一、滴滴 Elasticsearch 簡介
1.簡介
Elasticsearch 是一個基於 Lucene 構建的開源、分布式、RESTful 介面的全文搜尋引擎,其每個欄位均可被索引,且能夠橫向擴充套件至數以百計的伺服器儲存以及處理 TB 級的數據,其可以在極短的時間記憶體儲、搜尋和分析大量的數據。
滴滴 ES 發展至今,承接了公司絕大部份端上文本檢索、少部份日誌場景和向量檢索場景,包括地圖 POI 檢索、訂單檢索、客服、內搜及把脈日誌 ELK 場景等。滴滴 ES 在2020年由2.X升級到7.6.0,近幾年圍繞保穩定、控成本、提效能和優生態這幾個方向持續探索和改進,本文會圍繞這幾個方向展開介紹。
2.架構
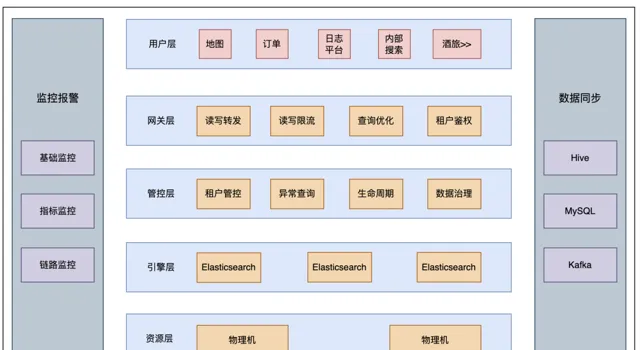
滴滴 ES 整體產品架構如上圖所示,目前ES服務基於物理機部署,Gateway 和管控基於容器部署,我們也調研過 ES on K8S,因為我們 ES 的業務場景多是線上端上文本檢索,考慮到穩定性,所以最後還是決定使用物理機部署模式。
管控層主要負責實作以下功能:智慧 segment Merge(防止 segment 膨脹導致 datanode Full GC),索引生命周期管理,索引預建立(避免每天淩晨索引集中建立,導致 Master/Clientnode OOM),租戶管控等。
閘道器層(Gateway)除了負責讀寫轉發外,還具備查詢最佳化能力(例如,將 BKD 查詢覆寫為數值型別的等值查詢或範圍查詢)、三級限流(包括 AppID、索引樣版級別和查詢 DSL 級別)、租戶鑒權功能以及 SQL 能力(基於 NLPChina 開源的 ES SQL 能力進行魔改並封裝到 Gateway)等。我們的檢索服務僅對外暴露 Gateway 介面。
3.使用者控制台
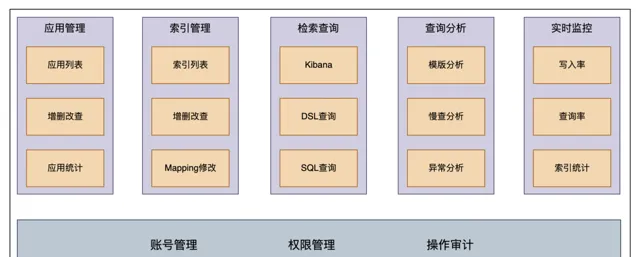
使用者控制台是我們提供給業務方產品接入的平台,主要功能:
套用管理: 允許業務方透過申請 AppID 來獲取讀寫索引的許可權。
索引管理:
支持新建索引、申請索引讀寫許可權、索引 mapping 建立和更改、以及索引的清理和下線操作。
檢索查詢提供多種查詢方式,包括 Kibana、DSL 和 SQL,以滿足不同的查詢需求。
同時業務方可以在查詢分析模組看到對應的異常分析和慢查分析等,方便查詢最佳化。監控方面業務方可以檢視索引元資訊(如文件數及大小等)以及讀寫速率等,以監控系統執行狀態。
