多跳查詢為企業提供了深入的數據洞察和分析能力,它在小紅書眾多線上業務中扮演重要的角色。然而,這類查詢往往很難滿足穩定的 P99 時延要求。小紅書基礎架構儲存團隊針對這一挑戰,基於大規模並列處理(MPP)的理念,開發了一種圖資料庫上的分布式並列查詢框架,成功將多跳查詢的時延降低了 50% 以上,尤其是使 3 跳查詢在線上場景從不能用到落地,極大地增強了線上業務的數據處理能力。
本文核心貢獻在於: 團隊提出了一種從框架層面最佳化多跳查詢時延的方案,在業務上使線上場景中使用多跳查詢成為可能,在技術上實作了圖資料庫查詢的框架級最佳化。 全文將從以下幾個方面依次展開:
介紹小紅書使用圖資料庫的背景,並分析多跳查詢在實際業務中因時延高而受限的現狀(需求是什麽)
深入探討 REDgraph 架構,揭示原有查詢模式的不足和可最佳化點(存在的問題)
詳細闡述最佳化原查詢模式的方案,並提供部份實作細節(改進方案)
透過一系列效能測試,驗證最佳化措施的有效性(改進後效果)
本方案為具有復雜查詢需求的線上儲存產品提供了最佳化思路,歡迎業界同行深入探討。
同時,作者再興曾在「DataFunCon 2024·上海站」分享過本議題,感興趣的同學歡迎點選「閱讀原文」,回看完整錄播視訊。

1.1 圖資料庫在小紅書的使用場景
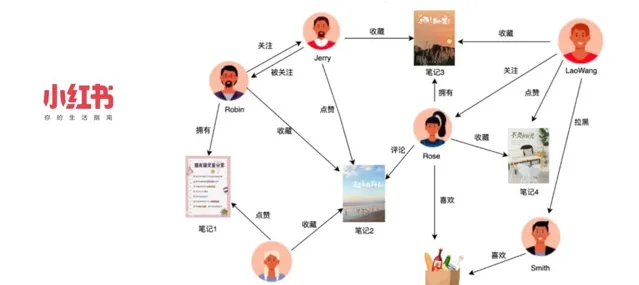
小紅書是一個以社群內容為主的產品,覆蓋多個領域,鼓勵使用者透過圖文、短視訊、直播等形式記錄和分享生活點滴。在社交領域中,我們存在多種實體,如使用者、筆記、商品等,它們之間構成了復雜的關系網路。為高效處理這些實體間的一跳查詢,小紅書自研了圖儲存系統 REDtao,滿足極致效能的需求。
(參見: )
面對更為復雜的多跳查詢場景,我們自研了圖資料庫系統 REDgraph,將多跳查詢的需求套用於小紅書多個業務領域,包括但不限於:
社群推薦:利用使用者間的關系鏈和分享鏈,為使用者推薦可能感興趣的好友、筆記和視訊。這類推薦機制通常涉及多於一跳的復雜關系。
風控場景:透過分析使用者和裝置的行為模式,辨識可能的欺詐行為(如惡意薅羊毛),從而保護平台免受濫用和作弊行為的影響。
電商場景:構建商品與商品、商品與品牌之間的關聯模型,最佳化商品分類和推薦,從而提升使用者的購物體驗。
在傳統的 SQL 產品(如 MySQL)中,想實作這些多跳查詢,通常需要在一個查詢語句中寫多個 JOIN,這樣的效能無疑是較差的。若想利用鍵值儲存 KV 產品實作,則需要分多次發送 get 請求,並自行處理中間結果,實作過程也較為麻煩。
相比之下,圖資料庫的設計理念為處理這類查詢提供了天然優勢。在圖資料庫中,數據表被抽象為頂點,表之間的關系被抽象為邊,並且邊作為一等公民被儲存和處理。這樣一來,執行 n 度關系查詢只需查詢 n 次邊表,大大簡化查詢過程,並提高了效率。
1.2 業務上面臨的困境
小紅書在社交、風控及離線任務排程等場景中均采用了圖資料庫,然而在實際套用過程中遇到了一些挑戰。
場景一:社交推薦
在社交推薦中,我們希望能夠及時地將使用者可能感興趣的好友或內容推薦給他們。例如,如果使用者 A 關註了使用者 B,而使用者 B 點贊了筆記 C,那麽使用者 D(也點贊了筆記 C)就可能成為使用者 A 的潛在好友,使小紅書的好友社群建立更豐富的連線。
業務當然可以使用離線任務分析,基於分析結果進行推薦,但社交圖譜是無時無刻不在變化,基於離線分析做出的推薦往往是滯後的。如果推薦得更及時,能更好地抓住一些潛在的使用者關系,建立更豐富完善的社交圖譜,賦能其他業務(如:社群興趣小組,電商商品推薦)。
業務希望能即時向使用者推播可能感興趣的 「好友」 或 「內容」,如果能即時完成此推薦,則能有效最佳化使用者使用體驗,提升留存率。然而,由於先前 REDgraph 在某些方面的能力尚未完善,導致三跳時延比較高,所以業務一直只采用了一跳和兩跳查詢。
場景二:社群生態與風險控制
小紅書致力於促進社群生態的健康發展,對優質內容創作者提供獎勵。然而,這也吸引了一些作弊使用者想薅羊毛。例如,作弊使用者可能會透過組織點贊來提升低品質筆記的排名,將低質筆記偽造成優質筆記以賺取獎勵。
