
今天給大家分享幾個SQL常見的「壞毛病」及最佳化技巧。
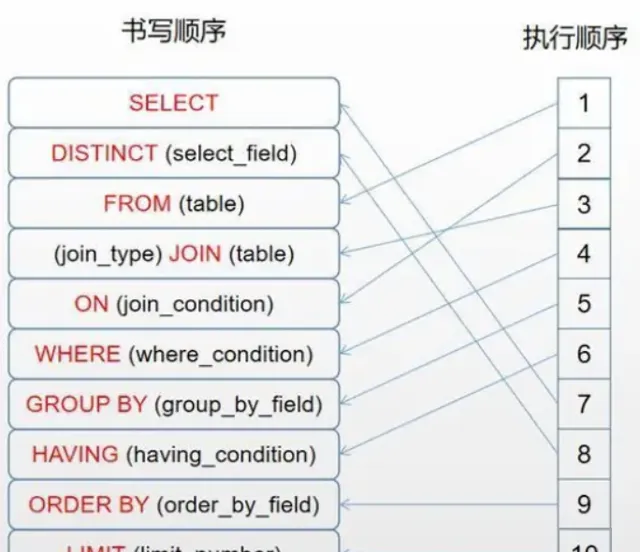
SQL語句的執行順序:
1、LIMIT 語句
分頁查詢是最常用的場景之一,但也通常也是最容易出問題的地方。比如對於下面簡單的語句,一般 DBA 想到的辦法是在 type、 name、 create_time 欄位上加組合索引。這樣條件排序都能有效的利用到索引,效能迅速提升。
SELECT *
FROM operation
WHEREtype = 'SQLStats'
ANDname = 'SlowLog'
ORDERBY create_time
LIMIT1000, 10;
好吧,可能90%以上的 DBA 解決該問題就到此為止。但當 LIMIT 子句變成 「
LIMIT 1000000,10
」 時,程式設計師仍然會抱怨:我只取10條記錄為什麽還是慢?
要知道資料庫也並不知道第1000000條記錄從什麽地方開始,即使有索引也需要從頭計算一次。出現這種效能問題,多數情形下是程式設計師偷懶了。
在前端數據瀏覽翻頁,或者大數據分批匯出等場景下,是可以將上一頁的最大值當成參數作為查詢條件的。SQL 重新設計如下:
SELECT *
FROM operation
WHEREtype = 'SQLStats'
ANDname = 'SlowLog'
AND create_time > '2017-03-16 14:00:00'
ORDERBY create_time limit10;
在新設計下查詢時間基本固定,不會隨著數據量的增長而發生變化。
2、隱式轉換
SQL語句中查詢變量和欄位定義型別不匹配是另一個常見的錯誤。比如下面的語句:
mysql> explainextendedSELECT *
> FROM my_balance b
> WHERE b.bpn = 14000000123
> AND b.isverified ISNULL ;
mysql> showwarnings;
| Warning | 1739 | Cannot userefaccessonindex'bpn' due totypeorcollation conversion onfield'bpn'
其中欄位 bpn 的定義為
varchar(20)
,MySQL 的策略是將字串轉換為數位之後再比較。函式作用於表欄位,索引失效。
上述情況可能是應用程式框架自動填入的參數,而不是程式設計師的原意。現在套用框架很多很繁雜,使用方便的同時也小心它可能給自己挖坑。
3、關聯更新、刪除
雖然 MySQL5.6 引入了物化特性,但需要特別註意它目前僅僅針對查詢語句的最佳化。對於更新或刪除需要手工重寫成 JOIN。
比如下面 UPDATE 語句,MySQL 實際執行的是迴圈/巢狀子查詢(
DEPENDENT SUBQUERY
),其執行時間可想而知。
UPDATE operation o
SETstatus = 'applying'
WHERE o.id IN (SELECTid
FROM (SELECT o.id,
o.status
FROM operation o
WHERE o.group = 123
AND o.status NOTIN ( 'done' )
ORDERBY o.parent,
o.id
LIMIT1) t);
執行計劃:
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
| 1 | PRIMARY | o | index | | PRIMARY | 8 | | 24 | Using where; Using temporary |
| 2 | DEPENDENT SUBQUERY | | | | | | | | Impossible WHERE noticed after reading const tables |
| 3 | DERIVED | o | ref | idx_2,idx_5 | idx_5 | 8 | const | 1 | Using where; Using filesort |
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
重寫為 JOIN 之後,子查詢的選擇模式從
DEPENDENT SUBQUERY
變成
DERIVED
,執行速度大大加快,從7秒降低到2毫秒。
UPDATE operation o
JOIN (SELECT o.id,
o.status
FROM operation o
WHERE o.group = 123
AND o.status NOTIN ( 'done' )
ORDERBY o.parent,
o.id
LIMIT1) t
ON o.id = t.id
SETstatus = 'applying'
執行計劃簡化為:
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
| 1 | PRIMARY | | | | | | | | Impossible WHERE noticed after reading const tables |
| 2 | DERIVED | o | ref | idx_2,idx_5 | idx_5 | 8 | const | 1 | Using where; Using filesort |
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
4、混合排序
MySQL 不能利用索引進行混合排序。但在某些場景,還是有機會使用特殊方法提升效能的。
SELECT *
FROM my_order o
INNERJOIN my_appraise a ON a.orderid = o.id
ORDERBY a.is_reply ASC,
a.appraise_time DESC
LIMIT0, 20
執行計劃顯示為全表掃描:
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+
| 1 | SIMPLE | a | ALL | idx_orderid | NULL | NULL | NULL | 1967647 | Using filesort |
| 1 | SIMPLE | o | eq_ref | PRIMARY | PRIMARY | 122 | a.orderid | 1 | NULL |
+----+-------------+-------+--------+---------+---------+---------+-----------------+---------+-+
由於
is_reply
只有0和1兩種狀態,我們按照下面的方法重寫後,執行時間從1.58秒降低到2毫秒。
SELECT *
FROM ((SELECT *
FROM my_order o
INNERJOIN my_appraise a
ON a.orderid = o.id
AND is_reply = 0
ORDERBY appraise_time DESC
LIMIT0, 20)
