
字節跳動大模型團隊成果 Depth Anything V2 現已被蘋果官方收入 Core ML 模型庫。 本文介紹了 Depth Anything 系列成果的研發歷程、技術挑戰與解決方法,分享了團隊對於 Scaling Laws 在單一視覺任務方面的思考。值得一提的是,Depth Anything V1 與 V2 兩個版本論文一作是團隊實習生。
近日,
字節跳動
大模型
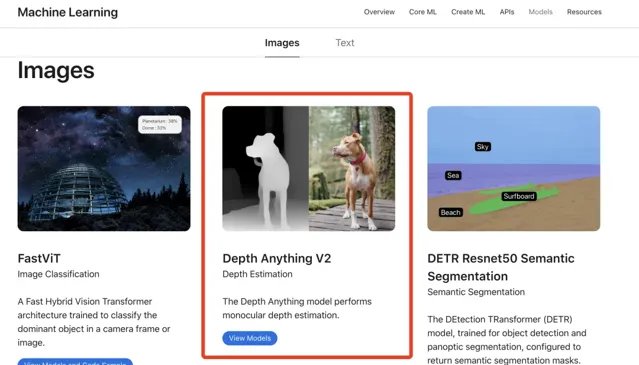
團隊開發的成果 Depth Anything V2 ,入選蘋果公司 Core
ML
模型庫,目前已呈現在開發者相關頁面中。
Depth Anything 是一種單目深度估計模型,V1 版本釋出於 2024 年初,V2 版本釋出於 2024 年 6 月,包含 25M 到 1.3B 參數的不同大小模型,可套用於視訊特效、自動駕駛、3D 建模、增強現實、安全監控以及空間計算等領域。
相比上一代版本,V2 版在細節處理上更精細,魯棒性更強,並且對比基於 Diffusion 的 SOTA 模型,速度上有顯著提升。
目前 Github 上該系列成果總計收獲 8.7k Star。其中,Depth Anything V2 釋出不久,已有 2.3k star ,更早版本 Depth Anything V1 收獲 6.4k Star。 值得一提的是,Depth Anything V1 與 V2 兩個版本論文一作是團隊實習生。
更多模型 效果,點選下方視訊了解:
本次蘋果公司收錄的 Depth Anything V2 為 Core ML 版本。作為該公司的機器學習框架,Core ML 旨在將機器學習模型整合到 iOS,MacOS 等裝置上高效執行,可在無互聯網連線情況下,執行復雜 AI 任務,從而增強使用者私密並減少延遲。
Core ML 版本 Depth Anything V2 采用最小 25M 模型,經 HuggingFace 官方工程最佳化,在 iPhone 12 Pro Max 上,推理速度達到 31.1 毫秒。與其一同入選的模型還有 FastViT 、ResNet50 、YOLOv3 等,涵蓋自然語言處理到影像辨識多個領域。
相關論文與更多效果展示:
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
論文連結:https://arxiv.org/abs/2401.10891
效果展示:https://depth-anything.github.io/
Depth Anything V2
論文連結:https://arxiv.org/abs/2406.09414
效果展示:https://depth-anything-v2.github.io/
0 1
Scaling Laws 對單一視覺任務的啟示
隨著近兩年大模型潮湧,Scaling Laws 的價值也被越來越多人認同。身處其中,有的研究團隊致力於研發一個模型,以實作目標檢測、影像分割等多種視覺任務,Depth Anything 團隊選擇了另一個方向——
依托 Scaling Laws 思路,構建一個簡單但功能強大的基礎模型,在單一任務上實作更好效果。
對於上述選擇,團隊同學解釋道,此前大家也曾考慮研究一個大模型去解決多個任務,但從結果看,實際效果只能達到 70 - 80 分水平,但在時間成本、算力成本方面消耗量較大。
從落地角度出發,團隊認為,利用 Scaling Laws 解決一些基礎問題更具實際價值。
關於為什麽選擇深度估計任務,成員介紹道,如果將電腦視覺領域的任務進行分類,文本描述、影像分類等任務均需要有人參與,才有意義。與之相對,邊緣檢測、光流法運動檢測等任務中,相關訊號本身就客觀存在,結果評價也不需要人類參與。深度估計(Depth Estimation)便可歸為此類,相比其他任務,該任務更為「基礎」,關聯落地場景也較多。
作為電腦視覺領域中的重要任務之一,深度估計旨在從影像中推斷出場景內物體的距離資訊,套用包括自動駕駛、3D 建模、增強現實等。
此外,深度估計模型還可以作為中介軟體,整合進視訊平台或剪輯軟體中,以支持特效制作、視訊編輯等功能。目前,已有下遊 B 端使用者將 Depth Anything V2 內建進產品當中。
註:下遊使用者 Quick Depth 將 Depth Anything V2 內建進產品的效果
02
Depth Anything V1 訓練過程
Depth Anything 從立項到 V2 版本釋出並被蘋果選入 Core ML,歷經一年左右時間。據成員分享,這當中,最困難部份在於兩方面:
如何訓練模型,以達到並超過已有成果水平;
讓模型在細節方面有更好表現;
上述兩個問題分別匯出了 Depth Anything 的 V1 和 V2 版本,我們不妨先從訓練模型說起。
事實上,Depth Anything 出現前,MiDaS 已能較好解決深度估計問題。
MiDaS 是一種穩健的單目深度估計模型,相關論文於 2019 年首次送出 ArXiv ,很快中選電腦視覺和人工智慧領域頂級國際期刊 TPAMI 。但該模型只開源了模型本身,卻未開源訓練方法。
為實作訓練過程,團隊主要做了如下努力。
一、專門設計了一個數據引擎,收集並自動標註大量數據
該方面努力大大擴充套件了數據覆蓋範圍,減小泛化誤差。數據增強工具的引入使得模型可主動尋求額外視覺知識,並獲得穩健的表示能力。
值得一提的是,起初模型的自訓練 Pipeline 並未獲得較大提升。團隊推測,可能是所用標註數據集內已有相當數量的影像,模型沒能從未標註數據獲得大量知識。
於是,他們轉而以一個更困難的最佳化目標挑戰學生模型:在訓練過程中,對無標註影像加入強擾動(顏色失真和空間失真),迫使學生模型主動尋求額外視覺知識。
二、透過預訓練編碼器,促使模型繼承豐富的語意先驗知識
理論上,高維語意資訊對於深度估計模型有益,來自其他任務中的輔助監督訊號對於偽深度標簽有對抗作用。於是,團隊便在一開始嘗試透過 RAM+GroundingDINO+HQ-SAM 模型組合為無標註影像分配語意標簽,但效果有限。團隊推測,該現象源於影像解碼為離散類空間過程中,損失了大量語意資訊。
經過一段時間嘗試,團隊轉而引入了基於預訓練編碼器的知識蒸餾,促使模型從中繼承豐富的語意先驗知識,進一步彌補數據標註量比較少的問題。
訓練 Pipeline 如下圖,實線為有標註影像流,虛線為無標註的影像流,S 表示加入的強擾動。同時,為了讓模型擁有豐富的先驗語意知識,團隊在凍結編碼器(Encoder)與線上學生模型之間強制執行了輔助約束,以保留語意能力。
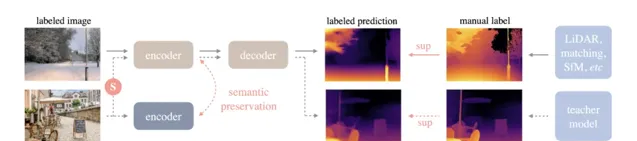
註:Depth Anything Pipeline 展示
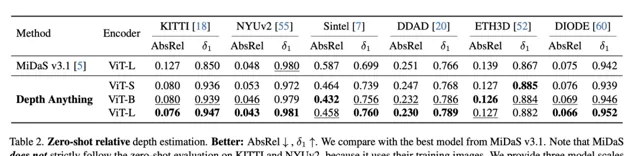
最終,Depth Anything 不僅跟之前成果同等效果,在一些指標上,還超越了參考模型。在下圖零樣本相對深度估計表現中,Depth Anything 對比 MiDaS v3.1 面向 KITTI 等主流數據集,均有不錯表現。其中 AbsRel 數值越低效果越好,δ1 數值越高效果越好。
此外,該模型面向 6 個公共數據集和隨機拍攝的照片,在零樣本能力評估方面也表現出了很強的泛化能力。
03
最佳化細節與模型規模 Scaling-up
完成 V1 版本訓練後,團隊對模型進行進一步最佳化並提升魯棒性,還比照了其它型別模型的效果。
具體來說,基於穩定擴散的 Marigold 屬於生成式單目深度估計模型,對於細節問題,以及透明物體、反射表面單目深度估計問題能很好解決,但復雜度、效率、通用性方面有所不足。Depth Anything V1 的特征則與其互補。