風控業務需要對這種行為予以辨識並防範,借助圖資料庫的多跳查詢,我們構建出一個包含使用者和筆記為頂點、點贊為邊的復雜關系圖(「使用者->筆記-> ... ->使用者->筆記「)。隨後,對每篇筆記查詢其多度關系(筆記 -> 使用者 -> 筆記 -> 使用者)上作弊使用者的比例,若比例高於一定閾值,把筆記打上作弊標簽,系統便不對作弊使用者和作弊筆記發放獎勵。
打標行為往往是即時消費訊息佇列去查詢圖資料庫,如果查詢動作本身比較慢,則會造成整體消費積壓。例如,如果一個查詢任務本應在 12:00 執行,但由於效能問題直到 12:10 才開始觸發,那麽在這十分鐘的延遲期間,一篇劣質筆記已成為優質筆記,作者薅羊毛成功。等到發現這是作弊使用者時,顯然「為時晚矣」,因為損失已經造成了。
具體來說,社交推薦場景要求三跳的 P99 低於 50 毫秒,風控場景則要求三跳的 P99 低於 200 毫秒,這是目前 REDgraph 所面臨的一大難題。那為何一至二跳可行,三跳及以上就難以實作呢?對此,我們基於圖資料庫與其他型別系統在工作負載的差異,做了一些難點與可行性分析。
1.3 難點與可行性分析
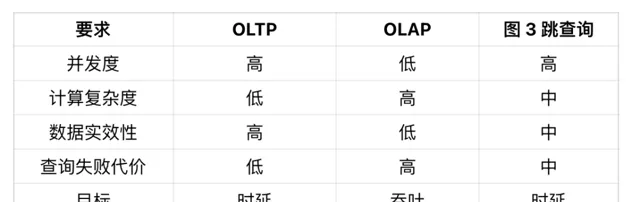
首先在並行方面,OLTP 的並行度很高,而 OLAP 則相對較低。圖的三跳查詢,服務的仍然是線上場景,其並行度也相對較高,這塊更貼近 OLTP 場景。
其次在計算復雜度方面,OLTP 場景中的查詢語句較為簡單,包含一到兩個 join 操作就算是較為復雜的情況了,因此,OLTP 的計算復雜度相對較低。OLAP 則是專門為計算設計的,因此其計算復雜度自然較高。圖的三跳查詢則介於 OLTP 和 OLAP 之間,它雖不像 OLAP 那樣需要執行大量的計算,但其存取的數據量相對於 OLTP 來說還是更可觀的,因此屬於中等復雜度。
第三,數據時效性方面,OLTP 對時效性的要求較高,必須基於最新的數據提供準確且即時的響應。而在 OLAP 場景中則沒有這麽高的時效要求,早期的 OLAP 資料庫通常提供的是 T+1 的時效。圖的三跳查詢,由於我們服務的是線上場景,所以對時效性有一定的要求,但並不是非常高。使用一小時或 10 分鐘前的狀態進行推薦,也不會產生過於嚴重的後果。因此,我們將其定義為中等時效性。
最後,查詢失敗代價方面。OLTP 一次查詢的成本較低,因此其失敗的代價也低;而 OLAP 由於需要消耗大量的計算資源,因此其失敗代價很高。圖查詢在這塊,更像 OLTP 場景一些,能夠容忍一些失敗,但畢竟存取的數據量較大,在查一遍代價稍高,因此同樣歸屬到中等。
總結一下:圖的三跳查詢具備 OLTP 級別的並行度,卻又有比一般 OLTP 大得多的數據存取量和計算復雜度,所以比較難在線上場景中使用。好在其對數據時效性的要求沒那麽高,也能容忍一些查詢失敗,所以我們能嘗試對其最佳化。
此外正如上文指出的,在小紅書業務場景中,三跳查詢的首要目標還是降低延遲。有些系統中會考慮犧牲一點時延來換取吞吐的大幅提升,而這在小紅書業務上是不可接受的。如果吞吐上不去,還可以透過擴大集群規模來作為兜底方案,而如果時延高則直接不能使用了。

2.1 REDgraph 架構
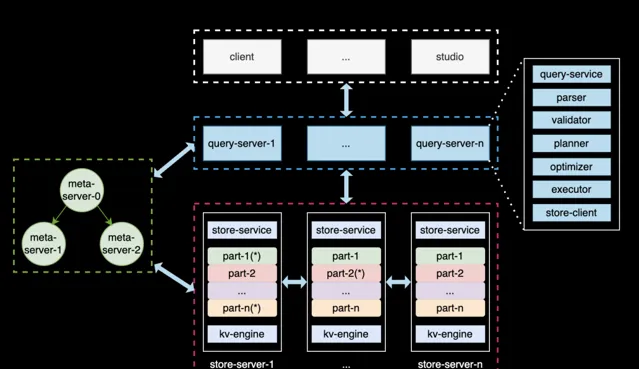
REDgraph 的整體結構如上圖所示,其與當前較為流行的 NewSQL,如 TiDB 的架構構相似,采用了存算分離 + shared-nothing 的架構。奇包含三類節點:
Meta 服務 :負責管理圖資料庫的元資訊,包括數據模式(Schema)、使用者帳號和許可權、儲存分片的位置資訊、作業與後台任務等;
Graph 服務 :負責處理使用者的查詢請求,並做相應的處理,涵蓋查詢的解析、校驗、最佳化、排程、執行等環節。其本身是無狀態的,便於彈性擴縮容;
Storgae 服務 :負責數據的物理儲存,其架構分為三層。最上層是圖語意 API,將 API 請求轉換為對 Graph 的鍵值(KV)操作;中間層采用 Raft 協定實作共識機制,確保數據副本的強一致性和高可用性;最底層是單機儲存引擎,使用 rocksdb 來執行數據的增刪查等操作。
2.2 圖切分方式
圖切分的含義是,如果我們擁有一個巨大的圖,規模在百億到千億水平,應該如何將其儲存在集群的各節點之中,即如何對其切分。在工業界中,主要存在兩種典型的切分策略:邊切分和點切分。