4.運維管控平台
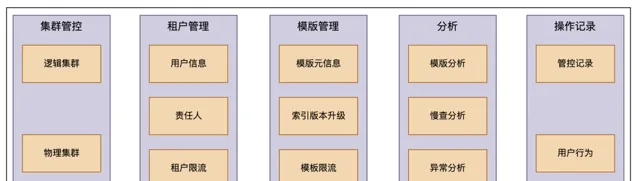
運維管控平台主要是滿足 RD 和 SRE 日常運維需求,主要功能包括以下幾個方面:
集群管控: 展示集群資訊,對使用者暴露的是邏輯集群,一個邏輯集群可包含多個物理集群,如使用者看到的集群資訊是一個 important 公共集群,但是真實的物理集群包含幾十個小的公共 important 集群
租戶管理
(租戶元資訊和租戶級別的限流)
模版管理:
索引樣版後設資料管理,非更新索引可以透過升版本調整 shard 數,也可以在此處對索引樣版限流
異常分析:
模版分析、慢查分析及異常分析
操作記錄
:
使用者行為及管控定時任務記錄
二、Elasticsearch 在滴滴的套用
1.業務場景
線上全文檢索服務,如地圖 POI 起終點檢索
MySQL 即時數據快照,線上業務如訂單查詢
一站式日誌檢索服務,透過 Kibana 查詢,如 trace 日誌
時序數據分析,如安全數據監控
簡單 OLAP 場景,如內部數據看板
向量檢索,如客服 RAG
2.部署模式
物理機+小集群部署方式,最大集群機器規模100台物理機左右
3.接入方式
透過使用者控制台建立索引,業務方根據業務需求選擇對應集群
透過閘道器查詢,根據集群等級提供 gateway vip 地址,該閘道器是一個 HTTP 型別的服務,我們做了相容,業務方可以透過官方提供的SDK讀寫Gateway,Gateway 會根據索引找到對應的ES集群
4.數據同步方式
一共兩種數據同步方式,一種是走同步中心(公司數據平台提供統一的同步服務),一種是透過 Gateway 即時寫入,同步中心支持即時類和離線類的數據同步方式。
即時類:
日誌 -> ES
MQ(Kafka、Pulsar)-> ES
MySQL -> ES

即時類同步方式
如上圖所示,即時類同步方式有2種,一種是日誌和 MySQL Binlog 透過采集工具采集到 MQ,之後透過統一封裝的 DSINK 工具,透過 Flink 寫入到 ES;另一種是 MySQL 全量數據,其基於開源的 DataX 進行全量數據同步。
離線類:
Hive -> ES

Hive->ES 整體思路是透過 Batch Load,加快數據匯入。透過 MR 生成 Lucene 檔,之後透過封裝的 ES AppendLucene 外掛程式把 Lucene 檔寫入到 ES 中。Hive->ES 整體流程,如上圖所示:
使用 MR 生成 Lucene 檔
Lucene 保存在 HDFS 裏
將檔拉取到 DataNode 裏
匯入到 ES 中
三、引擎叠代
1.精細化分級保障
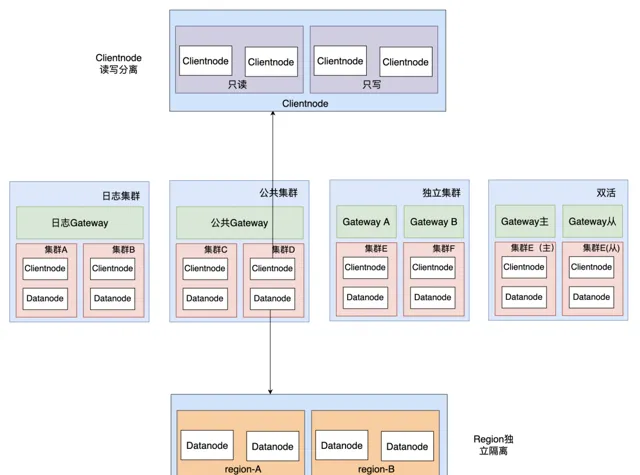
精細化分級保障主要解決的問題是當集群出現故障時,影響面降低到最低,主要包括以下策略:
集群級別隔離: 4種保障級別(日誌集群、公共集群、獨立集群和雙活集群),業務接入時,會在使用者控制台選擇其想要的集群。如果選錯集群我們會透過 DCDR(下文介紹)幫助業務在不影響業務且不感知的前提下遷移到其他集群。
Clientnode 隔離: Clientnode 讀寫分離,當 Clientnode 異常時,能快速定位故障原因也能減少影響面。如集群寫入慢且寫入量過大,Clientnode 可能導致 OOM,此時只會影響寫入不會影響查詢,可以降低業務的影響面。
Datanode Region 隔離: 當集群出現異常索引(如異常索引導致整個 datanode 寫入過慢)時,可以透過打 label 的方式,讓異常索引快速遷移到指定機器,避免影響集群上其他業務。
2.多活建設
滴滴跨數據中心復制能力 - Didi Cross Datacenter Replication,由滴滴自研,簡稱DCDR,它能夠將數據從一個 Elasticsearch 集群原生復制到另一個 Elasticsearch 集群。原理如下圖所示,DCDR 工作在索引樣版或索引層面,采用主從索引設計模型,由 Leader 索引主動將數據 push 到 Follower 索引,從而保證了主從索引數據的強一致性。
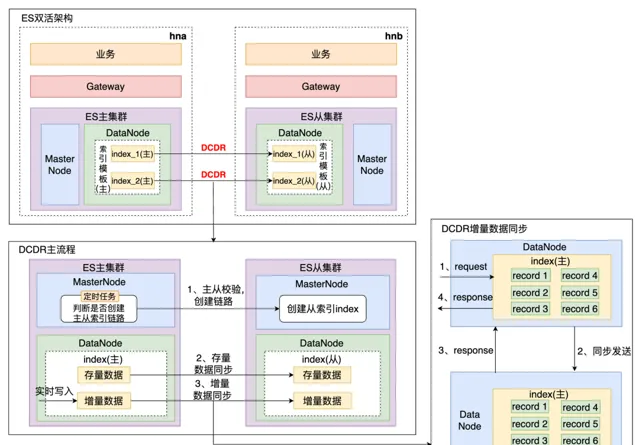
我們調研了官方內建的的 ES CCR,發現其收費且基於 pull-based 模型,時效性較差,所以我們的 DCDR 方案是:
Push-based 模型,即時寫入基於 Request
新增 CheckPoint 避免全量數據拷貝
新增 Sequence Number 保障更新操作主從一致性
引入寫入佇列,避免大量數據復制導致 OOM
DCDR解決了數據跨集群或者跨機房的數據即時同步問題,且我們基於管控實作了雙活能力。
ES DCDR 的詳細解析見:【 】
3.效能專項:JDK17 + ZGC
