作者 | 唐小引
出品丨AI 科技大本營(ID:rgznai100)
台北時間 5 月 21 日,僅僅時隔一周,李開復再度露面,帶來了他的喜與憂。
喜的一面在於,在 LMSYS 盲測競技場最新排名中,零一萬物的最新千億參數模型 Yi-Large 總榜排名世界模型第 7,中國大模型中第一,已經超過 Llama-3-70B、Claude 3 Sonnet;其中文分榜更是與 GPT-4o 並列世界第一。除了零一萬物的 Yi-Large 之外,通義千問、智譜 AI 的 GLM 亦在 TOP20 之列。
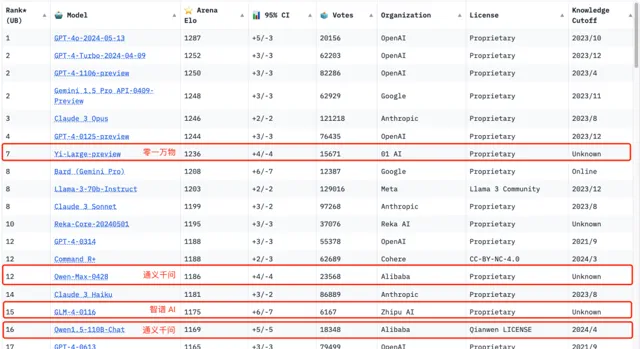
李開復表示中國大模型與美國大模型的差距,從一年多前落後 7-10 年的時間,已經縮小到 6 個月,差距實作了大幅降低。
而憂的一面則是,618 還未至,大模型已經進入了瘋狂降價時。
前有字節跳動釋出豆包大模型, ,一元錢就能買到豆包主力模型的 125 萬Tokens;緊接著阿裏巴巴的通義千問官宣降價並立即生效,降價後,1 元最多=200 萬 Tokens;更甚的是隨之而來的百度官宣:文心大模型兩大主力模型全面免費,立即生效。

面對著這股席卷而來的價格戰之風,有人歡喜有人愁,這個問題的核心關鍵還是在於模型的商業化。賈揚清表示,「今天站在 AI 整個業界的角度,我想說,降價是個拍腦袋就可以做的簡單策略,但是真正的 toB 商業成功更難。」而出門問問創始人李誌飛也這樣說道:「去年四月在經過無腦狂躁後,我就意識到 OpenAI 的兩種商業模式( ToC 會員和 ToB API )在中國競爭環境下都是不永續的。」

對此,李開復這樣評價道:「國內常看到 ofo 式的瘋狂降價、雙輸的打法。 我覺得大模型公司不會這麽不理智,因為技術還是最重要的,如果是技術不行,就純粹靠貼錢賠錢的方式去做生意。 我們(零一萬物)絕對不會跟這樣的一個定價來做對標,我們對自己的模型表現是非常自豪的……如果再問以後可能中國就是這麽卷,大家寧可賠光通輸也不讓你贏,那麽我們就走海外市場。」
大模型競技場,中國大模型嶄露頭角
前段時間,一款名為「 」的神秘模型突然現身大模型競技場 LMSYS Chatbot Arena,排名直接超過了 GPT-4-Turbo、Gemini 1 .5 Pro、Claude 3 0pus、Llama-3-70b 等各家國際大廠的當家基座模型。正當 AI 圈裏眾說紛紜地猜測其究竟來自哪裏、是否是 OpenAI 開發的 GPT-4.5 時,OpenAI 揭開了其神秘面紗,正是 GPT-4o 的測試版本,而 OpenAI CEO Sam Altman 也在 GPT-4o 釋出後親自轉帖參照 LMSYS Arena 盲測擂台的測試結果。
LMSYS Org 是一個開放的研究組織,由加州大學柏克萊分校、聖地亞哥分校和卡內基梅隆大學的學生與教師共同創立。其釋出的 Chatbot Arena 以盲測的方式,由使用者在模型匿名的前提下對模型效果進行打分,頗受業內認可,已經成為 OpenAI、Anthropic、Google、Meta 等國際大廠的大模型競技場。
如下所示,在不知道具體使用哪個模型的前提下,先在聊天框裏輸入 Prompt,基於模型的回答品質滿意度進行投票,投票後會顯示出所用模型來。
LMSYS Chatbot Arena 盲測競技場公開投票地址:https://arena.lmsys.org/
在其最新榜單中,智譜 GLM4、阿裏 Qwen Max 及 Qwen 1.5、零一萬物 Yi-Large 及 Yi-34B-chat 都有參與盲測,在總榜之外,LMSYS 的語言類別上新增了英語、中文、法文三種語言評測,開始註重全球大模型的多樣性。Yi-Large 的中文語言分榜上拔得頭籌,與 OpenAI 官宣才一周的地表最強 GPT4o 並列第一,Qwen-Max 和 GLM-4 在中文榜上也都表現不凡。
頗值得開發者註意的是,在編程能力(Coding)排行榜上,Yi-Large 的 Elo 分數超過 Anthropic 當家旗艦模型 Claude 3 Opus,僅低於 GPT-4o,與 GPT-4-Turbo、GPT-4 並列第二。
對此,李開復表示,Yi-Large 是通用模型,並沒有針對 Coding 的場景專門最佳化。在 CSDN 基於 Coding 的進一步詢問中,零一萬物技術聯合創始人黃文灝補充道:「我們分析過使用者需求,Coding 並不是大家非常廣泛使用的場景,對於程式設計師而言,在實際場景中面對非常專業的 Coding 問題一般會用一些專門的 Coding 模型。我們也很驚奇 Yi-Large 在 Coding 上的評測表現非常好。當前,我們正在做一些 Coding 專項的最佳化,對於模型能力而言,編程是一個非常重要的場景, 我們正在著手 Coding 專門模型的開發,在程式碼覆寫、長程式碼續寫、程式碼補全等方面有著非常好的效能表現,之後我們會陸續將 Coding 專項模型開放出來。 」
差距、降價、多模態……李開復直面若幹問題
問:當前中美之間的差距是怎樣的,該如何追趕?
