本文根據老師在〖deeplus直播:去哪兒網可觀測性實踐〗線上分享演講內容整理而成。 (文末有回放的方式,不要錯過)
肖雙
去哪兒網 基礎架構部技術TL
2018年加入去哪兒網,目前負責去哪兒網 CI/CD、監控平台和雲原生相關平台建設。
期間負責落地了去 哪兒網容器化平台建設,協助業務線大規模套用遷移至容器平台,完成監控系統 Watcher 2.0 的改造升級和根因分析系統落地。 對監控告警、CI/CD、DevOps 有深入的理解和實踐經驗。
分享概要
一、以始為終,用故障指標來衡量監控系統的完善度
二、訂單類故障秒級發現
三、復雜故障,如何分鐘級定位原因
四、總結
一、以始為終,用故障指標來衡量監控系統的完善度
早期介紹內部監控系統時,我們會分享儲存量、報警量等一些核心監控指純量。隨著監控叠代,我們逐漸產生疑問: 這些監控系統指標究竟對業務有多大幫助?
1.故障數據分析
去年,我們對公司的故障數據進行分析,發現:
故障平均發現時間在4分鐘左右
訂單類故障1分鐘的發現率20%
處理時長超過30分鐘的故障比例48%
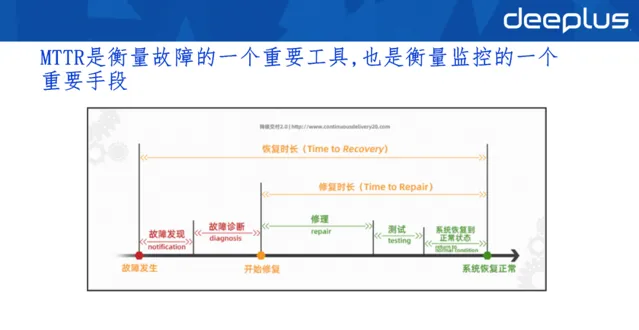
這些指標仍有很大提升空間,基於以上數據,我們參考MTTR對指標進行最佳化。
MTTR將故障劃分為發現階段、診斷階段和修復階段三個階段,所以我們可以針對每個階段制定對應工具,來縮短整體的MTTR。
二、訂單類故障秒級發現
我們在去年明確了目標——訂單類故障一定要做到秒級發現。
1.現狀
實作秒級故障發現之前,根據現有監控系統,梳理了秒級監控系統的建設要點:
采集使用Graphite協定: 指標的采集和格式都是遵循Graphite協定,而建設秒級指標時必須考慮其相容性。
儲存IO高,占空間大: 之前TSDB采用的Graphite的Carbon+ Whisper,Whipser因為空間預分配策略和寫放大問題,會導致磁盤IO高以及磁盤空間占用過多。
分鐘級設計: 數據采集、上報、報警等模組都是分鐘級設計,采集使用Pull模式,定時每分鐘拉取。
2.儲存方案選型
當時對比了兩個TSDB,也就是M3DB和VM(VictoriaMetrics)。
1)M3DB
優點:
高壓縮比,高效能
可伸縮
支持Graphite協定以及部份聚合函式:業務場景中,聚合函式使用頻繁、使用場景復雜