JDK11-G1 Yong GC 平均暫停時間長,不滿足業務 P99 要求,如 POI 超時,時是180ms,P99 要求60ms內,支付業務 P99 500ms,訂單業務 P99 400ms;寫入數據量大的場景,GC 頻繁,加劇集群寫入 reject 問題,寫入延時大,不滿足業務需求。
基於上述背景,我們對 JDK17-ZGC 進行調研,經過測試 ZGC 可以將 GC 暫停時間控制在10ms內,能夠很好地解決 GC 導致的查詢耗時問題。同時針對日誌這種高吞吐場景,測試了JDK17-G1,發現 GC 效能相較於 JDK11-G1 提升了15%,並且 JDK17 在向量化支持、字串處理等方面做了許多最佳化,能在一定程度上緩解日誌集群的寫入壓力。所以我們決定將 ES JDK 版本從11升級到17,並將部份業務 GC 演算法從 G1 升級到 ZGC,主要工作如下:
Groovy 語法升級、 Plugin 外掛程式重構
解決語法格式導致程式碼編譯失敗問題
解決 ES 源碼觸發 JVM 編譯 BUG
依賴 Jar 包升級、類替換、類重構、註解最佳化
搭建 ZGC 監控指標體系
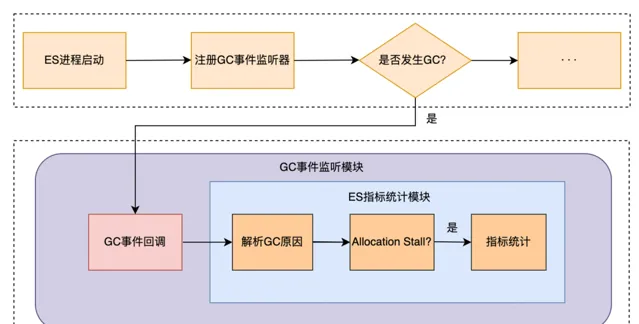
ZGC監控指標體系
支付集群上線ZGC後,P99從800ms降低到30ms,下降96%平均查詢耗時從25ms降低到6ms,下降75%。日誌集群升級JDK17後,寫入效能提升15~20%,解決寫入佇列堆積和 reject 問題。
ES JDK17的升級,詳情見:【 】
4.成本最佳化
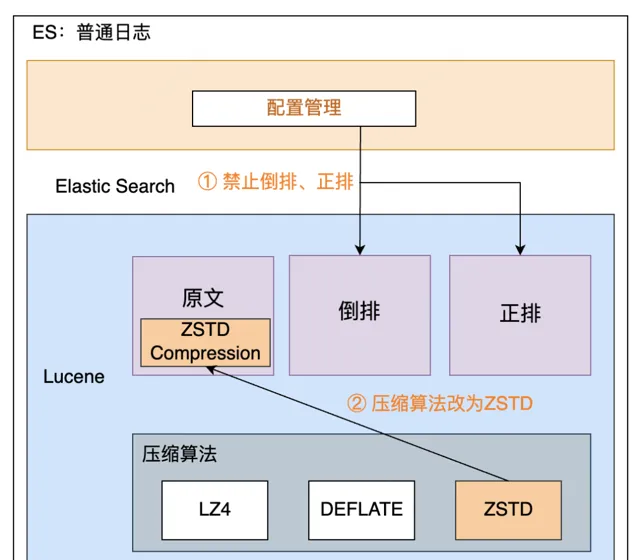
成本最佳化主要包括降低機器成本和降低使用者成本。
降低機器成本核心是降低儲存規模和降低 CPU 使用率,即降低機器數;降低使用者成本的核心邏輯是降低業務用量,所以 ES 整體成本最佳化策略如下:
索引 Mapping 最佳化,禁止部份欄位倒排、正排
新增 ZSTD 壓縮演算法,CPU 降低15%
接入大數據資產管理平台,梳理無用分區和索引,協助業務下線
關於 ES 支持 ZSTD 的實作,詳情見:【 】
5.多租戶資源隔離
JDK原生執行緒池模型:
主執行緒呼叫 execute、或者 submit 等方法送出任務給執行緒池。
如果執行緒池中正在執行的工作執行緒數量小於 corePoolSize(核心執行緒數量),那麽馬上建立執行緒執行這個任務。
如果執行緒池中正在執行的工作執行緒數量大於或等於 corePoolSize(核心執行緒數量),那麽將這個任務放入佇列,稍後執行。