李開復: 我不是特別認為我們跟全球有差距,當然如果要在頭部之間 PK 是有一定的差距,但是同時可能要考慮到人才、算力等的差異。Google 團隊是 2000 人,OpenAI 是 1000 人,在我們這裏把模型和 Infra 加起來也不到 100 人,而且我們用 GPU 算力做模型訓練不到他們的 1/10,我們的模型尺寸也不到其 1/10。
如果只評估千億模型,至少在 LMSYS 這個排行榜上是世界第一,這一點我們還是很自豪。在一年前我們落後 OpenAI 與 Google 開始做大模型研發的時間點有 7 到 10 年,現在我們跟他們差距在 6 個月左右,這個已經大幅降低。
這 6 個月是怎麽來的?可以回到 LMSYS 6 個月以前的榜,或者今天比我們排名在前面的幾家,幾乎都是今年發出來的模型,去年的模型還在榜單上,我們已經打敗了。
另一個角度來看,我們最新釋出的模型在 5 月時可以打敗去年 11 月之前的任何模型,所以我覺得也可以科學地推理出我們落後 6 個月。
6 個月的差別不是很大,這是一個不可思議的超級速度的趕追。
那麽美國人才有沒有獨特的地方?肯定是有的,從我寫的【AI·未來】這本書之後,我一直都堅持美國是做突破性科研,有著創造力特別強的一批科學家,在這方面全世界是沒有對手的。但在同一本書裏我也說了, 中國人的聰明、勤奮、努力是不容忽視的 ,我們把這 7-10 年降低到只有 6 個月,就驗證了做好一個模型絕對不只是看多能寫論文,多能發明新事物,先做或後做,做得最好才是最強的,Google 搜尋比雅虎晚做很多,但是完全無法比擬。所以我認為後發有後發的優勢,但同時我們特別尊敬美國的創造性,有很多值得學習的地方。但是 比執行力,比做出很好的體驗,比產品,比商業模式,我覺得我們強於美國公司。
問:零一萬物後續會推出更大參數的模型嗎?現在一些企業開始做小模型,您認為現在卷參數還有意義嗎?
李開復: 我們的計劃是從最小到最大的模型都希望能夠做到中國最好,所以除了 6B、9B、34B, 未來我們可能有更小的模型釋出, 它們都是同樣尺寸達到業界最佳,不敢說第一,但是總體來說是第一梯隊或者是 TOP1/2 這樣的表現,而且在諸如程式碼、中文、英文等很多方面表現都非常好。
我們相信就像一周前我講的 ,永遠是一個蹺蹺板,要平衡需要多強的技術,付不付得起技術所需要的成本。業界有各種不同的套用,從最簡單的客服套用,到遊戲,一直到非常難的推理策略、科學發現等難度,我相信大尺寸的 Scaling Law,最強大地往 AGI 走的模型,在最難的問題上,大家又願意花錢的領域裏,絕對是有落地場景,而且是最有可能達到 AGI。
同時我們也坦誠,有各種比較小的簡單套用的機會。我們的打法是一個都不放過,在每一個潛在尺寸上釋出我們能做到效能最高,而且推理成本最低,這個推理成本也會帶來更好的定價給開發者使用。
問:零一萬物的 GPU 可能是 Google、微軟的 5%,算力對模型發展的限制是客觀存在的。 面對 OpenAI、Google 的能力、資源均靠前的情況,零一萬物怎麽應對?