邊切分,以頂點為中心,這種切分策略的核心思想是每個頂點會根據其 ID 進行哈希運算,並將其路由到特定的分片上。每個頂點上的每條邊在磁盤中都會被儲存兩份,其中一份與起點位於同一分片,另一份則與終點位於同一分片。
點切分,與邊切分相對應,也就是以邊為中心做哈希打散,每個頂點會在集群內保存多份。
這兩種切分方式各有利弊。邊切分的優點在於每個頂點與其鄰居都保存在同一個分片中,因此當需要查詢某個頂點的鄰居時,其存取局部性極佳;其缺點在於容易負載不均,且由於節點分布的不均勻性,引發熱點問題。點切分則恰恰相反,其優點在於負載較為均衡,但缺點在於每個頂點會被切成多個部份,分配到多個機器上,因此更容易出現同步問題。
REDgraph 作為一個線上的圖查詢系統,選擇的是邊切分的方案。
2.3 最佳化方案 1.0
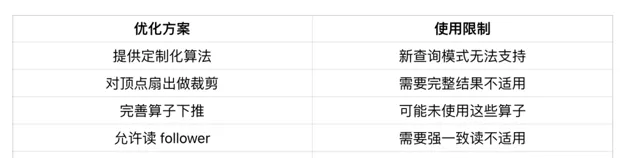
· 通用性差,且在 3 跳場景中效果還不夠。
我們之前已經實施了一些最佳化,可以稱之為最佳化方案 1.0。當時主要考慮的是如何快速滿足使用者需求,因此我們的方案包括:首先根據常用的查詢模式提供一些客製化的演算法,這些演算法可以跳過解析、校驗、最佳化和執行等繁瑣步驟,直接處理請求,從而實作加速。其次,我們會對每個頂點的扇出操作進行最佳化,即每個頂點在向外擴充套件時,對其擴充套件數量進行限制,以避免超級點的影響,降低時延。此外,我們還完善了算子的下推策略,例如 filter、sample、limit 等,使其盡可能在儲存層完成,以減少網路頻寬的消耗。同時,我們還允許讀從節點、讀寫執行緒分離、提高垃圾回收頻率等最佳化。
然而,這些最佳化策略有一個共性,就是每個點都比較局部化和零散,因此其通用性較低。比如第一個最佳化,如果使用者需要發起新的查詢模式,那麽此前編寫的演算法便無法滿足其需求,需要另行編寫。第二個最佳化,如果使用者所需要的是頂點的全部結果,那此項也不再適用。第三個最佳化,如果查詢中本身就不存在這些運算子,那麽自然也無法進行下推操作。諸如此類,通用性較低,因此需要尋找一種更為通用,能夠減少重復工作的最佳化策略。
2.4 新方案思考
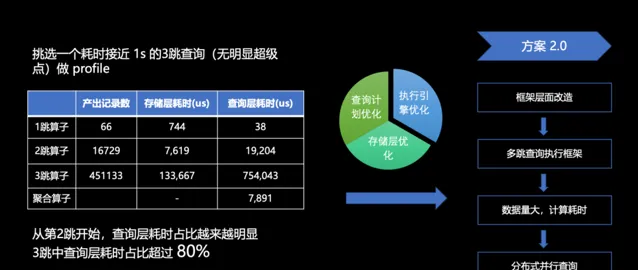
如上圖所示,我們對一個耗時接近一秒的三跳查詢的 profile 分析。我們發現在每一跳產出的記錄數量上,第一跳至第二跳擴散了 200 多倍,第二跳至第三跳擴散了 20 多倍,表現在結果上,需要計算的數據行數從 66 條直接躍升至 45 萬條,產出增長速度令人驚訝。此外,我們發現三跳算子在整個查詢過程中占據了較大的比重,其在查詢層的耗時更是占據了整個查詢的 80% 以上。
那麽應該如何進行最佳化呢?在資料庫效能最佳化方面,有許多可行的方案,主要分為三大類:儲存層的最佳化、查詢計劃的最佳化以及執行引擎的最佳化。
由於耗時大頭在查詢層,所以我們重點關註這塊。因為查詢計劃的最佳化是一個無止境的工程,使用者可能會寫出各種查詢語句,產生各種算子,難以找到一個通用且可收斂的方案來覆蓋所有情況。而執行引擎則可以有一個相對固定的最佳化方案,因此我們優先選擇了最佳化執行引擎。
圖資料庫的核心就是多跳查詢執行框架,而其由於數據量大,計算量大,導致查詢時間較長,因此我們借鑒了 MPP 資料庫和其他計算引擎的思想,提出了分布式並列查詢的解決方案。
2.5 原多跳查詢執行流程
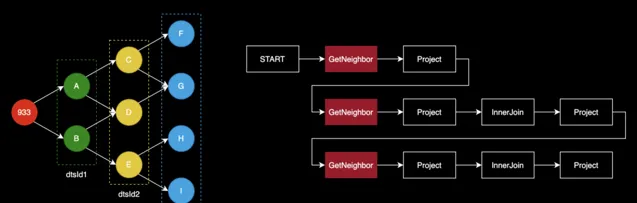
原有的多跳查詢執行流程如上圖所示。假設我們要查詢 933 頂點的三跳鄰居節點 ID,即檢索到藍圈中的所有頂點。經過查詢層處理後,將生成右圖所示執行計劃,START 表示計劃的起點,本身並無實際操作。GetNeighbor 算子則負責實際查詢頂點的鄰居,例如根據 933 找到 A 和 B。後續的 Project、InnerJoin 以及 Project 等操作均為對先前產生的結果進行數據結構的轉換、處理及裁剪等操作,以確保整個計算流程的順利進行。正是後續的這幾個算子耗費的時延較高。
2.6 可最佳化點分析
2.6.1 Barrier 等待使時延增加
從上述物理執行中可以看出:查詢節點必須等所有儲存節點的響應返回後,才會執行後面的算子。這樣即使大多數儲存節點很快返回,只要有一個「慢儲存節點」存在,整個查詢都得 block 住。
