一、軟體裏的愛馬仕
Linear 是矽谷這兩年湧現出的一家明星公司。它做的是類似於 Jira, Asana 的計畫管理工具,但定位聚焦在軟體研發的計畫管理上。Linear 很早就實作盈利了,Vercel,Arc 瀏覽器,Mercury 這些當紅公司也都是 Linear 的客戶。

因為創始人強大的設計背景,其在創辦 Linear 前曾先後負責過 Coinbase 和 Airbnb 的設計團隊。所以 Linear 的產品設計尤其突出,以致在行業裏掀起了 Linear style 的設計潮流。

而就是這樣一支全身散發著光環的頂級矽谷團隊,也在前不久迎來了 5 年公司歷史上最大的一次故障 。而元兇依然是我們熟悉的橋段「刪庫 跑路 」。
二、故障時間線
此前 Linear 團隊已經在官網公開了完整的復盤報告。下面我們來詳細梳理一下時間線:
1 月 24 日
04:47: 全量備份完成 (事發前)。
07:01: 造成數據遺失的變更合並入主幹。
07:20: 變更完成。
07:52: 發現異常,開始自查。
08:10: 啟動嚴重事故預案,呼叫更多的工程師。
08:36: 更新公開渠道, 包括 status page 和 X,提示正在調查數據存取問題。
09:20: 進一步更新。
09:56: Linear 進入維護模式,防止進一步的變更操作,並且開始從備份進行恢復。
10:48: 資料庫恢復到 4:47 的備份,Linear 重新開始可以存取。
11:09: 更新 Status page 到觀察狀態。
11:30: 開始恢復 4:47 到 9:56 之間的數據。
13:50: 給 4:47 到 9:56 之間新建了 workspace 的使用者發送了信件,因為 Linear 無法重建這些 workspace。
15:35: 給所有受到影響的使用者和 workspace 管理員發送信件,告知故障的資訊和恢復方式。
1 月 25 日
14:00: 通知管理員上線了專門的數據還原頁面。
14:25: 修復了數據還原頁面的 bug,強制客戶端重新整理 (這又打掛了 API 導致了套用載入的問題).
16:40: 數據恢復試執行啟動。
17:49: 正式的數據恢復開始。
19:48: 恢復了 98% 受影響的 workspace。
23:20: 恢復了 99% 受影響的 workspace。
1 月 26 日
07:37: 除了一個 workspace 之外,所有的都恢復了。
08:39: 完成了最後一個 workspace 的恢復。
讀著時間線應該也能感受到緊張。事實上筆者所在團隊也是 Linear 的使用者,受到了波及。這是當時我們收到的信件。
使用者故障群裏也有比較著急的使用者:

