目錄
一、前言
二、雲原生套用管理
1. 雲原生套用管理方式
2. 多集群管理方案
三、容器排程最佳化與與混部
1. 套用畫像
2. 資源預占
3. 平衡排程
4. 在即時混部
5. 在離線混部
6. 彈性伸縮
四、容器資源和成本治理最佳化
1. 機型替換
2. 資源池管理
3. 工作負載規格治理
4. 產品自建
5. 多雲策略
五、雲原生 AI 場景建設
六、展望
一、前言
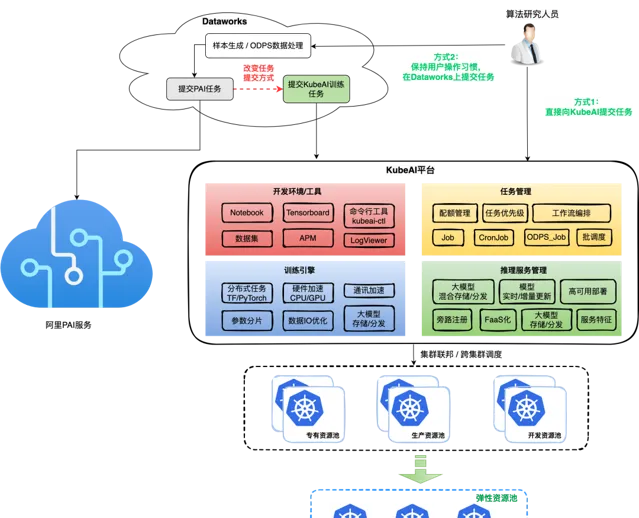
得物 App 作為互聯網行業的後起之秀,在快速的業務發展過程中基礎設施規模不斷增長,繼而對效率和成本的關註度也越來越高。我們在雲原生技術上的推進歷程如圖所示,整體上節奏還是比較快的。
從 2021 年 8 月開始,我們以提升資源使用率和資源交付效率為目標,開始基於雲原生技術建設整個服務體系的高可用性、可觀測性和高運維效率,同時要保證成本可控。在容器化過程中我們遇到了很多的挑戰,包括:如何將存量的服務在保持已有研發流程不變的情況下,做到容器化部署和管理;容器化之後如何做到高效地運維;如何針對不同的業務場景,提供不同的容器化方案等等。
此外,透過技術手段實作持續的成本最佳化是我們的長期目標,我們先後建設落地了畫像系統、混部方案和排程最佳化等方案。本文把得物在推進雲原生容器技術落地過程中相關方案和實踐做一些總結和梳理,歡迎閱讀和交流。
二、雲原生套用管理
1.雲原生套用管理方式
容器與 ECS 的資源形態是有差異的,所以會造成在管理流程上也會有不同之處。但是為了盡可能降低容器化帶來的使用體驗上的差異,我們參考業內容器套用 OAM 模型的設計模式,對容器的相關概念做了遮蔽和對等解釋。例如:以「套用集群」的概念代表 CloneSet 工作負載(Kruise 提供的一種 Kubernetes 擴充套件工作負載);將單個 Pod 約定為一個套用集群的例項;以「套用路由/網域名稱配置」的概念代表針對 Ingress/Service 的設定。
在套用集群的構造上(即如何構造出 Kubernetes 工作負載物件),我們設計了「配置/特征分層」的方案,將一個套用集群所處歸屬的套用、環境組、環境上的配置進行疊加後,使用 Helm 工具渲染生成 Kubernetes 資源物件,送出給容器平台。
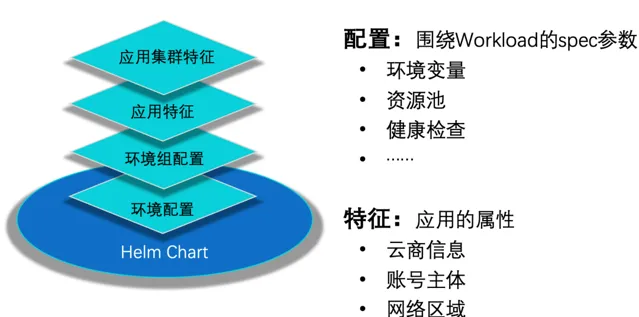
CI 和 CD 過程均使用這種配置/特征分層的方式,一方面可以解決套用依賴的中介軟體資訊的管理問題(由相應的提供者統一維護);另一方面,這種管理方式可以讓中介軟體元件/服務變更時按照不同維度進行,整體上降低了配置變更帶來的風險。
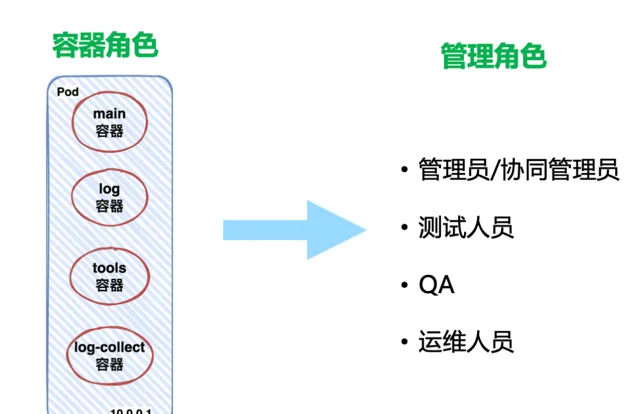
Sidecar 容器在套用集群例項中除了扮演「協作者」的角色外,我們還基於它做了許可權管理,以便對應在 ECS 形態下的不同使用者的登陸許可權,也算是一舉兩得。當然,在容器場景下也是可以定義不同的使用者,賦予不同的角色,但是強依賴基礎映像的維護。