缺點:
部署維護復雜
社群活躍度低
更新叠代慢
2)VictoriaMetrics
優點:
高效能,單機讀寫可達千萬級指標
每個元件都可以任意伸縮
原生支持Graphite協定
部署簡單
社群活躍度高,更新叠代快
缺點:
針對Graphite聚合讀場景下,效能下降嚴重
3.壓測數據
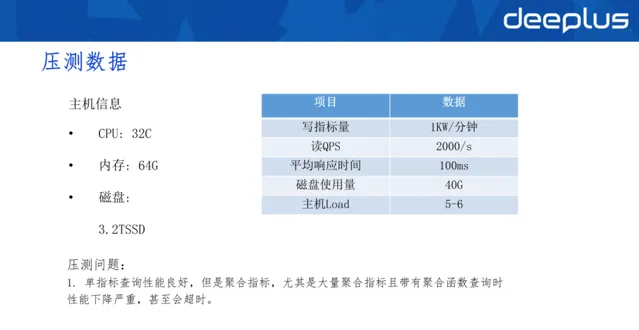
針對VM進行壓測:
壓測後發現,磁盤的使用量較低(40G),整體的效能消耗較低。但使用大量聚合指標或大量聚合函式查詢時,效能下降非常嚴重,甚至超時。
4.存算分離
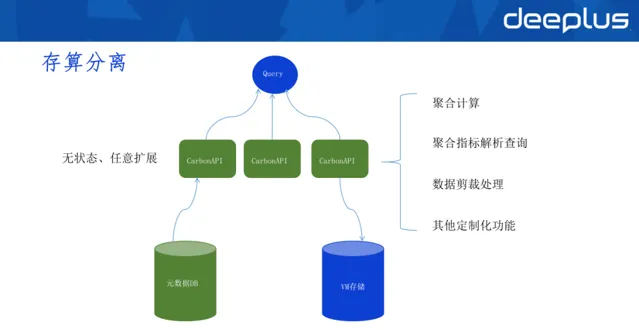
基於以上特點,我們對VM做了存算分離。
因為VM的優勢是單指標查詢場景效能非常好,所以我們利用VM做單指標查詢,使用上面的聚合層(CarbonAPI)計算所有的聚合函式。
聚合層(CarbonAPI)的優勢在於,它是無狀態的,可以任意擴充套件,在此基礎上可添加任何策略、數據監測功能、聚合邏輯、限流和壟斷等能力。
在這套架構下,需要多引入一個後設資料DB,用以儲存所有指標資訊(哪些指標在VM集群中的位置)。
使用者查詢時,先查詢CarbonAPI,CarbonAPI從後設資料DB拿到指標儲存的資訊,再去VM裏拿出對應的數據,在聚合層做聚合計算,最後將數據傳回去。
在聚合層(CarbonAPI),我們還制作了一些客製化的功能。
5.指標采集
存算分解離決了VM的短板問題,第二個任務是實作指標采集、報警的秒級處理。
1)Client端現狀
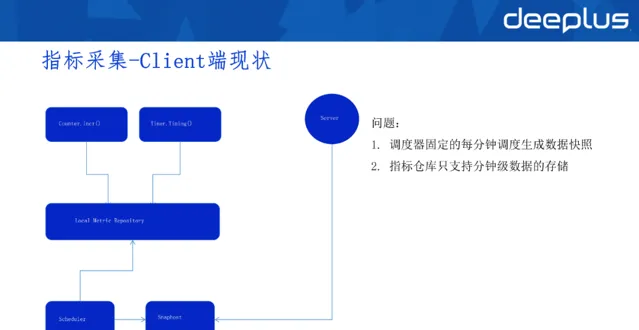
原先使用的是自研客戶端,下圖右方是客戶端架構。
在早期實作時,使用Counter.Incr()計算指標自增,它會將數據放到到原生的指標倉柯瑞, 這個指標倉庫實際在應用程式的客戶端也就是記憶體中。
同時,異步排程器每隔一段時間(可能是分鐘級)生成數據快照,因而Server端拉取快照時,每分鐘拉取的快照是固定的。如果一分鐘內多次拉取,也是固定快照。
這樣處理的好處是Server端異常時,補償拉取的數據也不會變更,數據準確度較高。缺點是排程器固定地每分鐘排程生成數據快照,指標倉庫只支持分鐘級數據的儲存。
