編譯 | 屠敏
出品 | CSDN(ID:CSDNnews)
大佬的話究竟有幾分可信?很多人已經傻傻分不清了,遙記多年前,當 Linux 之父 Linus Torvalds 聲稱要去休假時,他一個人趁著休息時間搗鼓出了如今成為主流的計畫版本管理工具 Git。
現下放到 AI 領域,不久之前,特斯拉前 AI 總監、OpenAI 聯合創始人 Andrej Karpathy 在社交媒體平台 X 上高調宣布,他友好地從 OpenAI 離職,未來將專註於「個人計畫」,而後又口口聲聲說要嘗試性地戒掉上網兩周,去了 Bhutan(不丹王國)休假。
誰承想,就在其宣布回歸互聯網的第三天,他便帶來了自己徒手編寫的 1000 行 C 程式碼即實作 GPT-2 訓練的新計畫—— LLM.c (https://github.com/karpathy/llm.c) ,驚艷眾人。
這款開源計畫一經釋出,便迅速沖到 HN 的 Top 榜,且在 GitHub 上也狂攬 2600 顆星。
而 Andrej Karpathy 本人,也因之前 使用 並成功跑在 MacBook 上的經歷,加上這一次的嘗試,被網友給予了一個肯定的評價——「Real men program in C 」(真男人就應該用 C 編程)。
1000 行 C 程式碼完成 GPT-2 訓練的 LLM.c
根據 GitHub 頁面介紹,llm.c 是一個簡單、純粹的 C/CUDA LLM 訓練計畫。不需要使用 245MB 的 PyTorch 或 107MB 的 cPython 就能用純 C 語言訓練 LLM。
更讓人佩服的是,LLM.c 僅用約 1000 行幹凈的程式碼即可在 CPU/fp32 上實作 GPT-2 訓練。它可以立即編譯並執行,並且與 PyTorch 參考實作完全匹配。
之所以選擇 GPT-2 作為訓練的起點,Andrej Karpathy 表示, 是因為 GPT-2 是 LLM 的鼻祖,這也是大模型堆疊第一次以公認的現代形式組合在一起,並提供了模型權重。
你可以在這裏檢視原始的訓練實施情況:
https://github.com/karpathy/llm.c/blob/master/train_gpt2.c
Andrej Karpathy 透露,這個 計畫在一開始就在一個大的 1D 記憶體塊中一次性分配了所有需要的記憶體。
由此,在訓練過程中不會建立或銷毀記憶體,因此記憶體占用量保持不變,只是動態地將數據批次流過。
這裏的關鍵在於手動實作所有單個層的前向和後向傳遞,然後將它們串聯起來。例如,這裏是 layernorm 的前向和後向傳遞。
除了 layernorm 之外,也還需要編碼器、matmul、自註意力、gelu、殘留誤差、softmax 和交叉熵損失。
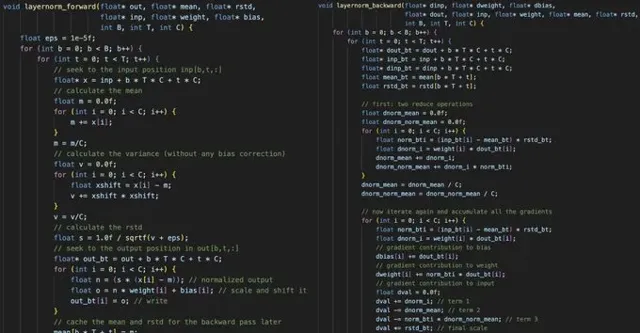
一旦你有了所有的層,你就可以把所有的層串聯起來。
「不瞞你說,寫這個過程相當乏味,也很受虐,因為你必須確保所有的指標和張量偏移都正確排列」,Andrej Karpathy 吐槽道。
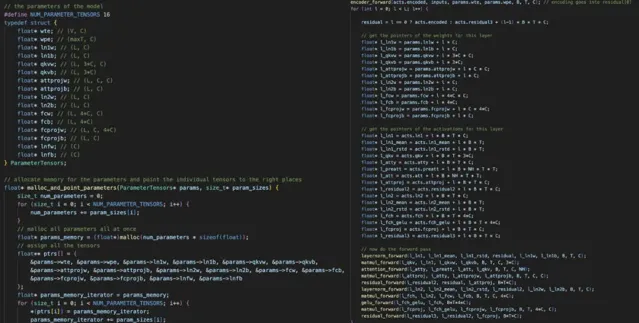
左圖:在記憶體中分配一個單一的 1D 陣列,然後將所有模型權重和啟用指向該陣列;
右圖:非常小心地進行所有指標運算
一旦有了前向/後向,剩下的部份(數據載入器、Adam 更新等)就變得微不足道了。
不過,真正的樂趣才剛剛開始,Andrej Karpathy 分享道,「我現在正在逐層將其移植到 CUDA,這樣它就能變得高效,甚至可以與 PyTorch 相媲美,但卻沒有任何嚴重的依賴性。我已經做了幾層了,這是一項相當有趣的 CUDA 工作。」
在此基礎上,擴充套件包括將精度從 fp32 降低到 fp16/以下,並增加幾層(如 RoPE),以支持更現代的架構,如 llama 2 / mistral / gemma 等。
對此,Andrej Karpathy 也表示,一旦這個計畫進入稍稍穩定的狀態後,他就會從頭開始構建更為詳細的觀看視訊。
立足於當下,Andrej Karpathy 也正在研究:
直接使用 CUDA 實作,這將大大提高速度,並可能接近 PyTorch。
使用 SIMD 指令加速 CPU 版本,X86 上的 AVX2 / ARM 上的 NEON(如 Apple Silicon)。