2.多集群管理方案
雲原生場景下的解決方案對套用集群而言本身就是高可用的,比如:容器編排引擎 Kubernetes 中支持 Pod 例項的拓撲分布設定、支持可用區設定、副本數設定、 Service 負載均衡的設計等,這些都能保證套用集群的高可用。那如果單個 Kubernetes 集群不可用了,會有什麽的影響呢,該如何解決?多集群管理方案就是我們解決 Kubernetes 的可用性問題的思路。
如果 Kubernetes 控制面不可用了,會導致套用釋出受損,較嚴重的情況也會影響容器服務的可用性。所以,為了保證 Kubernetes 的可用性,一方面要保證 Kubernetes 各元件的健壯性,另一方面要適當控制單個 Kubernetes 集群的規模,避免集群過大造成系統性風險升高。我們的解決思路就是「不要把雞蛋放在一個籃子裏」,用聯邦的方式管理多個 Kubernetes,將業務分散到不同的 Kubernetes 集群。
聯邦的思想在 Kubernetes 誕生不久就被開始討論,逐步設計實作,從最初社群的 KubeFate V1.0 到 V2.0,再到企業開源的 Karmada、KubeAdmiral 逐漸成熟起來,並實際套用到了生產場景。那如果沒有集群聯邦,多個 Kubernetes 集群就沒法管理了嗎?當然不是的,容器管控平台其實也能做這件事情,筆者在幾年之前還對此深以為然,但現在已經完全改變看法了。因為在實際的生產落地過程中我們發現,相比在管控中用 if...else/switch 的方式,亦或配置的方式相比,基於 CRD 的方式來管理多集群效率更高、邏輯更清晰。
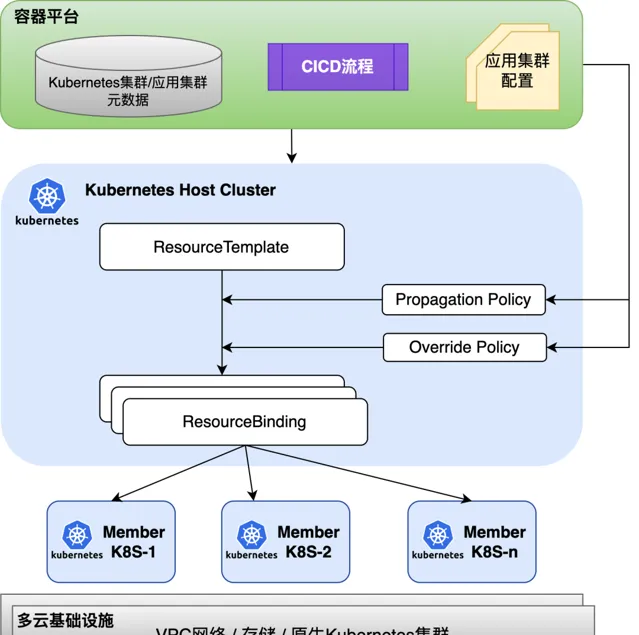

得物在使用聯邦思想管理多 Kubernetes 集群的時候,參考華為開源的 Karmada 解決方案,在此基礎之上做了客製開發。 容器管控平台負責管理套用集群的原始特征和配置,管理 CICD 流程,向 Host Kubernetes 集群發起容器物件管控請求。 Host Kubernetes 集群透過 PropagationPolicies 管理工作負載如何分發到 Member Kubernetes 集群,透過 OverridePolicies 管理差異化的配置。 單 Kubernetes 集群下我們使用了分批釋出的方式來管理套用集群的釋出,在引入聯邦管理之後,我們把分批釋出的邏輯從容器管控層面下移到了 Host Kubernetes 集群上。
為了相容存量的透過 Kubernetes Service 進行呼叫的服務,我們在 Member Kubernetes 集群透過自訂的 MCS-Controller 來管理跨集群的 Service/Endpoints 物件,在 Host Kubernetes 層透過 MCS-Validator 做雙重校驗,確保跨集群的 Service 的一致性。
三、容器排程最佳化與混部