三、故障原因
Linear 使用的是 PostgreSQL 資料庫,它官網上沒有提。但在另一個生成 PG 測試數據的產品 snaplet.dev 的官網上,列了 Linear。
導致刪數據的是這條語句:
CASCADE 關鍵詞會把所有有外健關聯到 new_table 的表數據都清空掉。
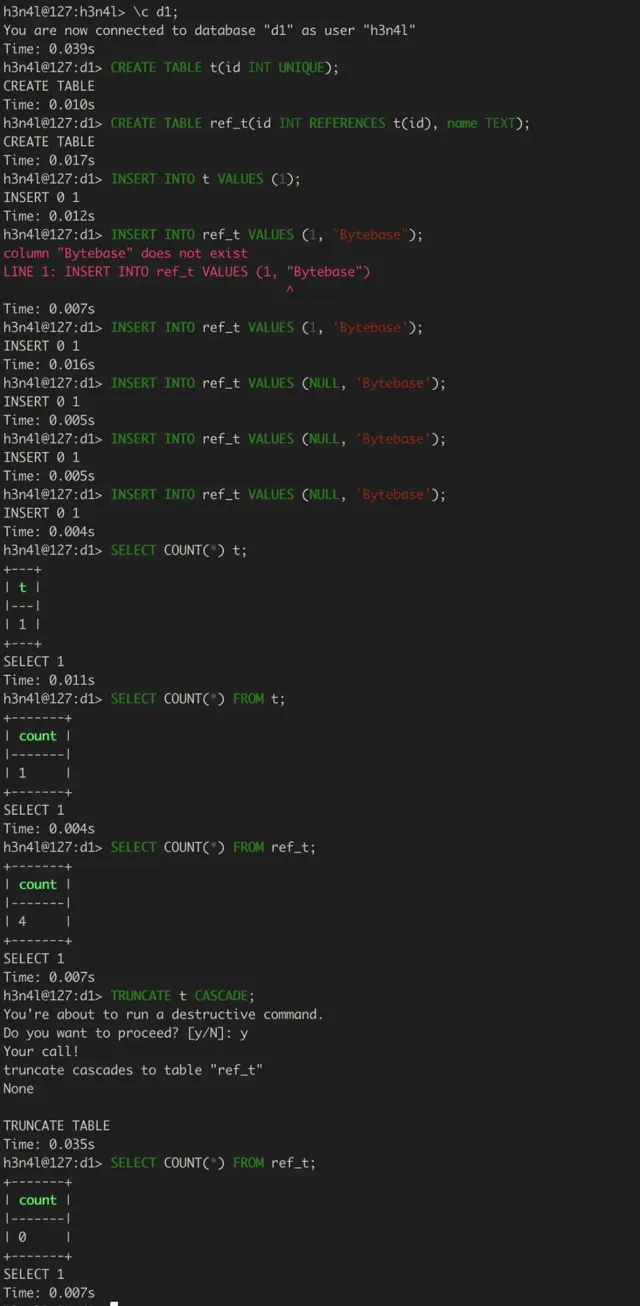
上面我們簡單模擬了一下場景,可以看到當我們 TRUNCATE t CASCADE 後,會把 ref_t 的數據也都清空。我們看到透過命令列操作是有提示的,但是變更生產環境的流程通常不會采用命令列直連的方式。
Linear 采用的是 主幹開發 ,要變更的 SQL 指令碼是保存在程式碼倉柯瑞的。每次變更時,先送出 SQL 語句進行稽核,稽核會進行一些 CI 的自動檢查和人工稽核,沒有問題後,SQL 指令碼合並入主幹,然後觸發變更。因為程式碼釋出和資料庫變更是分離的,為了保持程式碼能同時相容新舊兩個資料庫版本,會使用 feature flag。
Linear 的 CI 自動檢查沒有捕捉到這個問題,因為 CI 裏沒有針對 TRUNCATE 的規則。而在本地測試和人工稽核時也都沒有發現這個問題,也是因為這個 TRUNCATE 的隱蔽性更強。Linear 這次是在開發一個新功能時從現有的生產資料庫表裏建立了一份測試資料庫表。工程師在測試完成後,打算清理測試資料庫表。但因為生產數據表也關聯了測試數據表的外來鍵。所以 TRUNCATE 測試數據表時,也把生產數據表跟端掉了。
四、故障排查和恢復
因為 Linear 使用了好幾層緩存,所以在誤刪了生產數據後,客戶端因為緩存的關系,還沒有直接報錯,辨識到問題的時間就靠後了些。
不過 Linear 因為本身要實作同步的需要,把使用者的每一次操作都以日誌的形式記錄了下來,這部份的數據是單獨存放的,所以他們可以基於 4:47 的全量備份,回放所有的使用者操作。但還是會有少部份操作,因為沖突的原因是無法自動回放的,這就還是需要使用者手動介入。
另外 Linear 的 PostgreSQL 資料庫是開啟了 Point-in-time recovery (PITR),但因為團隊之前沒有測試過 PITR,所以在恢復時沒有選擇這個方案,不然的話,其實可以透過 PITR 恢復到 7:01 這個變更發生的時間點,然後再回放接下來的使用者操作。這樣可以縮小回放的數據量。
五、故障影響面
所有使用者都經歷了 1 個小時的不可用,這段時間 Linear 在從備份中恢復數據。Linear 在 36 小時內恢復了 99% 的誤刪數據,剩下的因為沖突的原因沒有辦法自動解決。Linear 也說這是它 5 年歷史上最嚴重的一次故障。

從故障發生的 1.24 到發出復盤報告的 1.30,整個團隊 顯然是在連軸轉 (work around the clock)。
六、故障反思
Linear 自己列了如下的改進措施:
剝奪所有使用者在生產資料庫上的 TRUNCATE 許可權。
改進如何建立和執行資料庫的變更操作。其中包括透過 DBA 的稽核實踐,和程式碼稽核分離,以及自動檢查高危操作。
改進預發環境的資料庫變更測試流程。
構建和演練使用 PITR 的數據恢復流程。
改進內部事故處理的流程。
改進數據完整性檢查。
給 Linear 添加唯讀模式。這樣即使資料庫不可寫時,依然可以能讓使用者存取。
Linear 在意識到問題的第一時間就完全公開了所有情況,整個復盤報告也非常詳細,對於其它研發團隊也是一份很好的參考。
前車之鑒,後世之師。我們要是看 Linear 之前的流程,已經有 稽核 ,有 自動 CI 檢查 ,還有 定期的備份恢復演練 。但資料庫變更就是一個高危又精細的操作流程,專業性極強。這也是我們團隊紮根這個方向的原因,看似 1 個人 2 周時間可以糊出來的 SQL 工單平台,背後有數不清的細節,而漏掉任何一個,都可能引起誤操作,導致公司歷史上最大的故障。 事實上我們從 Linear 的這次事故中,也吸取了教訓,在下一版本中 添加了關於 TRUNCATE 操作的自動檢查 。
讀罷 Linear 的整個報告,還是要感慨它的透明度,所謂的 blameless postmortem(對事不對人的復盤)在這個報告中體現的淋漓盡致。再聯想到去年國內上熱搜的大故障,即使到現在,好多官方也沒有一個正式的故障復盤。可能因為定責到個人,個人背後有主管,會影響到績效,績效掛鉤獎金和晉升,各種利益夾雜在一起,就很難開誠布公地聊了。定責在國內是一種約定俗成,現階段也很難去改變它,下次再寫寫怎麽樣讓定責可以更加客觀吧。
作者丨 天舟
來源丨公眾號:Bytebase(ID:Bytebase)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