UNIONALL
(SELECT *
FROM my_order o
INNERJOIN my_appraise a
ON a.orderid = o.id
AND is_reply = 1
ORDERBY appraise_time DESC
LIMIT0, 20)) t
ORDERBY is_reply ASC,
appraisetime DESC
LIMIT20;
5、EXISTS語句
MySQL 對待 EXISTS 子句時,仍然采用巢狀子查詢的執行方式。如下面的 SQL 語句:
SELECT *
FROM my_neighbor n
LEFTJOIN my_neighbor_apply sra
ON n.id = sra.neighbor_id
AND sra.user_id = 'xxx'
WHERE n.topic_status < 4
ANDEXISTS(SELECT1
FROM message_info m
WHERE n.id = m.neighbor_id
AND m.inuser = 'xxx')
AND n.topic_type <> 5
執行計劃為:
+----+--------------------+-------+------+-----+------------------------------------------+---------+-------+---------+ -----+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+-------+------+ -----+------------------------------------------+---------+-------+---------+ -----+
| 1 | PRIMARY | n | ALL | | NULL | NULL | NULL | 1086041 | Using where |
| 1 | PRIMARY | sra | ref | | idx_user_id | 123 | const | 1 | Using where |
| 2 | DEPENDENT SUBQUERY | m | ref | | idx_message_info | 122 | const | 1 | Using index condition; Using where |
+----+--------------------+-------+------+ -----+------------------------------------------+---------+-------+---------+ -----+
去掉 exists 更改為 join,能夠避免巢狀子查詢,將執行時間從1.93秒降低為1毫秒。
SELECT *
FROM my_neighbor n
INNERJOIN message_info m
ON n.id = m.neighbor_id
AND m.inuser = 'xxx'
LEFTJOIN my_neighbor_apply sra
ON n.id = sra.neighbor_id
AND sra.user_id = 'xxx'
WHERE n.topic_status < 4
AND n.topic_type <> 5
新的執行計劃:
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
| 1 | SIMPLE | m | ref | | idx_message_info | 122 | const | 1 | Using index condition |
| 1 | SIMPLE | n | eq_ref | | PRIMARY | 122 | ighbor_id | 1 | Using where |
| 1 | SIMPLE | sra | ref | | idx_user_id | 123 | const | 1 | Using where |
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
6、條件下推
外部查詢條件不能夠下推到復雜的檢視或子查詢的情況有:
聚合子查詢;
含有 LIMIT 的子查詢;
UNION 或 UNION ALL 子查詢;
輸出欄位中的子查詢;
如下面的語句,從執行計劃可以看出其條件作用於聚合子查詢之後:
SELECT *
FROM (SELECT target,
Count(*)
FROM operation
GROUPBY target) t
WHERE target = 'rm-xxxx'
+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+
| 1 | PRIMARY | <derived2> | ref | <auto_key0> | <auto_key0> | 514 | const | 2 | Usingwhere |
| 2 | DERIVED | operation | index | idx_4 | idx_4 | 519 | NULL | 20 | Usingindex |
+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+
確定從語意上查詢條件可以直接下推後,重寫如下:
SELECT target,
Count(*)
FROM operation
WHERE target = 'rm-xxxx'
GROUPBY target
執行計劃變為:
+----+-------------+-----------+------+---------------+-------+---------+-------+------+--------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+-------+---------+-------+------+--------------------+
| 1 | SIMPLE | operation | ref | idx_4 | idx_4 | 514 | const | 1 | Using where; Using index |
+----+-------------+-----------+------+---------------+-------+---------+-------+------+--------------------+
關於 MySQL 外部條件不能下推的詳細解釋說明請參考:
http://mysql.taobao.org/monthly/2016/07/08
7、提前縮小範圍
先上初始 SQL 語句:
SELECT *
FROM my_order o
LEFTJOIN my_userinfo u
ON o.uid = u.uid
LEFTJOIN my_productinfo p
ON o.pid = p.pid
WHERE ( o.display = 0 )
AND ( o.ostaus = 1 )