落地雲原生容器技術的目標是期望在敏捷、彈性和可用的基礎上,最終實作資源利用率上的提升、成本上的節省。這通常有 2 個實作途徑,一個是透過技術的手段,另一個則是透過治理方法。本章重點介紹我們在容器精細化排程和混部實踐方面的技術方案設計和落地過程。
1.套用畫像
套用服務的研發人員在部署套用集群例項時,通常會申請超過套用集群本身承載業務流量時所要消耗的資源量,這是可以理解的(要確保系統的資源利用率安全水位,防止過載造成系統夯住),但是不同的研發人員對這個「度」把握是不一樣的,因為合理地設定套用集群的資源用量是依賴研發人員經驗的,也就是說主觀性會更強。
為了解決上述問題,業內的做法通常是透過分析套用集群的過往資源利用率數據,來刻畫出套用集群在業務流量下的實際資源利用率曲線,這就是套用畫像。如下圖所示是我們建設的畫像系統的架構框圖,該畫像系統不僅負責套用的畫像分析,也負責宿主機、Kubernetes 集群的畫像分析,用來指導整個容器平台對資源的管理。
容器的監控數據透過 Prometheus 方案進行采集和管理,自研的 KubeRM 服務將它作為資料來源,周期性計算產出套用畫像、宿主機畫像和 Kubernetes 集群畫像(資源池畫像)。容器平台部署線上服務服務時,可參考畫像值來配置套用集群的資源規格,這裏的畫像值就是指 Pod 的 Request 值,計算公式如下:
Pod Request = 指標周期性利用率 / 安全水位
公式中「指標周期性利用率」是畫像系統透過統計學手段、AI 模型等方法計算分析出的資源指標(CPU/記憶體/GPU視訊記憶體)在實際業務流量下所表現出的周期性的規律。畫像值的生效我們透過以下 4 個策略進行實施:
針對 P3/P4 等級的服務,預設在服務部署時生效畫像值。
針對非 P3/P4 等級的服務,將畫像值推薦給使用者,由使用者決定部署時是否采用畫像。
分資源池設定不同的生效策略(預設生效,或者使用者決定生效)。
GPU 視訊記憶體的畫像不做預設生效,推薦給使用者,讓使用者決定。
交由使用者決定畫像是否生效時,如何讓使用者更傾向於去生效畫像呢?我們使用差異化計費的策略:生效了畫像的套用集群例項按照其 Pod 配置的 Request 值計費,未生效畫像的套用集群例項按照其 Pod 配置的 Limit 值計費。使用者可以根據自己服務的實際情況選擇生效畫像,以降低成本;平台也因為畫像而拿到了更多可以排程的資源,用於其它更多的場景。
此外,畫像系統也接入了 KubeAutoScale 自動伸縮器,在業務低峰期,可以指導自動伸縮器對部份場景線上服務做副本縮容操作,以便釋放出更多的資源供給其它場景使用(比如:混部任務場景),後面的章節會詳細介紹。
2.資源預占
當整個容器集群的資源冗余量不是很充足的時候,在以下幾種情況下是會出現 「雖然集群層面總量資源是夠的,但是業務 Pod 卻無法排程」的問題,影響業務釋出效率和體驗。
在集群中容器例項變更比較頻繁的時候,某個大規格的業務集群在做捲動更新時,釋放的舊的例項很可能被小規格的容器例項所搶占,導致無法排程。
