作者 | 王啟隆
責編 | 唐小引
出品 | AI 科技大本營(ID:rgznai100)
從今年 2 月,OpenAI 用一個意為「天空」的日語詞匯「 Sora 」引爆了技術圈,並為視訊生成技術立下了一道新標桿:將簡短的文本描述轉換成一分鐘的高畫質視訊片段。隨後的兩個月裏,各路神仙試圖從「CloseAI」的各類釋出渠道中捕捉 Sora 零碎的研究細節,時至今日仍未降溫。
這期間,北京大學和兔展智慧在三月份聯合發起了開源計畫 Open-Sora-Plan ,旨在透過開源框架重現 Sora,訓練一個包含無條件視訊生成、類視訊生成和文本、視訊生成等技術的模型。
就在昨天, Open-Sora-Plan v1.0.0 正式推出,顯著增強了視訊生成品質和文本控制功能 , 並且正在訓練更高分辨率(>1024)以及更長持續時間(>10 秒)的視訊。一個月的變化非常大,Open-Sora-Plan 如今采用 CausalVideoVAE 架構,支持 華為升騰 910b 芯片 ,在 Hugging Face 上已有 Demo。
GitHub 連結 :https://github.com/PKU-YuanGroup/Open-Sora-Plan
Hugging Face 線上演示 :https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0
以上兩個視訊為 Open-Sora-Plan 計畫訓練的 Video-VAE 重建結果
復現細節
Open-Sora-Plan 的技術框架在計畫公布時便已經定下,由三大部份組成:
Video VQ-VAE.
全稱 Video Vector-Quantized Variational Autoencoder, 結合了變分自編碼器(VAE)和向量量化(Vector Quantization, VQ)的概念, 是一種針對視訊數據的編碼-解碼模型,用於壓縮和重建視訊序列。
Denoising Diffusion Transformer.
Denoising 意指去噪自編碼器(Denoising Autoencoders)。 Diffusion Transformer 通常簡稱 DiT,轉譯過來就是「擴散 Transformer」,被視為 Sora 的重要技術基礎之一,在 Sora 出圈時還帶火了論文的合撰者謝賽寧。
這種模型通常用於從雜訊逐漸重構原始數據的過程中,透過一系列逐步去噪步驟生成高保真樣本,特別是在影像和視訊生成場景中表現出色。
Condition Encoder.
即條件編碼器。這是在生成過程中引入外部條件資訊的關鍵元件,它可以將各種型別的輸入條件(如文本描述、標簽、類別或其他輔助資訊)轉化為模型可以理解的高級特征表示。

而本次 v1.0.0 版本的釋出的主要改進,便是能夠利用 CausalVideoVAE 實作高效訓練和推理,透過 4×8×8 的空間-時間壓縮最佳化視訊數據處理,並將首幀視為影像,允許自然地同時對影像和視訊進行編碼,從而讓擴散模型更好地捕捉空間視覺細節,提高視覺品質。
模型結構
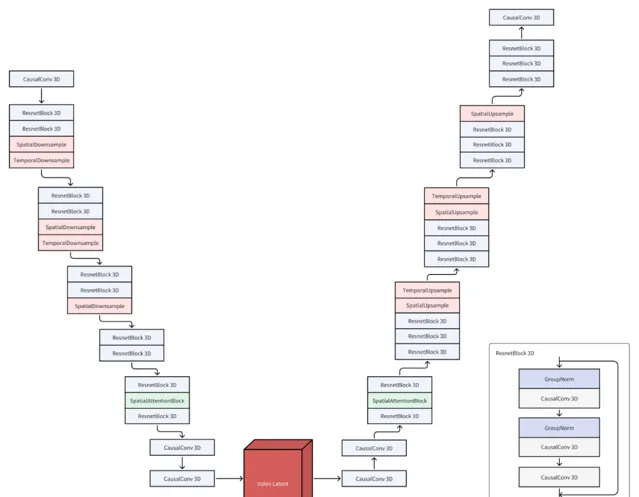
CausalVideoVAE 的結構基於 Stable-Diffusion Image VAE ,在 Stable Diffusion 中使用 VAE 能夠得到顏色更鮮艷、細節更鋒利的影像,同時也有助於改善臉和手等部位的影像品質。為了讓影像 VAE 的預訓練權重順利地用在視訊 VAE 上, Open-Sora-Plan 的團隊 做了以下設計:
CausalConv3D :將 Conv2D 轉換成 CausalConv3D 可以同時訓練影像和視訊數據。CausalConv3D 對第一幀進行了特殊處理,因為它無法獲取到後續幀。
初始化 :將 Conv2D 擴充套件成 Conv3D 有兩種常見的方法,一是 平均初始化 ,二是 中心初始化 。Open-Sora-Plan 采用了一種特殊的初始化方法(尾部初始化)。這種初始化方法可以讓模型在沒有任何訓練的情況下,直接重建影像,甚至視訊。