2)Client端改造
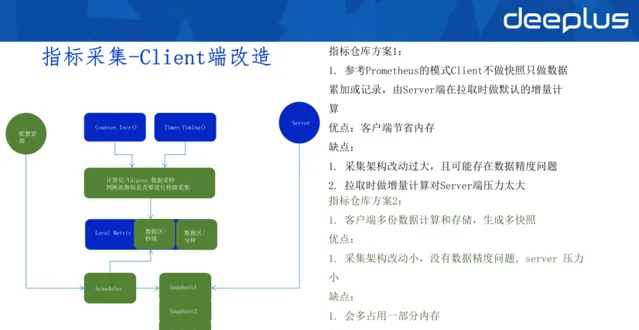
指標倉庫方案1: 參考Prometheus的模式Client不做快照只做數據累加或記錄,由Server端在拉取時做預設的增量計算
優點:客戶端節省記憶體,無需儲存多份數據
缺點:Server端做增量計算,壓力較大;采集架構改動過大,且可能存在數據精度問題
指標倉庫方案2: 客戶端多份數據計算和儲存,生成多快照
優點:采集架構改動小,沒有數據精度問題, server 壓力小
缺點:會多占用一部份記憶體
最佳化:使用Tdigest做數據采樣,記憶體占用量可接受
3)Server端現狀
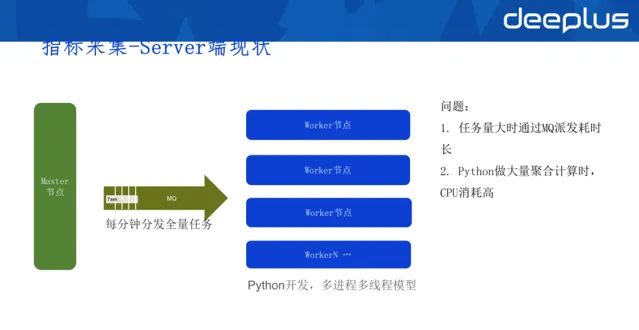
早期Server端進行指標采集時,使用Python+多行程的模型開發,master節點每分鐘發全量任務給work節點,這是典型的producer worker架構,其優點是worker節點可以隨意擴充套件。
問題:
任務量大時透過MQ派發耗時長:比如每隔十秒派發十幾萬的采集任務,采集任務透過MQ派發到worker再進行消費時,過程時間可能已經超過十秒,這種場景下無法做到高頻采集。。 Python做大量聚合計算時,CPU消耗高
4)Server端改造
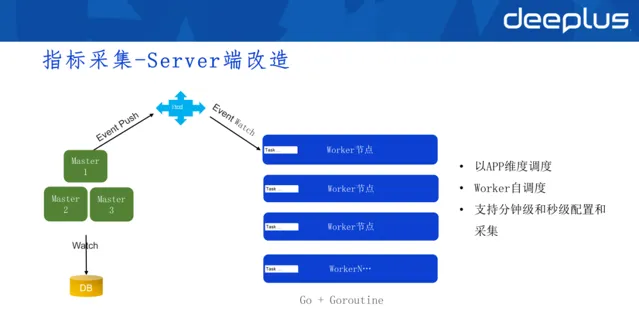
其實還是master和worker的架構,但拆去了MQ。現在worker變成有狀態的節點,一旦worker啟動,任務被master排程給worker,master透過ETCD檢測到worker掛掉後,就會啟用rebalance,節省了任務配發的過程。
6.最終架構
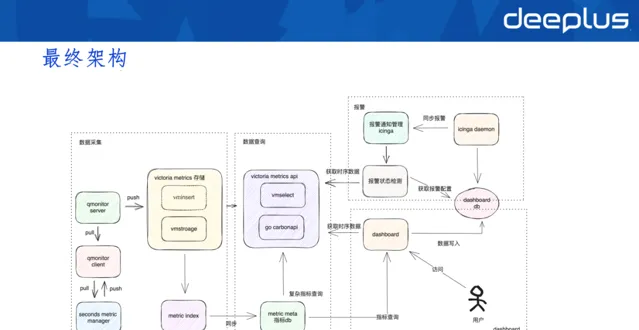
秒級監控的最終架構核心分為三個部份:數據采集、數據查詢以及報警。
實踐效果層面,幫助業務線將訂單故障發現實踐由三分鐘提升到一分鐘。
三、復雜故障,如何分鐘級定位原因

微服務化後定位難的問題聚焦在:
鏈路復雜: 相較於單體等架構更復雜
依賴復雜 :套用依賴的資源多種多樣,依賴的外部資源也越來越多
1.鏈路與指標關聯-精準定位

鏈路部份在內部稱為Qtracer,監控系統叫Qmonitor。
為什麽要關聯這兩部份呢?