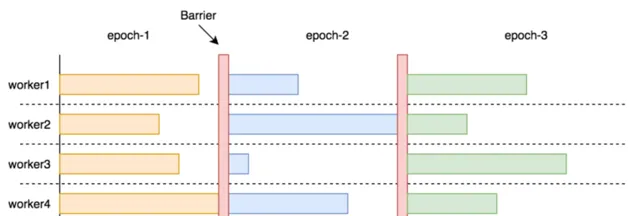
在圖計算(AP)場景中,一次計算往往要經過很多輪叠代(Epoch),並且每輪叠代後都需要進行全域指標的更新,更新完再繼續下一輪叠代。在 Epoch 之間插入 Barrier 做同步是有必要的。
但在圖查詢(TP)場景中,通常不需要全域性更新,只是在下發請求時對起點 ID 做去重,即使有往往也是在查詢的最後一步,因此沒有必要 barrier。
此外,圖資料庫負載往往呈現出「冪律分布」現象,即少數頂點鄰居邊多、多數頂點鄰居邊少;REDgraph 本身也是以邊切分的方式儲存數據,這就使得「慢儲存節點」很容易出現。加之某個儲存節點的網路抖動或節點負載高等因素,可能導致響應時間進一步延長,影響查詢效率。
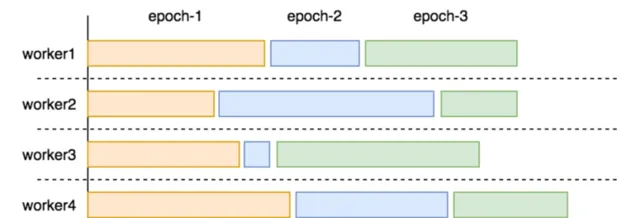
如圖所示,如果查詢層收到一個響應就處理一個響應(類似於 pipeline 的機制),則能避免無意義的空等,從整體上加速查詢的執行。
2.6.2 查詢層序列執行效率低
在整個查詢計劃中,只有 GetNeighbor 算子是在多個儲存節點上並列執行,而其他算子是在查詢節點上序列執行,這裏我們想到兩個問題:
序列執行的效率天然低於並列執行。只有在數據量太少或者計算邏輯太簡單的情況下,上下文切換的開銷會超過並列的收益。在正常負載的圖查詢場景中,數據量和計算邏輯都挺可觀;
當多個儲存節點的響應數據匯聚到查詢節點時,數據量仍然相當可觀。如果能在 storaged 節點上完成這些計算,將顯著減少查詢節點需要處理的數據量。
我們在業務的線上集群和效能測試顯示:GetNeighbors 和 GetVertices 不是所有算子中最耗時的,反倒是不起眼的 Project 算子往往耗費更多時間,特別是那些緊隨 GetNeighbors 和 GetVertices 之後的 Project 算子,因為它不僅需要執行數據投影,還負責將 map 展平。
這表明整個查詢的主要瓶頸在於計算量大。而查詢計劃中大部份都是純計算型算子,將它們並列化對於提升查詢效率很有必要。
2.6.3 查詢結果轉發浪費 IO
如上文所說,在圖查詢場景中一般不需要做全域性的更新,查詢節點收到各儲存節點的響應後,只是簡單地再次分區然後下發,所以儲存節點的結果轉發到查詢層,再從查詢節點分發到各儲存節點很浪費。
如果儲存節點自身具備路由和分發的能力,那可以讓儲存節點執行完 GetNeighbors 算子後,接著執行 Project、InnerJoin 等算子,每當遇到下一個 GetNeighbor 算子時,自行組織請求並分發給其他儲存節點。其他儲存節點收到後接著執行後面的算子,以此規則往復,直到最後一步將結果匯聚到查詢層,統一返回給客戶端。
2.7 改造後的執行流程
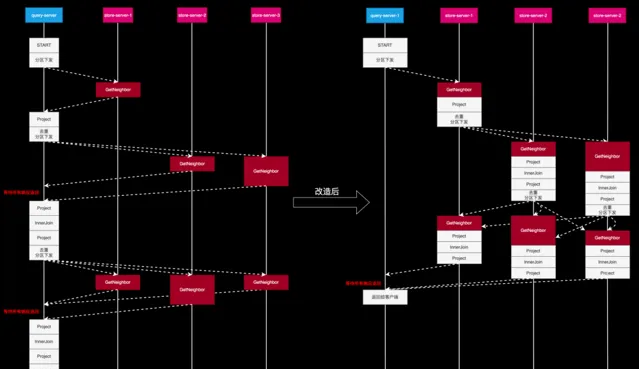
首先,查詢伺服器(Query Server)將整個執行計劃以及執行計劃所需的初始數據傳輸至儲存伺服器(Store Server),之後 Store Server 自身來驅動整個執行過程。以 Store Server 1 為例,當它完成首次查詢後,便會根據結果 ID 所在的分區,將結果轉發至相應的 Store Server。各個 Store Server 可以獨立地繼續進行後續操作,從而實作整個執行動作的並列化,並且無同步點,也無需額外轉發。
需要說明的是,圖中右側白色方框比左側要矮一些,這是因為數據由上方轉到下方時,進行了分區下發,必然比在查詢伺服器接收到的總數據量要少。
可以看到,在各部份獨立驅動後,並未出現等待或額外轉發的情況,Query Server 只需在最後一步收集各個 Store Server 的結果並聚合去重,然後返回給客戶端。如此一來,整體時間相較於原始模型得到了顯著縮短。

分布式並列查詢的具體實作,涉及到許多個關鍵點,接下來介紹其中一些細節。
3.1 如何保證不對 1-2 跳產生負最佳化