訓練細節
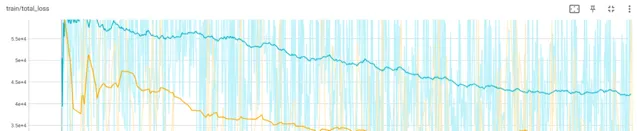
上圖展示了兩種不同初始化方法在 17×256×256 影像上的損失曲線。
黃色曲線表示使用尾部初始化的損失,藍色曲線對應中心初始化的損失。從圖上可以看出,尾部初始化在損失曲線上表現更好。此外,研究團隊發現中心初始化會導致錯誤積累,導致長時間的崩潰。
最佳化推理
即使凍結 Diffusion 訓練中的 VAE,CausalVideoVAE 的成本還是會比較高。具體來說,在 Open-Sora-Plan 團隊現有配備的 80GB GPU 記憶體的情況下,僅能使用半精度處理分辨率分別為 256×512×512 或 32×1024×1024 的視訊進行推理, 這限制了他們對更長和更高分辨率視訊進行擴充套件的能力 。
因此,他們采用了 瓦片卷 積(tile convolution) ,以幾乎恒定的記憶體使用量推斷任意長度或分辨率的視訊。
數據構建
Open-Sora-Plan 團隊構建了一個高品質視訊數據集,其嚴格遵守兩個原則:
首先, 確保數據集中不包含任何與內容無關的浮水印 。為此,他們從一系列 CC0 授權的開源網站搜集了大約 40,000 個視訊資源,其中包括從 mixkit 獲得的 1,244 個視訊、從 pexels 獲取的 7,408 個視訊以及從 pixabay 收集的 31,617 個無浮水印視訊。按照 Panda70M 提供的場景切換和剪輯方案,這些原始視訊被細分為約 434,000 個獨立的視訊片段。
這批數據來源高達 99% 的視訊都僅包含單一場景,同時超過 60% 的爬取數據屬於風景類視訊內容。
其次,針對 高品質且密集的字幕要求 ,直接在網路上大規模抓取此類字幕頗具挑戰性。團隊於是決定采用先進的影像-字幕模型來生成高標準的字幕內容,對兩款多模態大模型——ShareGPT4V-Captioner-7B 和 LLaVA-1.6-34B 進行了消融實驗。前者專為字幕生成任務設計,後者則是一款通用的大型多模態模型。
實驗結果顯示兩者效能相當,但推理速度有所差異:在 A800 GPU 上,ShareGPT4V-Captioner-7B 以批次處理大小 12 的情況下,每 40 秒能完成一輪推理;而 LLaVA-1.6-34B 在批次處理大小 1 時,每 15 秒即可進行一輪推理。團隊已公布所有相關註釋*,並展示了部份統計數據,在設定模型最大長度為 300 的前提下,這幾乎覆蓋了 99% 的樣本需求。

*: https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0
未來……
關於 CausalVideoVAE 模型 :面對存在的動態模糊和網格效應問題,他們正在進行一系列改進措施,即將推出的增強版本作為「預覽版」,預計在下一次更新時正式釋出。 Open-Sora-Plan 團隊同樣放出了 新版本預覽,提升很大:
關於數據構建的源頭 :上文提到,「60% 的爬取數據屬於風景類視訊內容」,這在一定程度上限制了在其他型別視訊生成上的表現力。盡管現有的大規模開源數據集多數透過抓取 YouTube 等平台獲取,但由於對視訊品質控制的考量,Open-Sora-Plan 團隊選擇持續積累高品質的數據資源。他們正發起名為 Open-Sora-Dataset 的計畫,並邀請開源社群共同參與推薦和建設。
關於字幕生成流程 :鑒於長視訊的需求,有必要研發更為高效的視訊字幕生成解決方案,而不完全依賴於大型多模態影像模型。目前,他們正致力於開發新一代視訊字幕生成管道,旨在提供對長視訊強大而穩定的支持。
關於算力 :計畫發起者之一、北大資訊工程學院助理教授、博導 袁粒 向 CSDN 透露, 針對如何更好地支持國產算力訓練的問題,當前主要與 華為 開展了深度合作,並與其他諸如莫耳執行緒等國產算力平台進行接觸。盡管各家企業在推進合作的進度和流程上存在差異,每家企業的節奏各異,但合作的基本思路是相通的。

星星之火可以燎原
你是如何理解開源精神的?