研發同學負責 2 個套用服務 A 和 B,它們的規格都是一樣的。為了保證總體成本不變會,選擇將 A 服務的例項縮掉一些,然後擴容 B 服務的例項。因為 Kubernetes 預設排程會按照 Pod 建立時間來依次排程新 Pod,當使用者縮容完 A 服務的例項再去擴容 B 服務例項的時候,A 服務釋放的資源很可能被其他容器例項搶占,導致 B 的例項無法排程。
在大促、全鏈路壓測等業務需要緊急擴容的情況下,容器平台會新擴宿主機節點以滿足業務需求,不曾想新擴容的機器資源卻被那些「小而快(拉起頻繁,執行時間短)」的任務給見縫插針地搶占了,一方面會導致大規格的服務例項無法排程,另一方面還造成了較多的資源碎片。
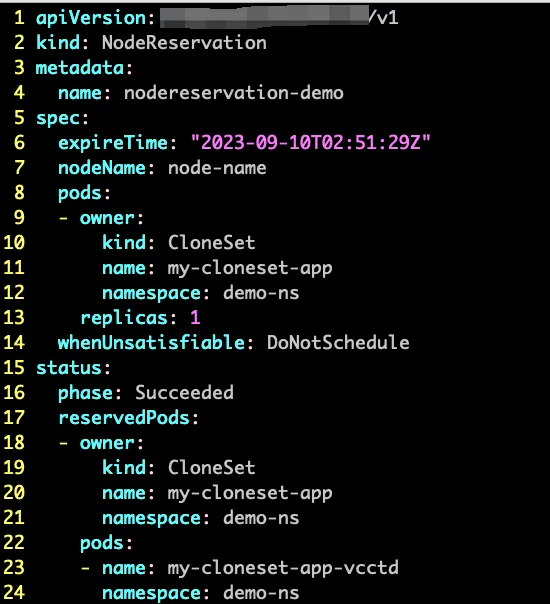
為了解決以上問題,我們在排程器中自訂實作了資源預占的排程外掛程式(透過 CRD 定義資源預占期望,影響排程決策),用來提升使用者體驗和提高排程效率。
3.平衡排程
為了更好地平衡集群中節點的水位,以避免過熱節點的出現、盡量減少碎片資源等為目標來思考和設計,我們基於 Kubernetes 提供的排程器擴充套件框架,自訂實作了多個排程外掛程式:
CoolDownHotNode 外掛程式: 給最近排程過 Pod 的節點降低優先級,避免熱點節點。
HybridUnschedulable 外掛程式:
阻止使用彈性資源的 Pod 排程到某些節點上。
NodeBalance 外掛程式:
用於平衡各節點上 CPU Request 值與畫像的比值,平衡各節點 CPU 使用率。
NodeInfoRt 外掛程式:
基於畫像打分數據和即時打分數據最佳化 Pod 排程。
4.在即時混部
從今年 1 月份開始,我們著手做在離線混部的落地,一期的目標著眼於將線上服務與 Flink 任務進行混部。之所以選擇 Flink 任務做混部,是因為它與線上服務有一個相似之處,那就是它是一種常駐的離線任務,在它啟動之後如果沒有特殊情況,一般不會下線,這種特質會使得我們的容器集群排程頻次、Pod 的變更程度會低一些,進而對穩定性的挑戰也會小一點,整體混部風險也會低一些。
在沒有混部的情況下,我們的集群整體利用率較低,即便畫像功能能幫助使用者盡可能合理的為自己的服務例項設定資源規格,但對容器平台而言這依然很被動。所以為了挖掘出可以用來混部的資源,我們為不同等級的服務設定不同的綁核策略。如下表所示定義了 4 種套用型別(LSX、LSR、LS、BE),適用於 P0~P4 範圍和離線任務,綁核策略從完全綁核到部份綁核,再到完全共享。

離線任務(Flink 任務)屬於 BE 型別,可以使用的資源是在宿主機所有 CPU 核心裏面單獨劃分出來的一部份專用 CPU 核心,再加上 LS 的共享 CPU 核心,以及 LSR、LS 型別的套用上共享出來的部份 CPU 核心。

LSX、LSR 和 LS 型別的套用服務的容器例項均申請使用 Kubernetes 原生的資源 CPU/Memory 資源;BE 型別的任務需要申請使用我們自訂的資源 BE-CPU/BE-Memory 資源。