我們發現,報警(一般是指標報警)之後,如果套用的QPS很高,會尋找到很多trace。由於不確定哪條鏈路與指標有關系,所以反而幹擾快速定位。
比如有三個入口,進來的流量形成了三條trace,它們的程式碼路徑可能都不經過這個指標,所以不會報警。或者是只有一條trace經過這一報警指標,用剩下兩條trace做故障定位就沒有意義。
所以我們將指標放到了Qtracer裏,Qmointor在呼叫指標計數時,會檢查當前是否有trace環境。如果有trace或者span,就將當前這個指標放進span。
如果指標發生告警,就能直接根據這個指標關聯到真正經過這個指標的流量,再用這些trace定位,效率顯著提高。
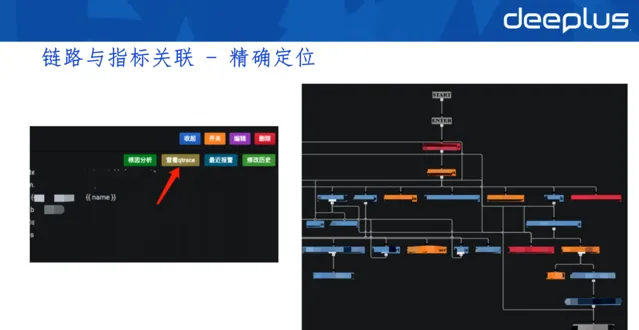
告警面板
右側搜尋出trace後,我們會初步對這個trace上的套用進行異常檢測,比如哪些套用有異常日誌、異常告警,套用依賴的資源是否都正常,容器執行環境是否正常等狀況,並將這些 異常展示在面板,輔助開發定位問題。
2.自身依賴快速排查-套用概覽
將每個套用最核心的指標、狀態以及關註的內容聚合,形成套用概覽。如果套用出現問題,可以在套用概覽中快速瀏覽,快速感知套用是否健康。
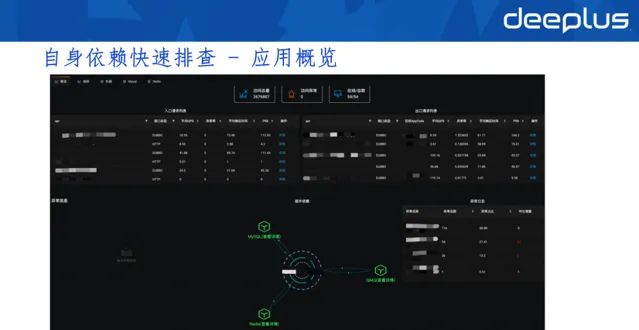
套用概覽提供兩點資訊: 入口的請求列表和出口的請求列表。
入口請求列表指提供了哪些服務,即別人請求的服務。請求哪些介面、介面平均QPS、異常率、平均響應時長等相關資訊,以及趨勢圖都可以在面板中檢視。
出口請求列表指你的請用請求了別人介面或下遊服務,你可以在套用概覽中了解目標套用、其平均QPS、請求外部的異常率、響應時長等資訊。
實際套用中,開發看到以上資訊就能夠判斷套用狀態是否正常。
