今天這個題目比較有意思。
在核查產品時,為了不遺漏,我們往往需要把產品名稱中的程式碼和規格型號拆分出來方便統計核對。
下表我截取了一份公司的【標準件規格統計表】給大家。在遵循一定規則的前提下,標準件的規格型號的表達形式有千種萬種:
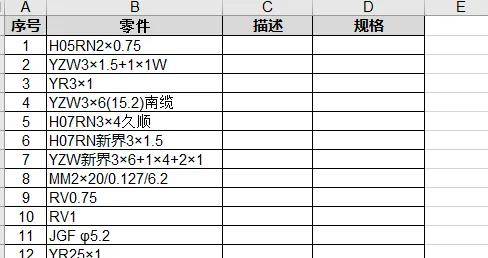
現在我們需要將標準件的名稱拆分為兩部份: 程式碼( 描述 )部份及具體的規格型號,如下表。
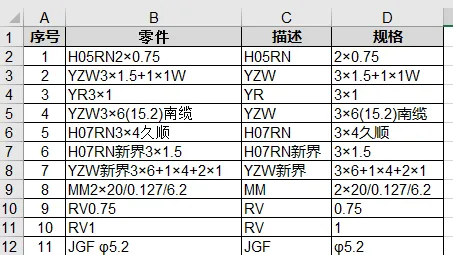
這就牽扯到數據拆分,而凡是這種操作都離不開尋找、參照等函式。 所以,這裏的思路是: 找到程式碼(描述)部份和規格部份的界限,再利用提取函式進行提取和拆分。
但是觀察一下這份源數據中產品的程式碼和規格型號很雜亂,沒有規律可言。那如何才能將兩者精確拆分開呢?
真的沒有規律嗎?其實還是有一定規律的:
(1)凡是有「×」符號的規格型號都是從第一個「×」前的數位開始的
(2)有一個產品的規格型號是從空格後開始的(JGF φ 5.2 → φ 5.2 )
(3)沒有「×」符號和空格的兩個零件的規格型號可以虛擬添加「×」,然後也是從第一個「×」前的數位開始的
RV0.75 →RV0.75 × →0.75 ×
RV1 → RV1 × → 1 ×
如何運用這裏的規律呢?當然還得繼續整合或者創造規律:
(1)和(3)均是從第一個「×」前的最後一個非數位(字母、漢字)後開始規格型號的
(2)也可以認為是從第一個空格前的最後一個非數位(字母、漢字)後開始規格型號的
到了這裏,我們可以得出一個思路 (盡管還不知道用什麽函式實作):
將產品資訊看作是一串數位、非數位組成的資訊,然後從左向右提取到第一個分界標誌「×」或空格前的最後一個非數位處,即可得到程式碼(描述)部份;剩下的就是規格型號部份。
這個思路的關鍵: 將資訊的每個字元判斷成一串代表數位和非數位的序列;用「×」或空格作為參考位置,然後向前尋找最後一個非數位的字元位置。
思考十秒鐘,讓我們一起來燒腦吧!
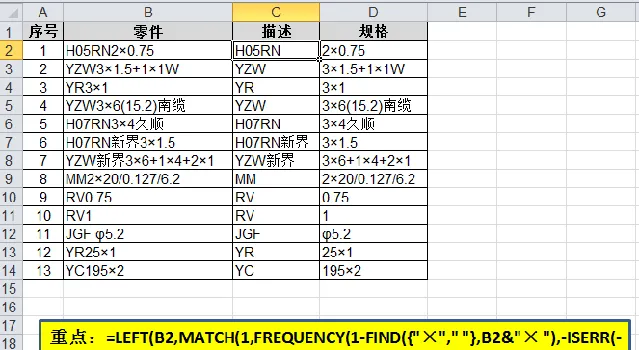
在單元格C2中輸入公式「=LEFT(B2,MATCH(1,FREQUENCY(1-FIND({"×"," "},B2&"× "),-ISERR(-(0&MID(B2&"× ",ROW($1:$99),1)))*ROW($1:$99)),))」並向下拖曳即可。
函式解析:
a) FIND({"×"," "},B2&"× ") 部份用於獲得參考位置,1-FIND(),其結果為{-6,-12},將參考位置變成負數並向前移一位。
為什麽B2要添加字尾"× " (×和空格)?我們用第一個「×」和" " 的位置作為參考,添加字尾"× "可以令FIND函式不論如何都能尋找到"×"和" ",避免FIND函式報錯。
b) -ISERR(-(0&MID(B2&"× ",ROW($1:$99),1)))*ROW($1:$99)) 部份返回一個序列陣列,每個負數對應一個非數位字元(字母或者漢字、符號),每個0對應一個數位字元。得到的序列如下:
{-1;0;0;-4;-5;0;-7;0;0;0;0;-12;0;0;0;0;0;……}( 此處只截取了序列前方部份)
字串B2後添加"× "是為了讓字串與上面尋找的字串保持一致,避免後續出現計算錯誤。
c) FREQUENCY() 部份,計算 參考位置前移後陣列{-6,-12} 在序列中各值段的出現頻率。根據FREQUENCY函式的特性,分別在-5和-12的位置上各計頻1,得到如下序列:
{0;0;0;0; 1 ;0;0;0;0;0;0; 1 ;0;0;0;0;0;……}( 此處只截取了序列前方部份)
d) 再利用MATCH函式尋找1,返回上述序列值中第一個1的位置5。至此得到了「×」和空格前的最後一個非數位字元的位置。
e) 最後用LEFT函式提取5個字元得到描述部份H05RN。
程式碼部份完成後,規格型號部份就非常簡單了,使用SUBSTITUTE函式配合TRIM函式就可以完成。
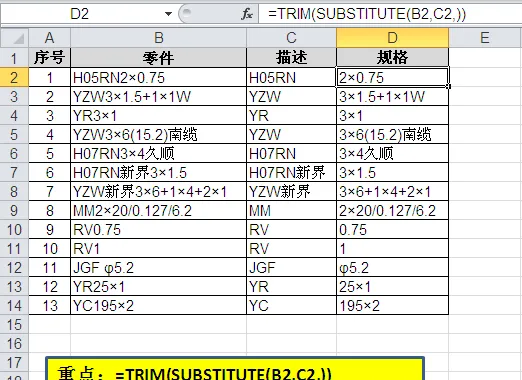
1. SUBSTITUTE (B2,C2,)部份顯示的是用空白替換在B2字元中,與C2相同的字元內容,即留下除去C2字元內容的B2的剩下字元。
2. =TRIM() 即除了單詞之間的單個空格外,清除字元中所有的空格。
這個題目思路整體上比較復雜,小夥伴們一時不能理解也沒有關系,在實際工作中如果遇到類似的問題會套用即可。
最後,歡迎加入Excel函式訓練營,學習68個函式、配套練習課件、輔導答疑。