為解決上述問題,團隊嘗試了各種方法及探索,包括調整預訓練模型、修改 Loss 、數據增強等等。
這一過程中,有三點重要發現:
其一,精確的合成數據能在細節方面帶來更好表現。
透過對比其他模型(比如:Marigold ),團隊發
現,對於細節問題,穩定擴散模型並非唯一解。判別式的單目深度估計模型在細節問題方面,依然可以有很好表現能力。
關鍵在於用精確的合成影像數據替換帶標註的真實影像數據。
團隊認為,真實帶標註的數據存在兩個缺點。其一是標註資訊不可避免包含不準確的估計結果,這可能源自傳感器無法捕捉,也可能來自演算法影響。其二,真實數據集忽略了一些深度細節,比如對於樹木、椅子腿等表示較為粗糙,造成了模型表現不佳。

其二,此前很多成果未使用合成數據,源於合成數據本身在之前存在較大缺陷。
以 DINOv2-G 為例,模型基於純合成數據訓練會產生很大誤差,其原因在於,合成影像與真實影像本身存在差異,比如顏色過於「幹凈」,布局過於「有序」,而真實影像則有更強隨機性。此外,合成影像的場景有限,勢必影響模型通用性。
團隊針對 BEiT、SAM、DINOv2 等模型泛化性的對比,結果發現只有 DINOv2-G 達到了滿意效果,其他均存在嚴重泛化問題。