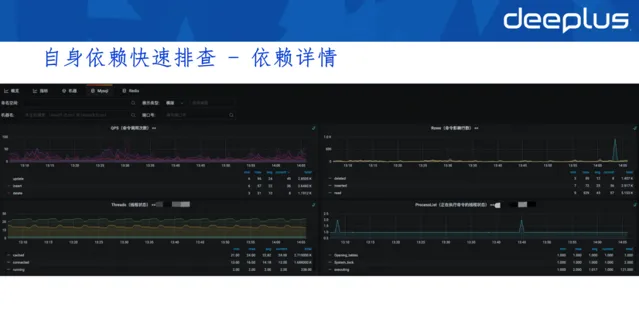
3.自身依賴快速排查-依賴詳情
4.自動分析平台
自動分析平台的執行邏輯是先采集Qtrace,根據trace檢視鏈路異常,然後自動分析平台推薦權重比較高的異常。
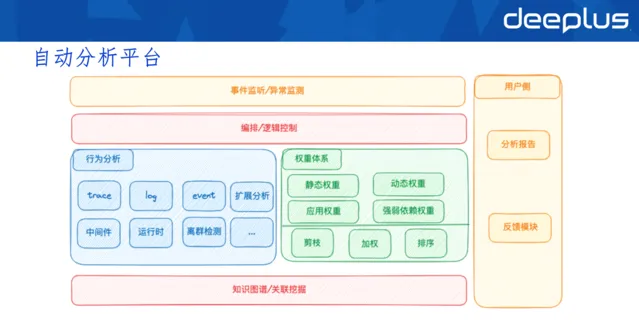
以上是自動分析平台簡單的模型圖。
最底層是知識圖譜的挖掘,知識圖譜對自動分析非常重要,套用依賴、執行容器、機房資訊等內容都需要知識圖譜記錄,形成行為的分析基礎。
行為分析出異常資訊,再經過權重體系的評估打分與排序,最終將可能的異常推薦出去。
1)知識圖譜
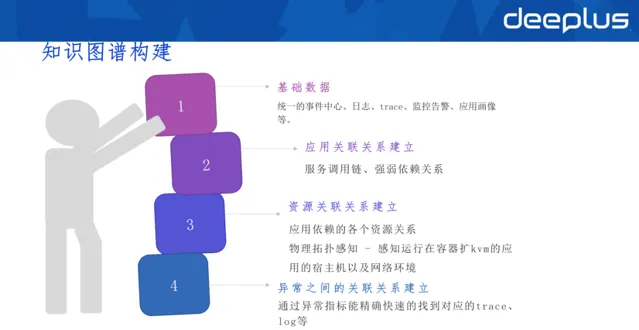
基礎數據: 統一的事件中心、日誌、trace、監控告警、套用畫像(套用基礎的元配置)等。
套用關聯關系建立: 服務呼叫鏈、強弱依賴關系
資源關聯關系建立: 套用依賴的各個資源關系、物理拓撲感知 - 感知執行在容器擴kvm的套用的宿主機以及網路環境
異常之間關聯關系建立: 透過異常指標能精確快速的找到對應的trace、log等,異常的告警之間的關聯關系挖掘
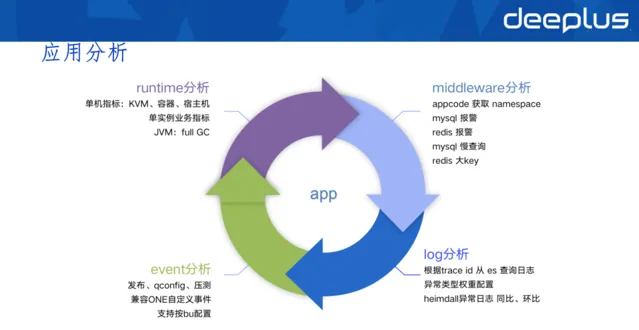
2)套用分析
3)鏈路分析
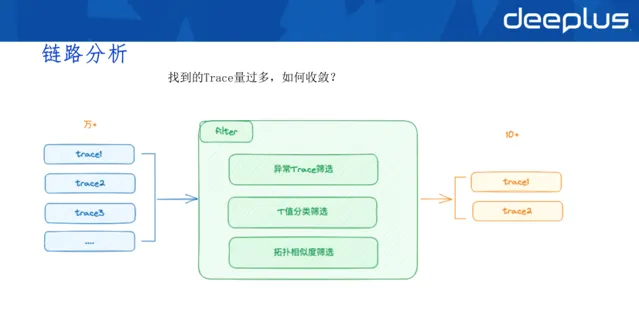
QPS高時,即使已經精確關聯,但一分鐘內找到的trace依然很多,所以需要篩選或收斂至
較小範圍。
篩選分類:
異常trace篩選:重點關註,首先分類
T值分類篩選:基於業務入口垂直分類
拓撲相似度篩選:比較A入口與B入口trace相似度並篩選
如何定位可能是根因的APPCode?