李開復: 這個 更精確的應該從歷史數據來看,看在過去的一兩年他們提升了多少,我們提升了多少,我們是不是追得非常近了,這是一個客觀事實。
我不認為他們的算力更大就表示我們絕對沒有機會,當然他們的算力更大有巨大的優勢,但是我覺得客觀事實是 我們能夠把同樣的一張 GPU 擠出更多的價值來,這是今天我們能夠達到這些成果的一個重要理由。
另外是最佳化模型的效能表現,它不只是一個純粹科技和演算法的問題,其中還有數據的配比、怎麽最佳化,同時最佳化訓練和作用,還有我們的模型怎麽加入多模態等等各種方面的技術,我們其實在這方面是不輸於美國。
我們算力一直遠遠落後,一年前算力也是只有 Google、OpenAI 的 5%,現在還是,如果用 5%的算力能夠把落後快速拉近,未來我們還是很期待有驚人的結果。
能不能達到第一,能不能超過,當然是一個艱難的任務,但我們是朝著這個目標在努力,今天的結果對比一周前,對比去年 11 月,對比我們成立的時候,都是一個不可思議的飛躍,所以看事情要看其是在上漲還是下跌,而非今天還是落後,以後就會落後。
問:現在國內打起了大模型價格戰,在這個過程中零一萬物和其他初創公司如何在競爭中跑贏大廠?
李開復: 我們關註到了這個現象,我們的定價還是非常合理,而且也在花很大精力希望能夠讓它再降下來,我覺得一定程度上整個行業每年降低 10 倍推理成本是可以期待的,而且必然也應該發生的。今天可能處在一個比較低的點,但是我覺得如果說以後大約以一年降價 10 倍來看,這是一個好訊息,因為今天的 API 模型呼叫還是一個非常低的比例,如果一年降低 10 倍,那眾多的人都可以用上。
我們也認為今天可以看到的模型表現零一超過其他模型,也歡迎不認同的友商來 LMSYS 打擂台,證明我是錯的。但是直到那一天發生,我們會繼續說我們是最好的模型。
對要求、需求都最高的,需要最好模型的使用者當然會使用我們。100 萬個 token 花十幾塊還是花幾塊錢有很大差別嗎?100 萬的 token 對於很大、很難的套用,我們是必然之選。我們釋出之後得到國內外非常高的評價,而且是可以橫跨中國和外國的 API,都開放,我們有信心在全球範疇是一個表現很好、價效比也很合理的一個模型。
當然,國內常看到 ofo 式的瘋狂降價,雙輸的打法。我覺得大模型公司不會這麽不理智,因為技術還是最重要的,如果是技術不行,就純粹靠貼錢賠錢去做生意,我們絕對不會跟這樣的一個定價來做對標,我們對自己的模型表現是非常自豪的。
就像你如果有一台特斯拉,它不會因為別的品牌的車比它賣的很便宜,它就覺得它要降價,我們就是特斯拉,我們的價錢是合適值得的。
如果再問以後可能中國就是這麽卷,大家寧可賠光通輸也不讓你贏,那我們就走海外市場。
問:GPT-4o 開始做原生多模態模型,統一文本、音訊、影像、視訊的輸入輸出的多模態大模型會是一個確定方向嗎?可否透露一下零一萬物在多模態的進展。
李開復: 我們在去年一直都認可全模態模型,omni,也就是我們挑了同樣的詞已經在做這個工作,這個工作不是 OpenAI 出來再跟風能夠跟得上的,我們有一定的積累,我們也相信全模態是正確方向。從我們的釋出周期來說,在今年你們可以期待一個驚喜。
問:零一的 API 價格會不會下降?
李開復: 現在沒有調整的訊息可以分享,我們收到的反饋還是非常正面的。我認為模型要看它的表現,可能有些領域,比如說一些很難收回錢的領域要看價格,反正有足夠多的在選我們,我們剛上線,有這麽多忠誠的愛好者加入了,我們先服務好他們,價錢再說。
到今天為止,我們剛宣布的效能肯定是國內價效比最高。大家可能有用千 token、百萬 token,可以自己測算一下。
問:零一萬物在產品化方面未來有沒有一些規劃?
李開復: 有,上周釋出的產品基本是我們的方向,一方面我們已經推出了一些非常成功的海外產品,已經在海外取得非常好的成功,今年預期會有大概 1 個億的收入,而且不是燒錢模式燒出來的。
另外還有幾個其他產品在國內外測試中,當然萬知我們也會繼續努力把它越做越好,尤其我們對 PPT 的功能得到非常正面的反饋,因為這是一個跟國內其他大模型很大的差異點,這個是我們面對消費者產品的分享。
在企業級方面也正在進行中,但現在初步使用者在國外,國外使用者的付費意願或者付費金額比國內大很多,所以雖然我們也非常期望服務國內使用者,但按照現在 ToB 卷的情況,幾十萬做 POC,幾百萬做一單,做一單賠一單的生意,我們早期在 AI 1.0 時代太多了,投入多了,我們堅決不做。
開發者正在迎接新一輪的技術浪潮變革。由 CSDN 和高端 IT 咨詢和教育平台 Boolan 聯合主辦的 2024 年度「全球軟體研發技術大會」秉承幹貨實料(案例)的內容原則,將於 7 月 4 日-5 日在北京正式舉辦。大會共設定了 12 個大會主題:大模型智慧套用開發、軟體開發智慧化、AI 與 ML 智慧運維、雲原生架構……詳情👉: http://sdcon.com.cn/