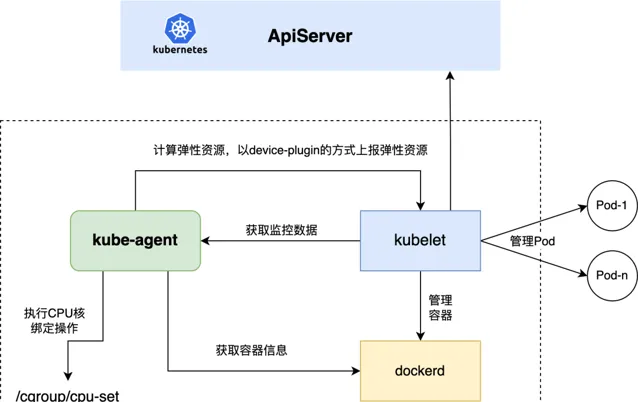
基於 Kubernetes 的 Device-Plugin 機制我們自研實作了 Kube-Agent 元件,該元件在集群中的所有節點上以 Damonset 的方式部署,一方面負責根據自訂策略將本節點上可用的 BE 資源上報給 API-Server(透過 Kubelet 元件間接上報),另一方面負責執行 CPU 綁核操作。隨著混部的深入,該元件也承擔了更多的工作內容(例如:執行 CPU 算力壓制操作、參數動態調整操作,執行 VPA 操作等)。
5.在離線混部
一期的混部在套用級別劃分的基礎上,套用了 CPU 核劃分策略來實作混部。站在 CPU 核心的角度來看,透過 CPU 核劃分策略之後,每個 CPU 核心已經有了自己的負載歸屬,能否充分利用取決於分配到它上面的業務特性。但站在整機的利用率上來看(或者站在整個集群的利用率角度來看),依然有很大的提升的空間。混部二期的時候,我們考慮對BE資源進行二次超賣,以另一種新的自訂資源(OT 資源)進行分配使用。使用 OT 資源的任務不獨占綁核,而是共享劃分給 BE 資源的所有 CPU 核心。

我們使用 OT 資源來混部 AI 訓練任務、其它數據處理任務,為了消除訓練任務對線上業務的影響,透過以下策略進行保證:
設定宿主機安全水位,透過排程外掛程式防止過熱節點出現。
透過 CPU Group Identity 進行優先級競爭,保障離線任務的排程優先級絕對低於線上服務。
對離線任務進行獨立掛盤,避免影響線上服務的磁盤 IO。
夜間時段透過 KubeAutoScaler 進行對線上服務進行彈性縮容,等比例提升記憶體的空閑率,保障離線任務有足夠的記憶體資源。
6.彈性伸縮
容器平台的彈效能力相較於傳統 IDC 資源管理模式、ECS 資源管理方式的要更上一個台階,因為它更側重將彈性伸縮的決策權交給套用服務,而不是資源管理方。雲原生技術中常說的彈性伸縮方案通常包含2種方式:
HPA: Horizontal Pod Autoscaling,水平方向的 Pod 副本擴縮容。
VPA: Vertical Pod Autoscaling,垂直方向的 Pod 規格擴縮容。
Kubernetes 中透過資源物件 HorizontalPodautoScalers 來支持工作負載的水平擴縮容,在較早的版本中只支持 CPU 和記憶體這兩個資源指標,較新版本中也開始支持自訂指標了。針對 VPA 的需求,目前 Kubernetes 層面還沒有比較穩定的可用功能,因為對一個 Pod 例項做資源規格的調整,會涉及到宿主機上資源賬本的管理問題、監控問題,也會涉及到 Pod 的重建/容器重新開機動作,影響面會比較大,目前社群中依然在討論。但企業在 VPA 方面,也都是躍躍欲試,會設計自己的個人化 VPA 方案,本文前述套用畫像功能,就是我們得物在 VPA 方案上探索的第一步。