更現代的架構,如 Llama2、Gemma 等。
對於 GitHub repo,他希望同時維護幹凈、簡單的參考實作,以及更最佳化的版本,這些版本可以接近 PyTorch,但程式碼和依賴性只占很小一部份。
快速開始吧!
基於此,Andrej Karpathy 也為廣大網友直接開始上 LLM.c 的使用步驟,方便大家自己去實踐一把。
首先第一步,下載並 tokenize 數據集。在這裏,Andrej Karpathy 使用了 tinyshakespeare 數據集 (https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt) ,並稱其下載和 tokenize 速度最快:
python prepro_tinyshakespeare.py
輸出:
Saved 32768 tokens to data/tiny_shakespeare_val.binSaved 305260 tokens to data/tiny_shakespeare_train.bin
.bin 檔是由 int32 數位組成的原始字節流,用 GPT-2 tokenizer 表示 token ID。你也可以使用 prepro_tinystories.py 對 TinyStories 數據集進行 tokenize。
原則上,按照步驟走到這裏就可以訓練模型了。
不過, Andrej Karpathy 表示, CPU/fp32 基準參考程式碼的效率很低,從頭開始訓練這些模型還不太現實。相反,他使用 OpenAI 釋出的 GPT-2 權重進行初始化,然後進行微調。為此,必須下載 GPT-2 權重,並將其保存為檢查點,以便在 C 語言中載入:
python train_gpt2.py
你可以從 nanoGPT 中找到這段程式碼,它是 PyTorch 中簡單的 GPT-2 參考實作。
這個指令碼將下載 GPT-2 (124M) 模型,對一批數據進行 10 次叠代過擬合,執行幾步生成,最重要的是它將保存兩個檔:
1)gpt2_124M.bin 檔,其中包含用於在 C 語言中載入的原始模型權重;
2)gpt2_124M_debug_state.bin,其中還包含更多偵錯狀態:輸入、目標、logits 和損失。這對偵錯 C 程式碼、單元測試和確保我們與 PyTorch 參考實作完全匹配非常有用。
現在,我們只關心 gpt2_124M.bin 中的模型權重,以用它們進行初始化,並用原始 C 語言進行訓練:
make train_gpt2
當然,你可以檢視 Makefile 及其註釋。它將嘗試自動檢測你的系統是否支持 OpenMP,這對於以極低的程式碼復雜度為代價加快程式碼速度非常有幫助。train_gpt2 編譯完成後,就可以執行了:
OMP_NUM_THREADS=8 ./train_gpt2
接下來,我們應該根據 CPU 的內核數量來調整執行緒數。程式將載入模型權重和 token,它將在 Adam lr 1e-4 的條件下執行微調 loop,進行幾次叠代,然後根據模型生成樣本。
「該檔(我認為)可讀性很強,你應該看一看。簡單地說,所有層的前向和後向傳遞都有實作方法,它們被串成一個大型的手動前向/後向/更新迴圈。」 Andrej Karpathy 說。
在 MacBook Pro(蘋果 Silicon M3 Max)上,輸出結果是這樣的:
[GPT-2]max_seq_len: 1024vocab_size: 50257num_layers: 12num_heads: 12channels: 768num_parameters: 124439808train dataset num_batches: 1192val dataset num_batches: 128num_activations: 73323776val loss 5.252026step 0: train loss 5.356189 (took 1452.121000 ms)step 1: train loss 4.301069 (took 1288.673000 ms)step 2: train loss 4.623322 (took 1369.394000 ms)step 3: train loss 4.600470 (took 1290.761000 ms)... (trunctated) ...step 39: train loss 3.970751 (took 1323.779000 ms)val loss 4.107781generated: 50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323step 40: train loss 4.377757 (took 1366.368000 ms)