首先一個問題是,在進行改造時如何確保不會對原始的 1-2 跳產生負最佳化。在企業內部進行新的改造和最佳化時,必須謹慎評估所采取的措施是否會對原有方案產生負最佳化。我們不希望新方案還未能帶來收益,反而破壞了原有的系統。因此,架構總體上與原來保持一致。在 Store Server 內部插入了一層,稱為執行層,該層具有網路互聯功能,主要用於分布式查詢的轉發。Query Server 層則基本保持不變。
這樣,當接收到使用者的執行計劃後,便可根據其跳數選擇不同的處理路徑。若為 1 至 2 跳,則仍沿用原有的流程,因為原有的流程能夠滿足 1-2 跳的業務需求,而 3 跳及以上則采用分布式查詢。
3.2 如何與原有執行框架相容
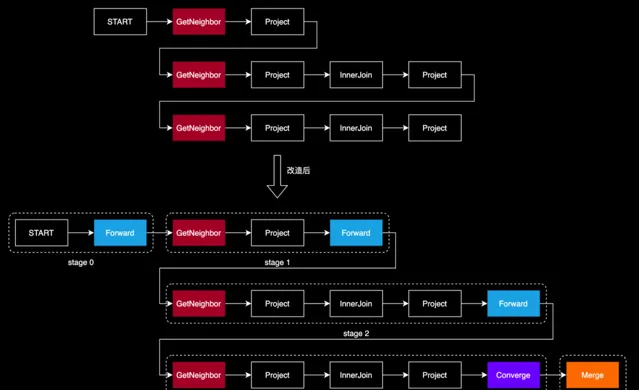
原有程式碼中每一個操作都是用算子方式實作。為了讓分布式並列查詢的實作與原有框架相容,我們把「轉發」也定義為一個算子,取名為 Forward。這一算子的功能類似於 Spark 中的 Shuffle 算子、或 OceanBase 中的 Exchange 算子,關鍵在於它能夠確保查詢在分布式環境中順暢執行。
我們對查詢計劃進行了以下關鍵覆寫:
在每個要「切換分區才能執行的」算子前(例如 GetNeighbors、GetVertices 等),我們添加一個 FORWARD 算子。FORWARD 算子負責記錄分區的依據,通常是起點 ID。
為了將分布式節點的查詢結果有效地匯總,我們在查詢計劃的末端添加了 CONVERGE 算子,它指示各節點將結果發送回 DistDriver 節點,即最初接收使用者請求的節點。
隨後,我們引入了 MERGE 算子,它的作用是對所有從節點收到的結果進行匯總,並將最終結果返回給客戶端。
透過這種方式,當 REDgraph-Server 準備執行 GetNeighbors、GetVertices 算子時,它會首先執行 FORWARD、CONVERGE算子,將必要的數據和查詢計劃轉發到其他伺服器。這樣,其他伺服器在接收到請求後,就能明確自己的任務和所需的數據,從而推動查詢計劃的執行。
值得註意的是,FORWARD 和 CONVERGE算子都有「轉發/發送」數據的含義,不過它們的側重點不太一樣:
FORWARD 強調的是路由轉發,並且要指定轉發的依據,即 partitionKey 欄位,不同的數據行會根據其 partitionKey 欄位值的不同轉發到不同的節點上;
CONVERGE 強調的是發送匯聚,具有單一確定的目標節點,即 DistDriver;
因它們只是在做轉發/發送的工作,我們將這類算子統稱為「路由」算子。
在改造後的查詢計劃中,從 START 算子開始,直到遇到「路由」算子,這多個算子都可以在某個節點本地執行的,因此我們將這一系列算子劃分到一個 stage 內。整個查詢計劃由多個 stage 組成,其中首尾兩個 stage 在 DistDriver 上執行,中間的 stage 在 DistWorker 上執行。
需要註意的是:stage 是一個邏輯概念,具體執行時,每個 stage 會依據分區和所屬節點產生多個 task,這些 task 會分布在多個節點上執行,每個節點僅存取本節點內數據,無需跨網路拉取數據。這種結構化的方法極大地提高了查詢的並列性和效率。
3.3 如何做熱點處理
在原查詢模式中,每一次在發起 GetNeighbors 算子前,查詢層會對起點 ID 去重(查詢計劃中 GetNeighbors 算子的 dedup 為 true),收到儲存節點的響應後,再依靠後續算子將結果按需展平,因此儲存節點不會產生重復查詢。以下圖舉例說明:
原查詢模式的執行流程可簡單描述為:
第一跳從儲存層查到 A->C 和 B->C,返回到查詢層;
查詢層會 Project 得到兩個 C,以備後面做 InnerJoin;
準備執行第二跳,構造起點集合時,由於 dedup 為 true,僅會保留一個 C;
第二跳從儲存層查到 C->D 和 C->E,返回到查詢層;
查詢層執行 InnerJoin,由於此前有兩個 C,所以 C->D 和 C->E 也各會變成兩個;
查詢層再次 Project 取出 dstId2,得到結果 D、D、E、E。
從步驟 4 可以看到,儲存層不會產生重復查詢。
改造成分布式查詢後,我們只能在每個 stage 內去重。但由於缺乏全域 barrier,多個 stage 先後往某個 DistWorker 轉發請求時,多個請求之間可能有重復的起點,會在儲存層產生重復查詢和計算,導致 CPU 開銷增加以及查詢時延增加。