此外,我們在實際的支撐業務雲原生化轉型過程中發現,與透過服務的資源使用率指標來幫助業務來決策服務例項副本數的調整的方式相比,定時擴縮容反而能讓研發同學更有信心,研發同學可以根據自己負責的業務服務的流量特征,來設定定時地縮容或者擴容自己的服務例項數量。
為了滿足彈性伸縮場景的所有需求,我們設計實作了 KubeAutoScaler 元件,用來統一管理 HPA、VPA、定時伸縮等彈性伸縮策略配置。此外,如前所述,該元件與畫像系統相互協作,在混部場景下可以幫助在夜間對部份低流量的服務做縮容操作,釋放更多的資源供離線任務使用。
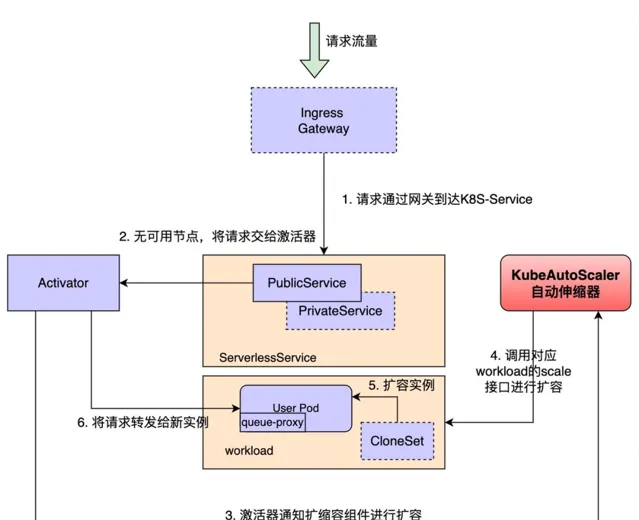
彈性伸縮方案在 GPU 服務場景幫我們避免了很多的資源浪費,特別是在測試環境。如圖所示,我們為 GPU 服務註入了一個名為 Queue-Proxy 的 Sidecar 容器,用來采集服務流量,當流量低於某個閾值時,會按照比例減少例項數;當流量為 0 並持續了一段時間之後,會完全縮零。當冷啟動時,請求會經過啟用器 Activator,啟用器再通知 KubeAutoScaler 進行服務擴容。生產環境的部份服務也開啟了這一套機制,但在流量低峰期不會完全縮容至零,會維持一個最小的副本數。
四、容器資源和成本治理最佳化
為了更好地提升整體的資源利用、降低基礎設施成本,與技術方案的落地周期長、復雜度高的特點比起來,透過治理方法往往能在較短時間內達到不錯的效果,特別是在套用服務容器化部署改造進行到後期的時候。我們透過以下 5 個方面的治理實踐,降本效果明顯。
1.機型替換
因為歷史原因,我們的模型推理服務在剛開始的時候使用的是 V100 的機型,該機型視訊記憶體較大、GPU 算力較優,更適合用在訓練場景,在推理場景的話有點大材小用了。經過機型對比分析,我們選用了一個價效比較高的 A10 機型,推理服務的成本整體降低了 20% 左右,而且因為 A10 機型配備的 CPU 架構有升級,對前後處理有較高要求的推理服務而言穩定性和效能均有提升。
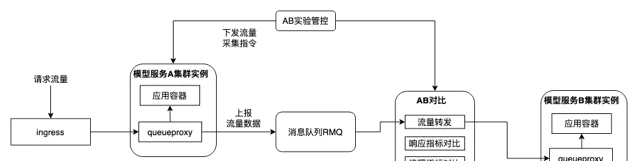
從 V100 切換到 A10,主要的工作在於基礎映像的替換,因為部份模型服務可能使用了較低版本的 CUDA,但是 A10 卡的算力需要配備較高的 CUDA。另外,因為兩種卡的 GPU 算力也是有差異的,替換之後需要對推理結果做對比驗證才可以上線。我們基於流量回放的思路,設計了 AB 實驗功能幫助業務做切換測試。
在使用 CPU 計算資源的場景上,我們對算力要求一般、對 CPU 指令集因無特殊要求、對單核/多核效能無要求的服務,均將其使用的機型從 Intel 的切換到了 AMD 的,整體成本降低 14% 左右。
2.資源池管理
不得不承認的是容器化初期業務方是占據主動的,業務側會基於穩定性、資源供給量上的考量要求容器平台獨立建集群,或者資源池,容器平台也會選擇粗放式管理而應承這些需求。隨著容器化的推進,業務側的信心也會增強,容器平台對資源的把控程度也會更好,我們逐步采取以下幾個動作來收斂資源的管理,提高整體的資源分配率:
冗余量控制: 業務的釋出是有周期的,我們會根據釋出周期,動態調整容器平台管理的資源冗余量。在保證日常的叠代開發的同時,盡可能縮小冗余量。
集群合並: 統一規劃 Kubernetes 集群,按照區域(上海、杭州、北京等)、網路環境型別(測試、預發、生產)、業務形態(普通業務、中介軟體、基礎設施、管控集群等)等維度討論和決策,下線不必要的集群。
資源池合並、規整機型: 合並資源需求特征比較相近的資源池(例如:計算型的、記憶體型的),選擇合適的機型。與業務溝通,下線或者合並利用率過低的小資源池。
碎片整理: 單靠排程器的最佳化,在排程時盡可能避免碎片力量有限。加上線上服務的變更頻率一般比較低,如果不做重排程,長時間累積下來,集群中會存在大量碎片。所以,針對多副本的套用集群,在健壯的優雅停機機制基礎上,我們適當進行了一些碎片整理任務(重建 Pod 自由排程、重排程、宿主機騰挪等),有效地減少了資源碎片。
3.工作負載規格治理
使用者自訂工作負載的規格在雲原生場景下也是一個常用的做法,這看似對使用者友好的做法卻對容器平台造成了一些挑戰,因為如果對使用者設定規格的自由度不做一些限制,很可能出現一些非常不合理的規格設定(例如:6C120G、20C4G),會產生排程碎片、成本分攤計算標準也難統一。
為了解決規格的問題,我們對線上服務的資源規格做了限制,不允許使用者隨意指定,而是由平台給出規格列表,由使用者選擇使用。規格列表可以分資源池設計、也可以分業務場景設定。針對任務型的工作負載,我們定義了 3 種 CPU 型別的資源規格(普通型、計算型、記憶體型,分別對應不同的 CPU:記憶體比例)。
針對特殊的任務需求,我們約定了資源規格當中 CPU:記憶體的範圍。針對使用 GPU 的任務,因每種 GPU 卡的 CPU/記憶體/視訊記憶體規格配比都是不一樣的,我們定義了針對每種 GPU 卡的 CU 單位,使用者只需要選擇相應的 CU,填寫 CU 數量即可。規格約定之後,我們針對不同的規格做了差異化計費,保證了規格申請和成本分攤上的合理性。關於規格的定義和計費標準,詳見下表。
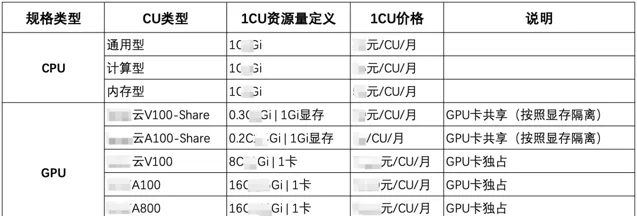
4.產品自建
得物的基礎設施是在雲上,所以在業務發展過程中,部份服務能力我們是會直接選用雲上產品的。演算法側的模型訓練任務,最開始的時候就是選用雲上產品,隨著容器化的推進,我們自建的 AI 平台(KubeAI 平台)逐步承接模型訓練任務,使得訓練任務的成本大幅下降。
自建 KubeAI 平台,使得我們將訓練使用的資源與線上服務、其它離線任務場景使用的資源納入了統一的管理體系,便於從全域的視角去合理地排程分配資源,為 AI 模型訓練場景拿到更多的可用資源。本文前述 2.5 小節,我們就是透過混部的方式,將線上服務的資源供給了訓練任務使用,當前已經在常態混部。
5.多雲策略