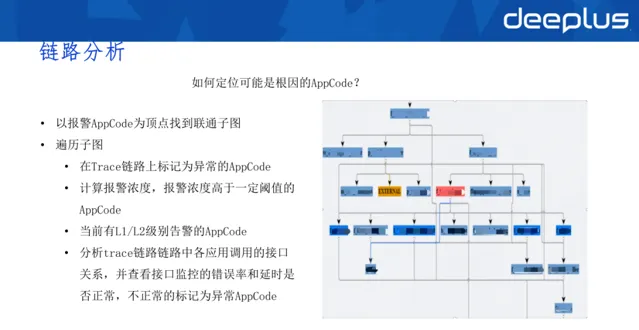
以報警APPCode為頂點找到聯通子圖。
遍歷子圖:
在Trace鏈路上標記為異常的AppCode
計算報警濃度,報警濃度高於一定閾值的AppCode
當前有L1/L2級別告警的AppCode
分析trace鏈路鏈路中各套用呼叫的介面關系,並檢視介面監控的錯誤率和延時是否正常,不正常的標記為異常AppCode

針對AppCode,進行更細維度的異常探測。
4)剪枝排序-權重體系

權重分為四種:
靜態權重:經驗權重,每年或每段時間會根據故障原因進行調整。
動態權重:root case權重,根據各個根因的嚴重級別對自己進行升級,避免真正的根因被淹沒。
套用權重:代表當前故障中此套用異常所占的權重比,表示此套用影響故障套用的機率大小。
強化依賴權重:強弱依賴可以明確表明,A套用的 m1介面依賴B套用的 m2介面是強依賴還是弱依賴,根據此資訊可以確認影響機率。
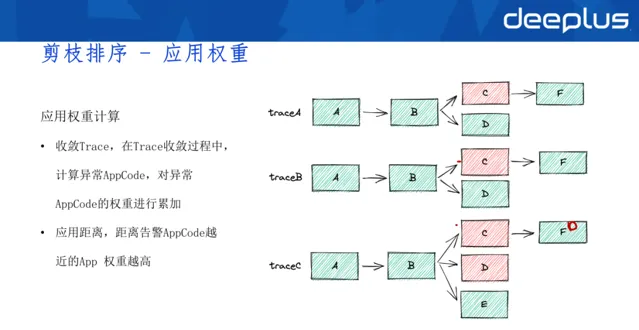
套用權重計算方式:
收斂Trace,在Trace收斂過程中,計算異常AppCode,對異常AppCode的權重進行累加 套用距離,距離告警AppCode越近的App權重越高
如上圖所示,三個trace都是A入口,第一次發現C異常,C的權重會加一;第二次發現C異常,權重繼續累加,由此計算出套用權重。
除此之外,套用權重還受到套用距離的影響。在酒店的業務場景下,我們認為A和B的距離越近,A導致B異常的可能性就越高,A的權重位越高。
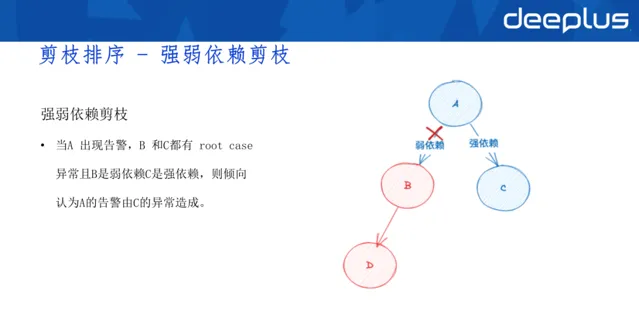
強弱依賴剪枝:
當A 出現告警,B 和C都有 root case異常且B是弱依賴C是強依賴,則傾向認為A的告警由C的異常造成。
5.結果輸出
結果會提示有什麽釋出,root case占比,哪些異常需要重點關註。
6.實踐效果
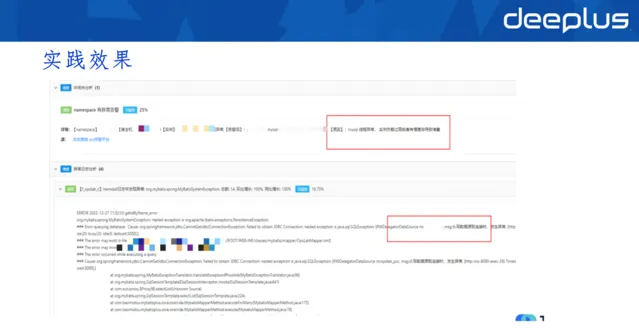
上圖是我們實際的線上故障場景,比如出現MYSQL執行緒異常、負載特別高的情況,就會在結果輸出的界面提示出來。
經過以上改動,現在定位慢的故障比例降低20%,根因定位的準確率在70%-80%。
四、總結