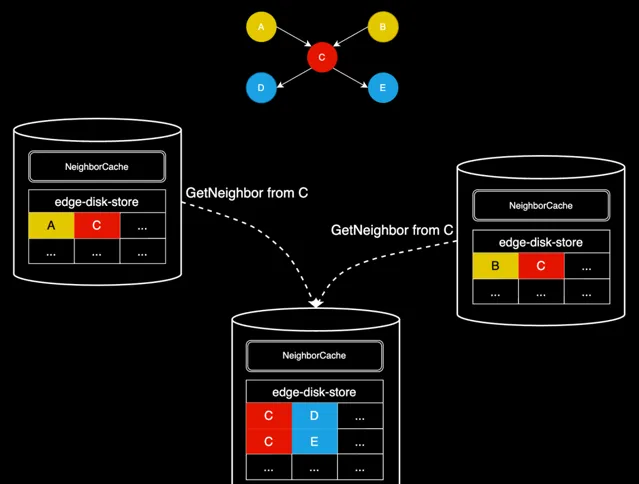
如果每一跳產生的重復終點 ID(將會作為下一跳的起點 ID)很多,分布式查詢反而會帶來劣勢。為解決這一問題,我們引入一套起點 ID 去重機制 —— NeighborCache,具體方案如下:
因為沒有全域的 Barrier,無法在下發請求之前去重,我們選擇在儲存節點上提供一個 NeighborCache,其本質就是一個 map,可表示為 map<vid +="" edgetype,="" list>。在執行 GetNeighbors 算子前,儲存節點會首先檢查 NeighborCache,如果找到相應的條目,則直接使用這些數據填充結果集;如果沒有找到,則存取儲存層獲取數據,並更新 NeighborCache,讀取和更新 Cache 需要用讀寫鎖做好互斥。
另外,NeighborCache 還具有如下特點:
每當有更新 vid + edgeType 的請求時,都會先 invalidate cache 中對應的條目,以此來保證緩存與數據的一致性;
即使沒有更新操作存在,cache 內的每個 kv 條目存活時間也很短,通常為秒級,超過時間就會被自動刪除。為什麽這麽短呢?
充分性:由於線上圖查詢(OLTP)的特性,使用者的多跳查詢通常在幾秒到十幾秒內完成。而 NeighborCache 只是為了去重而設計,來自於不同 DistWorker 的 GetNeighbors 請求大機率不會相隔太長時間到達,所以 cache 本身也不需要存活太久;
必要性:從 map 結構的 key 就會發現,當 qps 較高,跳數多,頂點的鄰居邊多時,此 map 要承載的數據量是非常大的,所以也不能讓其存活的時間太久,否則很容易 OOM;
在填充 cache 前會做記憶體檢查,如果本節點當前的記憶體水位已經比較高,則不會填充,以避免節點 OOM。
透過這種起點 ID 去重機制,我們能夠有效地減少重復查詢,提高分布式查詢的效率和效能。
3.4 如何做負載均衡
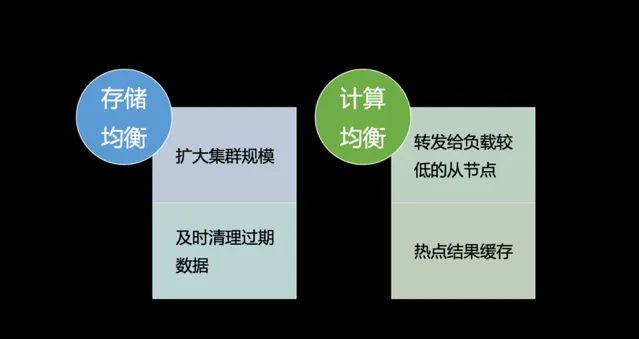
第四個問題是怎麽做負載均衡,包括儲存的均衡和計算的均衡。
首先,儲存的均衡在以邊切分的圖儲存裏面其實是很難的,因為它天然的就是把頂點和其鄰居全部都存在了一起,這是圖資料庫相比其他資料庫的優勢,也是其要承擔的代價。所以目前沒有一個徹底的解決方法,只能在真的碰到此問題時擴大集群規模,讓數據的哈希打散能夠更加均勻一些,避免多個熱點都落在同一個機器的情況。而在目前的業務場景上來看,其實負載不均衡的現象不算嚴重,例如風控的一個比較大的集群,其磁盤用量最高和最低的也不超過 10%,所以問題其實並沒有想象中的那麽嚴重。
另外一個最佳化方法是在儲存層及時清理那些過期的數據,清理得快的話也可以減少一些不均衡。
計算均衡的問題。儲存層采用了三副本的策略,若業務能夠接受弱一致的讀取(實際上大多數業務均能接受),我們可以在請求轉發時,檢視三副本中的哪個節點負載較輕,將請求轉發至該節點,以盡量平衡負載。此外,正如前文所述,熱點結果緩存也是一種解決方案,只要熱點處理速度足夠快,計算的不均衡現象便不易顯現。
3.5 如何做流程控制
在分布式查詢架構中,由於前面取消全域 Barrier,使得各個 DistWorker 自行驅動查詢的進行。這種設計提高了靈活性,但也帶來新的挑戰:
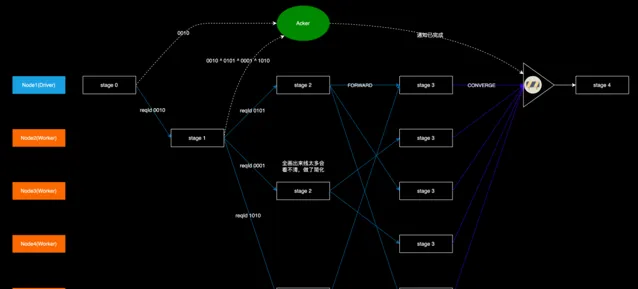
如圖所示,各個 DistWorker 上 stage3 的結果需要匯聚到 DistDriver 後才能向客戶端返回,但是 DistDriver 只在 stage0 的時候給 Node2 發送了請求,後面的所有轉發都是由 DistWorker 自行完成的,脫離了 DistDriver 的「掌控」。這樣 DistDriver 就不知道最後有多少個節點在執行 stage3,也就不知道該等待哪些 DistWorker 給它發送結果,以及何時可以開始執行 stage4。
