哈嘍,大家好呀!
今天來給大家分享 Excel365新增的兩個文本提取函式。
TEXTBEFORE:是提取指定字元之前的內容
TEXTAFTER:是提取指定字元之後的內容
可按照 指定的字元 ( 符號、數位、字母、文字 ) 將文本分成前後兩半進行提取 。
兩個函式的語法結構完全一樣,都有六個參數。
即:(文本,分隔符,[例項數目],[匹配模式],[搜尋模式],[未找到匹配項時的返回值])
下面,用一些案例來講解這兩個函式的用法吧!
一、按符號提取個人資訊的姓名和手機號
冒號前的內容就是姓名,公式為=TEXTBEFORE(A2,":");
冒號後的內容就是手機號,公式為=TEXTAFTER(A2,":")。
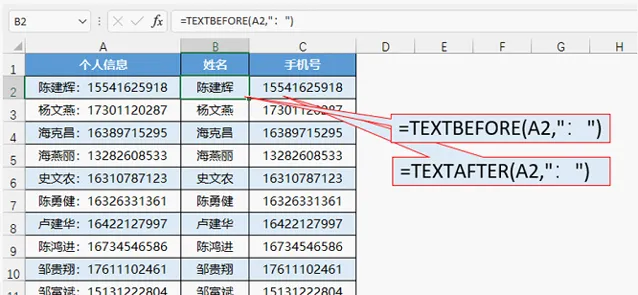
透過這個範例,大家就知道了兩個函式的第一參數是要提取的文本,第二參數是分隔符號。
二、將文字作為分隔符號提取姓名
公式=TEXTBEFORE(A2,"常用")
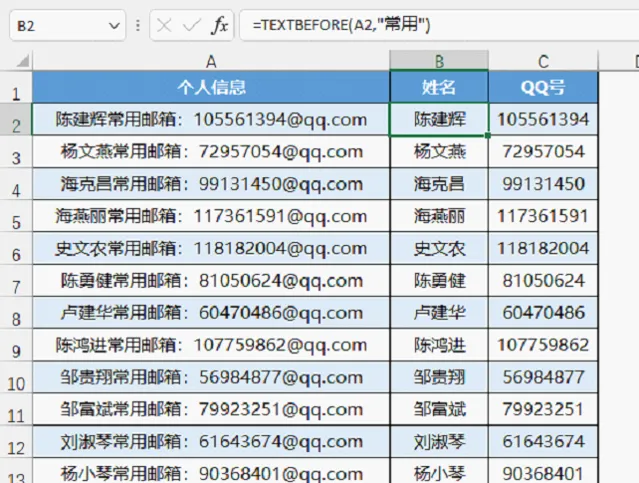
這個範例說明分隔符號可以是文字,且可以是多個文字。
三、TEXTBEFORE和TEXTAFTER組合提取
提取QQ號的公式=TEXTBEFORE(TEXTAFTER(A2,":"),"@")
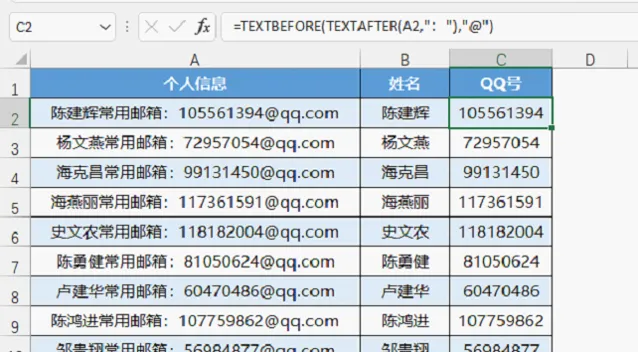
先用TEXTAFTER(A2,":")提取冒號之後的內容,再用TEXTBEFORE提取@之前的內容。
四、同一分隔符有多個可以指定用哪個

提取業主姓名的公式=TEXTBEFORE(TEXTAFTER(A2,"_",2),"_",1)。業主姓名是在第二個「_」和第三個「_」之間,這就用到了兩個函式的第三參數,指定用第幾個分隔符截取。