如果這時佇列滿了且正在執行的工作執行緒數量還小於 maximumPoolSize(最大執行緒數量),那麽會建立非核心工作執行緒立刻執行這個任務,這部份非核心工作執行緒空閑超過一定的時間(keepAliveTime)時,就會被銷毀回收。
如果最終送出的任務超過了 maximumPoolSize(最大執行緒數量),那麽就會執行拒絕策略。
我們借鑒了 Presto Resource Group 隔離的思路,策略是將原來的 search 執行緒池按照配置拆分為多個 seach 執行緒池並組建執行緒池組。由於多租戶的查詢 QPS、重要等級不同,可以配置相應的執行緒數量和佇列大小。透過執行緒池組模式,隔離不同 Appid 使用者的查詢請求。

核心工作流程為獲取 Appid,根據配置的Appid隔離資訊將任務送出到對應的子執行緒組中執行。
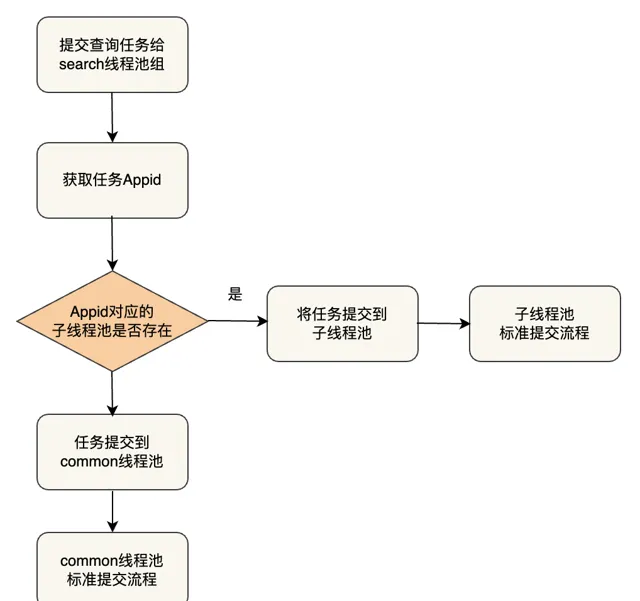
目前此最佳化主要用於一份索引數據會被很多個業務方使用的場景,如訂單業務,訂單業務會被公司各個業務線使用,所以查詢 appid 會非常多,我們透過多租戶資源隔離限制指定 Appid 的執行緒池大小,避免由於某業務突然發送大量讀請求導致 CPU 打滿,核心業務受損。
6.數據安全
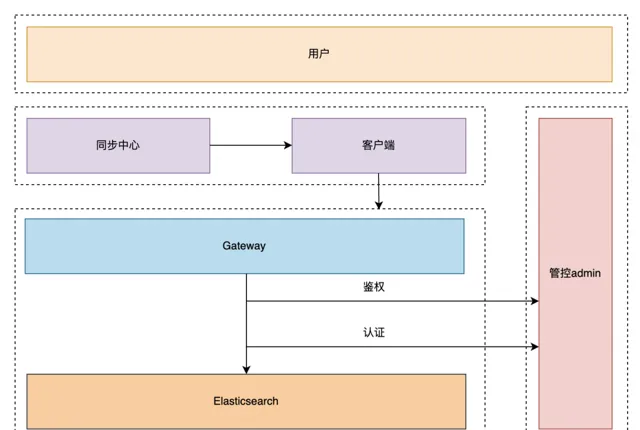
兩種級別的鑒權和認證:
Gateway 級別 : 主要是 Appid 級別的鑒權
ES 級別
(Clientnode、Datanode、MasterNode),主要是做認證
ES 的 X-Pack 外掛程式是有安全認證能力的,但是不支持集群捲動升級重新開機,無法快速回滾,誤刪儲存有穩定性風險,基於此我們自研了一個安全外掛程式,優勢:
架構簡單,邏輯清晰,只需在 HTTP 請求處理環節中進行簡單的字串校驗,無需涉及節點內部 TCP 通訊驗證。
支撐 ES 集群捲動重新開機升級
支持一鍵開關安全認證能力,可以快速止損
關於ES安全認證方案,詳情見:【
】
7.穩定性治理
線上文本檢索對穩定性要求非常高,所以過去的三年,我們穩定性方面主要做了如下圖所示的以下工作:
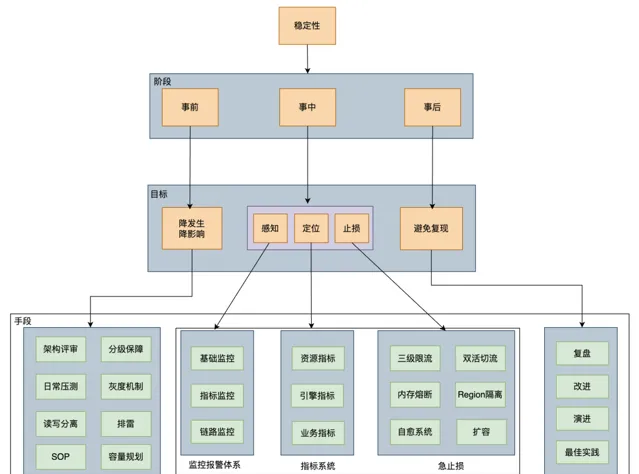
穩定性治理主要是做好三件事:事前、事中和事後。事情預防為主,事中能夠快速定位和止損,事後註重復盤,避免問題重復出現,