是 BSD 開花結果孕育 Mac OS X 和 Unix-like?還是 MySQL 在被 Oracle 收購之後催生了 MariaDB 等一系列資料庫?亦或是 Netscape 被微軟逼入絕境後,開源 Mozilla 計畫涅槃重生?
袁粒向 CSDN 表示,Open-Sora-Plan 計畫的 追求 既非完全復現 Sora,更不是要 搶先於 OpenAI 實作「彎道超車」,而是「 開源 」這件事情本身。
「 我們追求的還是開源。開源社群本身的資源是有限的,我們能做的並不是超越,而是給大家提供一個開源版本,大家可以基於此繼續往前推動。 」

目前, 開源社群對 Open-Sora-Plan 的回饋相當熱情 ,GitHub 上已有 6.7 stars。 袁粒認為,開源社群裏不只有個人開發者,許多企業也正在支持開源,他們本身也是開源的一份子,有許多開發者和企業都為 Open-Sora-Plan v1.0.0 的算力&演算法提供了支持。此外,華為也在持續跟進該計畫,他們表示完全尊重開源,並有工程師協助袁粒的團隊做適配。
Open-Sora-Plan 團隊計劃以自身開源為核心,鼓勵合作企業不僅支持開源,具體的協作模式是開放且靈活的:各個國內企業都可以針對開源計畫送出 Pull Request(PR)對現有框架進行適配以適應國產算力平台。團隊會對送出的程式碼進行稽核,確認無誤後將其融入到開源框架中。在適配過程中遇到的技術問題,團隊會與合作企業保持緊密溝通,共同尋求解決方案,確保國產算力與開源框架的有效整合與相容。
透過各方共同努力,逐步建立起一套基於國產算力環境的開源生態體系。
截至 4 月 8 日,Open-Sora-Plan 的社群貢獻者
開源之火,生生不息。
去年 12 月的時候,Linus Torvalds 在日本的開源峰會上曾作出如此分享:
「我還記得三十年前我啟動這個計畫(Linux)時的情景,人們會問我'為什麽'或'你要怎麽賺錢?' 現在,這已經不再是一個問題了。 開源已經成為行業的標準 。」
GitHub 連結 :https://github.com/PKU-YuanGroup/Open-Sora-Plan
Hugging Face 線上演示 :https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0
Open-Sora-Plan 團隊
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的「 全球機器學習技術大會 」將在上海環球港凱悅酒店舉行,特邀近 50 位技術領袖和行業套用專家,與 1000+ 來自電商、金融、汽車、智慧制造、通訊、工業互聯網、醫療、教育等眾多行業的精英參會聽眾,共同探討人工智慧領域的前沿發展和行業最佳實踐。 歡迎所有開發者朋友存取官網 http://ml-summit.org、點選「閱讀原文」或掃碼進一步了解詳情。












