declare-lab/TangoFlux
論文連結
https://arxiv.org/html/2412.21037v1
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新資訊
關註「 向量光年 」公眾號
加速全行業向AI轉變