用故障的MTTR指標來營運、最佳化、建設我們的監控體系
秒級監控主要解決高級別故障發現時長的問題
協助故障定位,要在鏈路復雜和依賴復雜的情況下確認套用的依賴元件以及依賴套用的健康狀況,並計算相關異常與此次故障的權重
Q&A
Q1:放在span裏的指標具體是指什麽?數據模型是怎樣的?
A:舉個例子,比如有個介面叫false,需要做QPS的監控,指標就命名為false-QPS。一般請求進入的時候,該指標就會被計數。同時,我們會檢視是否有trace、span,如果有,就將指標名放入span,進一步關聯trace id。透過後期洗數,我們能在ES裏做索引,就能夠透過指標搜尋到trace了。
這個數學模型比較簡單,trace id裏可能有很多span,span可以理解為一個大JSON,將metric放入span,就能實作關聯。
Q2:智慧分析使用了哪些技術棧或工具棧?
A:語言層用的是Go,演算法包括排程演算法、離群檢測、權重等方面。
Q3:怎麽把控指標倉庫中的數據精度?有什麽樣的評判標準?
A:數據精度由客戶端或者SDK控制。比如0秒開始生成快照,生成了0-59秒的快照數據。無論Server端怎麽拉取,新的數據存放在新的倉柯瑞,所以數據互不幹擾。
數據精度在不同的業務場景下有不同要求。大部份業務場景下,監控數據丟一兩個,問題不會太大。如果是訂單類場景,丟數據的問題就比較大。
Q4:權重體系中不同權重占比大概是多少?
A:目前沒有使用權重占比,整體類似於評分系統,不同的權重累加評分,最終篩選出評分高的指標。我們可以把權重的區間設定好,它基於自身區間或情況可以自行升級。
Q5:服務的強弱依賴怎麽確定,是事前透過靜態配置嗎?還是在動態執行時根據某個規則判斷?
A:強弱依賴由另外系統提供數據。去哪兒網實行混沌工程,其中一項內容就是強弱依賴治理。我們在業務線進行常態化的強弱依賴治理,並留存這些數據。
Q6:目前告警治理和運維團隊使用哪些線上化工具系統?如何考核套用業務團隊,量化SLA指標績效考核,還是事故統計?
A:量化SLA指標,業界有個最常用的辦法就是使用燃盡圖統計故障。比如團隊定的SRO是四個九,意味著一年只有50多分鐘的故障時長。
獲取本期P PT, 請添加群秘微訊號:dbayuqing
↓點這裏 可 回看本期直播