其三,針對合成影像數據揚長避短的方法: 用 合成數據 訓練教師模型並擴大模型規模, 接著,以大規模的偽標註真實影像為橋梁,教授較小的學生模型。
基於上述思路,團隊構建了訓練 Depth Anything V2 的 Pipeline ,具體來說,先基於高品質的合成影像,訓練基於 DINOv2-G 的教師模型,再在大量未標記的真實影像上產生精確的偽標註深度資訊,最後,基於偽標註的真實影像訓練學生模型,以獲取高魯棒的泛化能力。
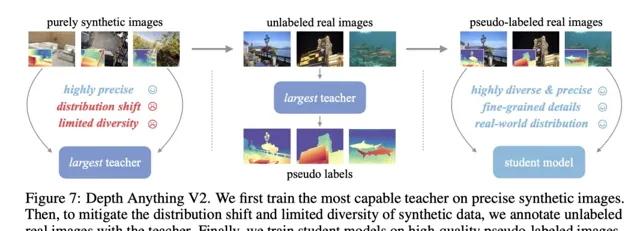
為了更好評價模型表現,團隊還提出了 DA-2K 評價基準。它考慮了精確的深度關系、覆蓋了廣泛場景,並包含大量高分辨率影像及 8 個代表性場景。基於該基準, Depth Anything V2 ViT-G 版本明顯優於 Marigold 及 Depth Anything V1 在內的之前成果。

除了針對數據的相關研究,團隊還嘗試擴大了教師模型容量,以探索模型規模 Scaling 對效果的影響。
透過研究,團隊發現,規模較小的教師模型泛化能力的確不如較大規模模型,此外,不同型別的預訓練編碼器提升規模後,帶來的泛化提升差異很大,比如 BEiT 、SAM 等主流預訓練編碼器表現明顯不如 DinoV2 。
上述種種努力持續數月,最終,Depth Anything 模型在魯棒性和細節豐富度上都有較大提升,且相比基於穩定擴散技術構建的最新模型速度快 10 倍以上,效率更高。

與之相對,預訓練的擴散模型在細節方面表現更佳。團隊同學表示,此前也曾考慮使用更復雜的模型,但透過深入研究,考慮落地成本、實際需求等因素,Feed-forward 結構目前仍是更適合落地的選擇。
回望整個過程,參與同學感慨:「研究工作其實沒特別多所謂的靈感迸發瞬間,更多的,還是踏踏實實逐個把設想方法嘗試一遍,才能取得成績」。
最後,展望 Scaling Laws 對 CV 發展的影響,團隊認為,Scaling Laws 在未來將更有助於解決此前一直存在,且難以突破的基礎任務,充分發揮數據、模型 Scaling 的價值。至於 Scaling 不斷提升的邊界在哪?團隊還在進一步探索中。
04
論文一作為實習生
目前,Depth Anything 已有2個版本模型系列釋出,相關論文 Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data 已中選 CVPR 2024。

該系列成果一作為團隊實習生,相關研究工作也是在公司實習期間完成。
立項時,由 Mentor 提出了規模 Scaling 的路線,並給到最初計畫設想,實習生進一步提出用大規模未標註數據去 Scaling-up 的想法。不到一年,該同學就完成了相關成果的上手實驗、計畫推進、論文撰寫等大部份工作。
期間,公司科學家與團隊 Mentor 相應提供了建議與指導,持續跟蹤進展,並出面跟合作部門協調計算資源。
「我們在研究工作上,會更多聚焦在給出好問題,並在一些關鍵節點把控計畫推進方向,提供給實習生適當的方案思路,執行上,充分信任同學們」 ,計畫 Mentor 分享道。
這樣既能尊重實習同學想法,也能避免完全不管,沒有產出,他認為。
在大家的共同努力下,該實習同學不僅收獲了成果,能力也獲得較大提升,個人研究品位及獨立發現解決問題能力頗受團隊認可。
關於個人成長與團隊支持,實習同學認為,公司和組裏提供了自由研究氛圍,對於合理思路都比較支持。
「而且相比 Paper 數量,團隊會鼓勵花更多時間研究更難、更本質、更能為行業提供新視角和新價值的問題」,他補充道。
事實上,Depth Anything 只是眾多成果之一,字節跳動近期在視覺生成及大模型相關領域的研究探索還有很多。
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
An Image is Worth 32 Tokens for Reconstruction and Generation
Magic-Boost: Boost 3D Generation with Multi-View Conditioned Diffusion
LLaVA-next: Open Large Multimodal Models
PLLaVA: Parameter-free llava extension from images to videos for video dense captioning
Flash v-stream: Memory-Based Real-Time Understanding for Long Video Streams
...
目前,字節跳動大模型電腦視覺方向正在持續招攬優秀人才,如果你也渴望在自由的研究氛圍裏,參與電腦視覺技術的的前沿探索, 歡迎點選閱讀原文,投遞簡歷。
推薦閱讀
點選「閱讀原文」,一鍵投遞崗位!