五、同時按不同分隔符提取內容
例如下面範例,要求提取規格裏的包裝數,即*後面的數位。
公式為=TEXTBEFORE(TEXTAFTER(B2,"*"),{"袋","粒","瓶"})
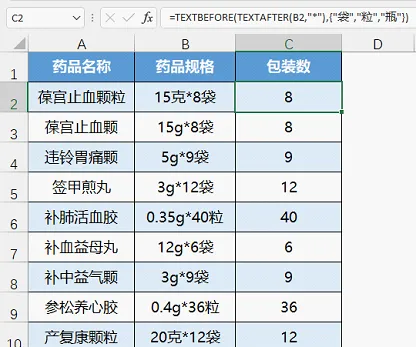
首先用TEXTAFTER(B2,"*")提取*後面的內容,然後再提取"袋"、"粒"、"瓶"前面的內容。各分隔符都置於一組大括弧內。
六、當分隔符是字母,註意要區分大小寫
函式的第四參數為0時區分大小寫,為1是不區分大小寫。
例如提取規格中的克數,下方是第四參數為0和1的對比。
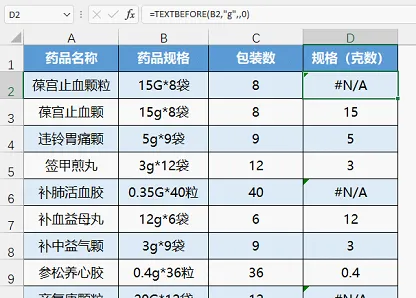
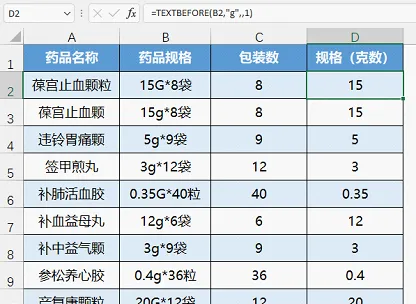
規格為ml的,返回了錯誤值,因為它不是按克計量。
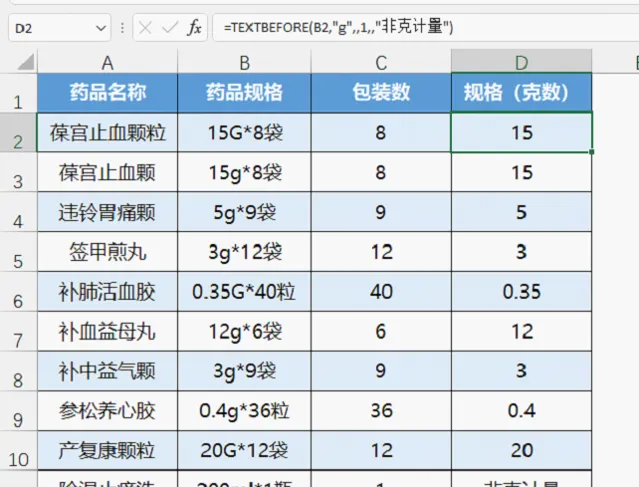
七、啟動第六參數,替換掉錯誤值
公式修改為:=TEXTBEFORE(B2,"g",,1,,"非克計量")
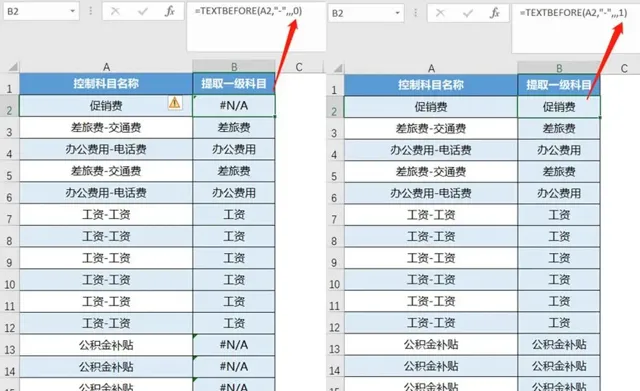
八、沒有分隔符,可以啟用神奇的第五參數
第五參數[match_end]的作用是是否匹配到端,0為不匹配到端,1為匹配到端。
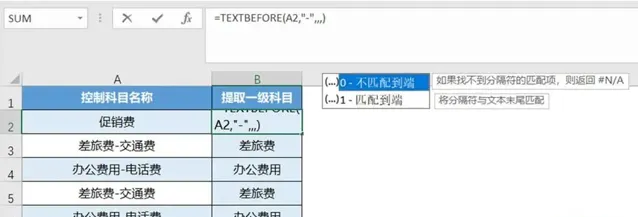
【匹配到端】用大白話說就是當沒有分隔符的時候,直接返回文本自身。
如下圖所示,第5參數寫作0,沒有分隔符的內容就會返回錯誤值;第5參數寫作1,沒有分隔符的內容就會返回它本身。
以上就是TEXTBEFORE和TEXTAFTER函式的使用教程,大家一定要好好練習,徹底掌握這兩個函式。
粉絲福利:免費課程,掃碼領取學習