作為雲上使用者,多雲策略是我們的長期目標。在多雲之間獲得議價主動權、符合合規性要求、獲得更充足的資源供給。尤其今年 4 月份以來,隨著 GPT/AIGC 方面的爆發、政策因素導致單個雲商的 GPU 資源對我們供給不足,阻礙業務發展。我們及時采用多雲策略,將 GPU 業務分散到不同的雲供應商,保障業務正常開展。當然,多雲的接入不是一蹴而就的,而是需要分業務場景逐步推進,周期較長,難度較大,我們需要考慮以下問題:
梳理業務,找到適合多雲的業務場景,或者找到適合在多雲之間靈活遷移的業務場景。
因不同雲供應上的機房可能在不同的區域,所以需要考慮跨地域服務存取、中介軟體依賴問題。
跨雲供應商的數據存取和傳輸問題,涉及到專線建設、成本問題。
五、雲原生AI場景建設
我們期望雲原生容器技術的落地是要覆蓋全場景的,要將雲原生技術在普通服務、中介軟體產品和特殊的業務場景上都能發揮其巨大優勢。目前 MySQL、Redis、Miluvs、ElasticSearch 等產品都已經在推進容器化。雲原生 AI 場景的建設,我們透過 KubeAI 平台的建設在持續推進。
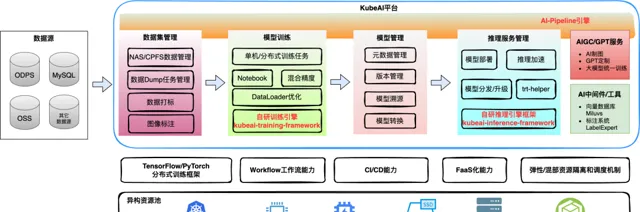
KubeAI 是得物 AI 平台,是我們將雲原生容器技術落地得物全站業務過程中,逐步收集和挖掘公司各業務域在AI模型研究和生產叠代過程中的需求,逐步建設而成的一個雲原生 AI 平台。KubeAI 以模型為主線提供了從模型開發,到模型訓練,再到推理(模型)服務管理,以及模型版本持續叠代的整個生命周期內的解決方案。此外,隨著 AIGC 的火熱發展,我們經過調研公司內部 AI 輔助生產相關需求,上線了 AIGC/GPT 服務,為得物豐富的業務場景提供了 GAI 能力,助力業務效果提升。關於 KubeAI 平台相關解決方案,我們之前釋出過一些文章,歡迎大家閱讀交流,這裏不再贅述。
六、展望
雲原生容器技術在得物的落地開展還是比較快的,業務覆蓋面也比較廣泛。經過 2 年時間的實踐落地,已經全面深入資源管理系統、預算/成本管理機制、套用服務釋出流程、AI 演算法等管理體系和業務場景。接下來:
在 容器化 ,我們會繼續推進中介軟體產品的容器化,進一步提升基礎設施的資源效率。
我們會繼續鞏固混部方案,繼續探索彈性容量、排程最佳化等方案,進一步提升資源效率。
在 穩定性 方面,我們會繼續關註容器平台/Kubernetes 本身的穩定性建設,防範風險,切實保證業務平穩執行。
與業務場景一起探索快速接入多雲,以及多雲之間的快速切換能力,保障業務規模在持續增長的情況下,容器基礎設施切換靈活、堅如磐石。
作者丨weidong
來源丨公眾號:得物技術(ID:gh_13ba5621e65c)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]
活動推薦
2024 XCOPS智慧運維管理人年會·廣州站將於5月24日舉辦 ,深究大模型、AI Agent等新興技術如何落地於運維領域,賦能企業智慧運維水平提升,構建全面運維自治能力! 碼上報名,享早鳥優惠。