事前預防為主,持續最佳化 : 我們每年都會把穩定性當做最重要的事情去做,規範先行,落實穩定性紅線,包括方案設計、程式碼規範、上線規範、報警處理及故障管理等。每年都會執行穩定性「踩地雷」專項,三年時間我們共解決了61個穩定性隱患,如解決 Gateway Full GC 問題(業務限流後,Gateway會立馬恢復正常),後設資料治理,重寫部份鎖解決 ThreadLocal 泄露(ThreadLocal 泄露會導致部份節點突然 CPU 飆升)等,同時落地故障止損SOP
監控報警體系建設 ,我們做了基礎監控(如硬碟、CPU等),指標監控(如shard數,master pending task 個數等),鏈路監控(監控 MQ Lag,提前發現鏈路延時問題)
指標系統建設 ,透過 grafana 建設了監控大盤,包括模版指標,shard 指標,節點指標及集群指標等,這些指標能夠協助我們快速定位故障原因,如 CPU 突增問題,我們可以做到5分鐘內快速止損
止損側 我們做了自愈系統(如磁盤故障,查詢突增),日常雙活切流演練,讀寫限流等,其中讀限流做了基於 Appid、索引樣版和查詢DSL的限流,當出現集群 CPU 突增問題時,限流方案也會盡可能降低對業務的影響。
總結與展望
近年來,我們基於 ES 7.6.0 版本,圍繞保穩定、控成本、提效能和優生態方面進行了持續的探索和改進。目前,我們的 ES 引擎已在滴滴內部統一套用於所有線上檢索場景,並在穩定性方面成為大數據架構部的標桿。
我們還嘗試過一些創新方案,如冷熱數據分離、離線上混合部署以及使用 Flink Checkpoint 機制替代 Translog 等,但由於效能或穩定性等方面的考慮,這些方案並未被采納。然而,隨著技術的不斷發展,我們將繼續探索和完善這些方案,以應對未來可能出現的挑戰。
目前,我們使用的 ES 版本是 7.6,而社群的最新版本已經更新至 8.13,兩者之間存在約 4 年的版本差距。因此,我們今年的重點工作是將 ES 平滑升級至 8.13 版本,以解決以下問題:
新版本的 ES Master 效能更優
能夠根據負載自動平衡磁盤使用
減少 segment 對記憶體的占用
支持向量檢索的 ANN 等新特性
在效能方面,我們將針對更新場景最佳化寫入效能,同時改進查詢過程中的 Merge 策略。此外,我們還將持續探索新版本 ES 的機器學習能力,以便更好地為業務提供支持。
作者丨杜若飛
來源丨公眾號:滴滴技術(ID: didi_tech )
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]