ORDERBY o.selltime DESC
LIMIT0, 15
該SQL語句原意是:先做一系列的左連線,然後排序取前15條記錄。從執行計劃也可以看出,最後一步估算排序記錄數為90萬,時間消耗為12秒。
+----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+
| 1 | SIMPLE | o | ALL | NULL | NULL | NULL | NULL | 909119 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | u | eq_ref | PRIMARY | PRIMARY | 4 | o.uid | 1 | NULL |
| 1 | SIMPLE | p | ALL | PRIMARY | NULL | NULL | NULL | 6 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+
由於最後 WHERE 條件以及排序均針對最左主表,因此可以先對
my_order
排序提前縮小數據量再做左連線。SQL 重寫後如下,執行時間縮小為1毫秒左右。
SELECT *
FROM (
SELECT *
FROM my_order o
WHERE ( o.display = 0 )
AND ( o.ostaus = 1 )
ORDERBY o.selltime DESC
LIMIT0, 15
) o
LEFTJOIN my_userinfo u
ON o.uid = u.uid
LEFTJOIN my_productinfo p
ON o.pid = p.pid
ORDERBY o.selltime DESC
limit0, 15
再檢查執行計劃:子查詢物化後(
select_type=DERIVED
)參與 JOIN。雖然估算行掃描仍然為90萬,但是利用了索引以及 LIMIT 子句後,實際執行時間變得很小。
+----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 15 | Using temporary; Using filesort |
| 1 | PRIMARY | u | eq_ref | PRIMARY | PRIMARY | 4 | o.uid | 1 | NULL |
| 1 | PRIMARY | p | ALL | PRIMARY | NULL | NULL | NULL | 6 | Using where; Using join buffer (Block Nested Loop) |
| 2 | DERIVED | o | index | NULL | idx_1 | 5 | NULL | 909112 | Using where |
+----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+
8、中間結果集下推
再來看下面這個已經初步最佳化過的例子(左連線中的主表優先作用查詢條件):
SELECT a.*,
c.allocated
FROM (
SELECT resourceid
FROM my_distribute d
WHERE isdelete = 0
AND cusmanagercode = '1234567'
ORDERBY salecode limit20) a
LEFTJOIN
(
SELECT resourcesid, sum(ifnull(allocation, 0) * 12345) allocated
FROM my_resources
GROUPBY resourcesid) c
ON a.resourceid = c.resourcesid
那麽該語句還存在其它問題嗎?不難看出子查詢 c 是全表聚合查詢,在表數量特別大的情況下會導致整個語句的效能下降。
其實對於子查詢 c,左連線最後結果集只關心能和主表 resourceid 能匹配的數據。因此我們可以重寫語句如下,執行時間從原來的2秒下降到2毫秒。
SELECT a.*,
c.allocated
FROM (
SELECT resourceid
FROM my_distribute d
WHERE isdelete = 0
AND cusmanagercode = '1234567'
ORDERBY salecode limit20) a
LEFTJOIN
(
SELECT resourcesid, sum(ifnull(allocation, 0) * 12345) allocated
FROM my_resources r,
(
SELECT resourceid
FROM my_distribute d
WHERE isdelete = 0
AND cusmanagercode = '1234567'
ORDERBY salecode limit20) a
WHERE r.resourcesid = a.resourcesid
GROUPBY resourcesid) c
ON a.resourceid = c.resourcesid
但是子查詢 a 在我們的SQL語句中出現了多次。這種寫法不僅存在額外的開銷,還使得整個語句顯的繁雜。使用 WITH 語句再次重寫:
WITH a AS
(
SELECT resourceid
FROM my_distribute d
WHERE isdelete = 0
AND cusmanagercode = '1234567'
ORDERBY salecode limit20)
SELECT a.*,
c.allocated
FROM a
LEFTJOIN
(
SELECT resourcesid, sum(ifnull(allocation, 0) * 12345) allocated
FROM my_resources r,
a
WHERE r.resourcesid = a.resourcesid
GROUPBY resourcesid) c
ON a.resourceid = c.resourcesid
總結
資料庫編譯器產生執行計劃,決定著SQL的實際執行方式。但是編譯器只是盡力服務,所有資料庫的編譯器都不是盡善盡美的。 上述提到的多數場景,在其它資料庫中也存在效能問題。了解資料庫編譯器的特性,才能避規其短處,寫出高效能的SQL語句。 程式設計師在設計數據模型以及編寫SQL語句時,要把演算法的思想或意識帶進來。
編寫復雜SQL語句要養成使用 WITH 語句的習慣。簡潔且思路清晰的SQL語句也能減小資料庫的負擔 。
來源:developer.aliyun.com/article/72501
>>
END
精品資料,超贊福利,免費領
微信掃碼/長按辨識 添加【技術交流群】
群內每天分享精品學習資料

最近開發整理了一個用於速刷面試題的小程式;其中收錄了上千道常見面試題及答案(包含基礎、並行、JVM、MySQL、Redis、Spring、SpringMVC、SpringBoot、SpringCloud、訊息佇列等多個型別),歡迎您的使用。
👇👇
👇點選"閱讀原文",獲取更多資料(持續更新中)