我們引入一個進度匯報機制:在 DistDriver 上實作一個 Acker,負責接收各個 DistWorker 上報的 stage 執行進度資訊。每個 stage 向外擴散時,向 Acker 發送一條訊息,記錄當前完成的 stage 和 即將開始的 stage 的節點數量。具體而言,就是包含兩個鍵值對:
當前的 stage 編號 -> -1;
下一個 stage 的編號 -> 執行下一個 stage 的節點的數量;
比如 Node2 上的 stage-1 擴散到 stage-2 時,目標節點有 3 個:Node1、Node3、Node5,於是就發送 {stage-1: -1,stage-2: 3} 的訊息到 DistDriver 上,表示有一個節點完成了 stage-1,有 3 個節點開始了 stage-2。而由於 stage-1 此前由 Node1 登記過 {stage-1: 1},這樣一正一負就表示所有的 stage-1 都已經執行完畢。stage-2 和 stage-3 的更新和判定方式類似,當 DistDriver 發現所有的前置 stage 數量都為 0 時,就可以驅動 stage-4 。
我們實際想要的是每個 stage 數量的正負抵消能力,而非 {stage-1: -1,stage-2: 3} 的字串。為了簡化這一過程,我們便采用異或運算(相同為 0,相異為 1)跟蹤各個 stage 的狀態,舉例說明:
Acker 上有一個初始的 checksum 值 0000;
stage-0 在擴散到 stage-1 時,生成了一個隨機數 0010(這裏為了表達簡便,以 4 位二進制數代替),這個 0010 是 Node2 上的 stage-1 的 Id,然後把這個 0010 伴隨著 Forward 請求發到 Node2 上,同時也發到 Acker 上,這樣就表示 0010 這個 stage 開始了,Acker 把收到的值與原生的 checksum 做異或運算,得到 0010,並以此更新本地 checksum;
stage-1 執行完後擴散到 stage-2 時,由於有 3 個目標節點,就生成 3 個不相同的隨機數 0101、0001、1010(需要檢查這 3 個數異或之後不為 0),分別標識 3 個目標節點上的 stage-2,然後把這 3 個數伴隨著 Forward 請求發到 Node1、Node3、Node5 上,同時在本地把自身的 stage Id(0010)和這 3 個數一起做異或運算,再把運算的結果發到 Acker,Acker 再次做異或運算,也就是 0010 ^ (0010 ^ 0101 ^ 0001 ^ 1010),這樣 0010 就被消除掉了,也就表示 stage-1 執行完成了;
重復上述過程,最後 Acker 上的 checksum 會變回 0,表示可以驅動 stage-4。
註意:盡管在某個節點的 stage 擴散時檢查了生成的隨機數異或不為 0,但是多個節點間生成的隨機數異或到一起還是可能為 0 的,比如 Node1 的 stage-2 生成的 3 個數異或後為 0001,Node3 的 stage-2 異或後為 0010,Node5 的 stage-2 異或後為 0011,0001 ^ 0010 ^ 0011 = 0。這樣就會導致 stage-3 還在執行中時,DistDriver 就誤認為它已經執行完畢,提前驅動 stage-4 的執行。
不過考慮到我們實際使用的是 int32 整數,出現這種的情況的機率非常低。在未來的最佳化中在,我們可以考慮給每個 Node 生成一個 16 位的隨機 Id(由 metad 生成),並保證這些 NodeId 異或結果不為 0,當 stage 擴散時,將 NodeId 置於隨機數的高位,確保分布式查詢的每個階段都能被準確跟蹤和協調。
另一個重要的問題便是全程鏈路的超時自檢,例如在 stage2 或 stage3 的某一個節點上執行時間過長,此時不能讓其余所有節點一直等待,因為客戶端已經超時了。因此我們在每個算子內部的執行邏輯中都設定了一些埋點,用以檢查算子的執行是否超過了使用者側的限制時間,一旦超過,便立即終止自身的執行,從而迅速地自我銷毀,避免資源的無謂浪費。

我們在改造工程完成後進行了效能測試,采用 LDBC 組織提供的 SNB 數據集,生成了一個 SF100 級別的社群網路圖譜,規模達到 3 億頂點,18 億條邊。我們主要考察其一跳、二跳、三跳、四跳等多項查詢效能。