現在,生成器只提供 token ID,我們必須將其解碼為文本。當然也可以用 C 語言輕松實作,因為解碼非常簡單,只需尋找字串塊並打印即可。時下可以使用 tiktoken:
import tiktokenenc = tiktoken.get_encoding("gpt2")print(enc.decode(list(map(int, "50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323".split()))))
輸出:
<|endoftext|>Come Running Away,Greater conquerWith the Imperial bloodthe heaviest host of the godsinto this wondrous world beyond.I will not back thee, for how sweet after birthNetflix against repounder,will notflourish against the earlocks ofAllay
「我喜歡 Netflix 出現的方式,很明顯,模型中還潛藏著過去訓練的影子」, Andrej Karpathy表示,「 我沒有嘗試調整微調超參數,因此很有可能會有很大改進,尤其是在訓練時間更長的情況下。」
除了具體的步驟之外, Andrej Karpathy 還附上了一個簡單的單元測試,以確保 C 程式碼與 PyTorch 程式碼一致。編譯並執行:
make test_gpt2./test_gpt2
現在載入 gpt2_124M_debug_state.bin 檔,執行前向傳遞,比較 logits 和損失與 PyTorch 參考實作,然後用 Adam 進行 10 次叠代訓練,確保損失與 PyTorch 一致。
寫在最後
Andrej Karpathy 時不時丟一個 LLM 相關的個人計畫,還附上詳盡的教程,也讓不少網友開啟膜拜模式:


還有人評價道,在前有很多政府機構將 C/C++ 歸納為不安全的記憶體語言之際,「 我們實際上正在開始一場 C 語言的復興 」。
最後,不得不說,離開企業後的 Andrej Karpathy 更為自由一些,他不僅在 YouTube 上持續分享有關大模型的教學視訊,更是生怕這屆學生看不懂,每次在釋出計畫時,都會附上詳盡的教程。

這不,在釋出 LLM.c 時, Andrej Karpathy 在 doc/layernorm/layernorm.md 中附上了一個很小的教程:這是實作 GPT-2 模型單層(layernorm 層)的一個簡單的分步指南,也是了解如何用 C 語言實作層的一個很好的起點。
來源:
https://twitter.com/karpathy/status/1777427944971083809
https://github.com/karpathy/llm.c
https://github.com/karpathy/llm.c/blob/master/doc/layernorm/layernorm.md
推薦閱讀:
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的「 全球機器學習技術大會 」將在上海環球港凱悅酒店舉行,特邀近 50 位技術領袖和行業套用專家,與 1000+ 來自電商、金融、汽車、智慧制造、通訊、工業互聯網、醫療、教育等眾多行業的精英參會聽眾,共同探討人工智慧領域的前沿發展和行業最佳實踐。 歡迎所有開發者朋友存取官網 http://ml-summit.org、點選「閱讀原文」或掃碼 進一步了解詳情。