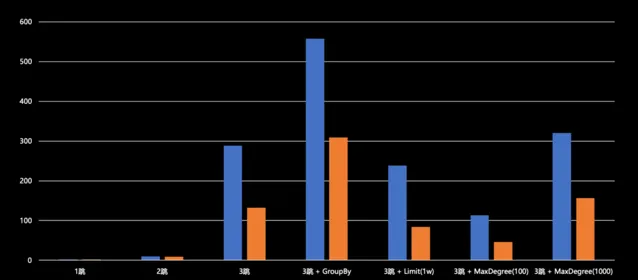
根據測試結果顯示,在一跳和二跳情況下,原生查詢和分布式查詢效能基本相當,未出現負最佳化現象。從三跳起,分布式查詢相較於原生查詢能實作 50% 至 60% 的效能提升。例如,在 Max degree 場景下的分布式查詢已將時延控制在 50 毫秒以內。在帶有 Max degree 或 Limit 值的情況下,時延均在 200 毫秒以下。盡管數據集與實際業務數據集存在差異,但它們皆屬於社群網路領域,因此仍具有一定的參考價值。
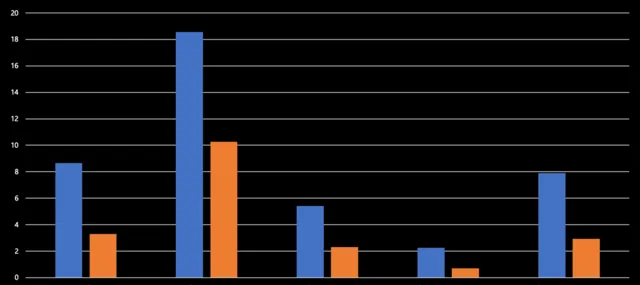
四跳查詢,無論是原始查詢還是分布式查詢,其時延的規模基本上都在秒至十余秒的範圍內。因為四跳查詢涉及的數據量實在過於龐大,已達到百萬級別,僅依賴分布式並列查詢難以滿足需求,因此需要采取其他策略。然而,即便如此,我們所提出的改進方案相較於原始查詢模式仍能實作 50% 至 70% 的提升,效果還是很可觀的。

在過去的較短時間內,我們基於 MPP 的理念,對 REDgraph 在分布式並列查詢上進行了深入探索和實踐。本方案能顯著最佳化多跳查詢的效能,並且對業務邏輯完全相容,沒有使用限制條件,屬於框架級的通用最佳化。測試結果顯示,時延降低了 50% 以上,滿足線上業務場景的時延要求,驗證方案的有效性。
目前,許多公司的圖資料庫產品在線上場景中仍使用兩跳及以下的查詢。這是因為多跳查詢的時延無法滿足線上業務的要需求,導致失去許多潛在的業務價值,也未能充分發揮圖資料庫的技術優勢。隨著小紅書 DAU 的持續增長,業務數據規模朝著萬億級規模遞增,業務上使用替代方案的瓶頸會逐漸展露。我們計劃在今年上半年完成開發工作,並在下半年開始將這套新架構逐步套用於相關業務場景。
本方案雖然針對的是圖資料庫,但其探索實踐對公司其他資料庫產品同樣具有重要的參考價值。例如,REDtable 在處理使用者請求時,經常需要應對復雜或計算量大的查詢,以往會建議使用者修改程式碼來適應這些情況。現在,我們可以借鑒本方案,為這些「具有重查詢需求」產品打造高效能執行框架,以增強自身的數據處理能力。
我們將繼續提升 REDgraph 的多跳查詢能力,並將其和 REDtao 融合,打造成一個統一的資料庫產品,賦能更多業務場景。我們誠邀對技術有極致追求,誌同道合的同學一起加入團隊,共同推動圖數據技術的發展。

再興
小紅書基礎架構儲存組工程師, 負責自研分布式表格儲存 REDtable(NewSQL),參與分布式圖資料庫 REDgraph 的研發。
敬德
小紅書基礎架構儲存組工程師, 負責自研圖儲存系統 REDtao 和分布式圖資料庫 REDgraph。
劉備
小紅書基礎架構儲存組負責人, 負責 REDkv / Redis / REDtao / REDtable / REDgraph / MySQL 的整體架構和技術演進。

基礎架構 - 儲存崗位
工作職責:
打造優秀的分布式 KV 儲存系統、分布式緩存、圖資料庫、表格儲存,為公司海量數據和大規模業務系統提供可靠的基礎設施;
解決線上系統的疑難問題, 能從業務問題中抽象出通用的解決方案, 並落地實作;
團隊密切配合, 共同研究和使用業內各方向最新技術,共同推動公司技術演進。
任職資格:
有 C/C++ 開發經驗,精通多執行緒編程,有高並行場景下的產品設計和實作;
掌握分布式系統基本原理,了解 Paxos 、Raft 等一致性協定原理及套用,熟悉 RocksDB 等單機儲存引擎的使用及最佳化;
熟悉演算法和數據結構,解決問題思路清晰,對問題有深入鉆研的興趣;
對系統設計有完美追求, 對編碼保持熱情。
加分項:
有 rocksdb 、redis 、tidb 、nebula 、Lindom 等 KV / 圖 / 表格資料庫使用和開發、最佳化經驗優先;
對開源計畫有深入學習或參與的優先。
歡迎感興趣的朋友發送簡歷至: [email protected];
並抄送至: [email protected]、 [email protected]
IT交流群
組建了程式設計師,架構師,IT從業者交流群,以
交流技術
、
職位內推
、
行業探討
為主
加小編 好友 ,備註"加群"











