如果面试官问我:Redis为什么这么快?
我肯定会说:因为Redis是内存数据库!如果不是直接把数据放在内存里,甭管怎么优化数据结构、设计怎样的网络I/O模型,都不可能达到如今这般的执行效率。
但是这么回答多半会让我直接回去等通知了。。。因为面试官想听到的就是数据结构和网络模型方面的回答,虽然这两者只是在内存基础上的锦上添花。
说这些并非为了强调网络模型并不重要,恰恰相反,它是Redis实现高吞吐量的重要底层支撑,是「高性能」的重要原因,却不是「快」的直接理由。
本文将从BIO开始介绍,经过NIO、多路复用,最终说回Redis的Reactor模型,力求详尽。本文与其他文章的不同点主要在于:
1、不会介绍同步阻塞I/O、同步非阻塞I/O、异步阻塞I/O、异步非阻塞I/O等概念,这些术语只是对底层原理的一些概念总结而已,我觉得没有用。底层原理搞懂了,这些概念根本不重要,我希望读完本文之后,各位能够不再纠结这些概念。
2、不会只拿生活中例子来说明问题。之前看过特别多的文章,这些文章举的「烧水」、「取快递」的例子真的是深入浅出,但是看懂这些例子会让我们有一种我们真的懂了的错觉。尤其对于网络I/O模型而言,很难找到生活中非常贴切的例子,这种例子不过是已经懂了的人高屋建瓴,对外输出的一种形式,但是对于一知半解的读者而言却犹如钝刀杀人。
牛皮已经吹出去了,正文开始。
1. 一次I/O到底经历了什么
我们都知道,网络I/O是通过Socket实现的,在说明网络I/O之前,我们先来回顾(了解)一下本地I/O的流程。
举一个非常简单的例子,下面的代码实现了文件的拷贝,将 file1.txt 的数据拷贝到 file2.txt 中:
publicstaticvoidmain(String[] args)throws Exception {
FileInputStream in = new FileInputStream("/tmp/file1.txt");
FileOutputStream out = new FileOutputStream("/tmp/file2.txt");
byte[] buf = newbyte[in.available()];
in.read(buf);
out.write(buf);
}
这个I/O操作在底层到底经历了什么呢?下图给出了说明:
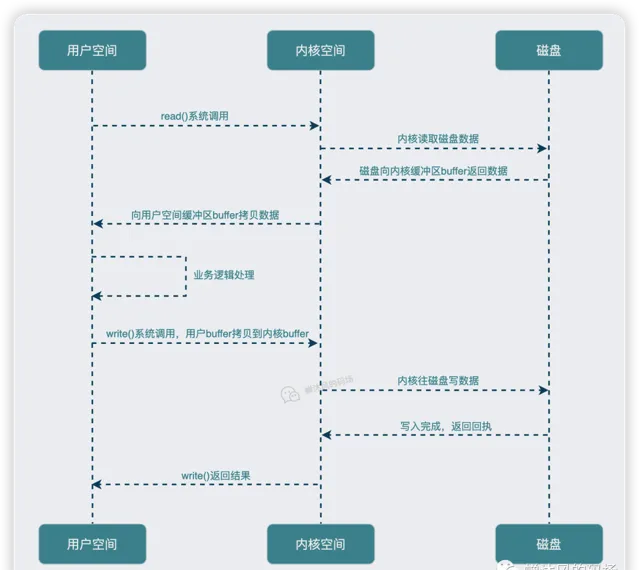
大致可以概括为如下几个过程:
in.read(buf)
执行时,程序向内核发起
read()
系统调用;
操作系统发生上下文切换,由用户态(User mode)切换到内核态(Kernel mode),把数据读取到内核缓冲区 (buffer)中;
内核把数据从内核空间拷贝到用户空间,同时由内核态转为用户态;
继续执行
out.write(buf)
;
再次发生上下文切换,将数据从用户空间buffer拷贝到内核空间buffer中,由内核把数据写入文件。
之所以先拿本地I/O举个例子,是因为我想说明I/O模型并非仅仅针对网络IO(虽然网络I/O最常被我们拿来举例),本地I/O同样受到I/O模型的约束。比如在这个例子中,本地I/O用的就是典型的BIO,至于什么是BIO,稍安勿躁,接着往下看。
除此之外,通过本地I/O,我还想向各位说明下面几件事情:
我们编写的程序本身并不能对文件进行读写操作,这个步骤必须依赖于操作系统,换个词儿就是「内核」;
一个看似简单的I/O操作却在底层引发了多次的用户空间和内核空间的切换,并且数据在内核空间和用户空间之间拷贝来拷贝去。
不同于本地I/O是从本地的文件中读取数据,网络I/O是通过网卡读取网络中的数据,网络I/O需要借助Socket来完成,所以接下来我们重新认识一下Socket。
2. 什么是Socket
这部分在一定程度上是我的强迫症作祟,我关于文章对知识点讲解的完备性上对自己近乎苛刻。我觉得把Socket讲明白对接下来的讲解是一件很重要的事情,看过我之前的文章的读者或许能意识到,我尽量避免把前置知识直接以链接的形式展示出来,我认为会割裂整篇文章的阅读体验。
不割裂的结果就是文章可能显得很啰嗦,好像一件事情非得从盘古开天辟地开始讲起。因此,如果各位觉得对这个知识点有足够的把握,就直接略过好了~
我们所做的任何需要和远程设备进行交互的操作,并非是操作软件本身进行的数据通信。举个例子就是我们用浏览器刷B站视频的时候,并非是浏览器自身向B站请求视频数据的,而是必须委托操作系统内核中的协议栈。
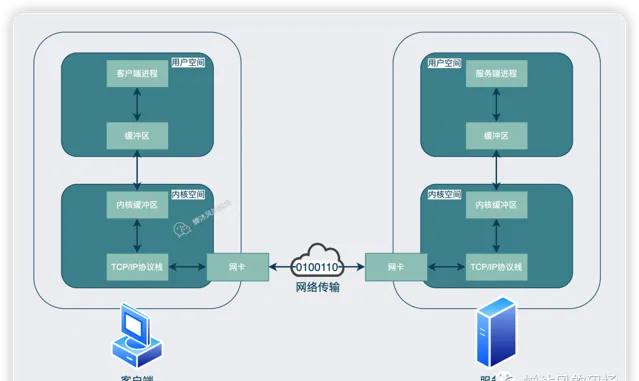
协议栈就是下边这些书的代码实现,里边包含了TCP/IP及其他各种网络实现细节,这样解释应该好理解吧。

而Socket库就是操作系统提供给我们的,用于调用协议栈网络功能的一堆程序组件的集合,也就是我们平时听过的操作系统库函数,Socket库和协议栈的关系如下图所示。
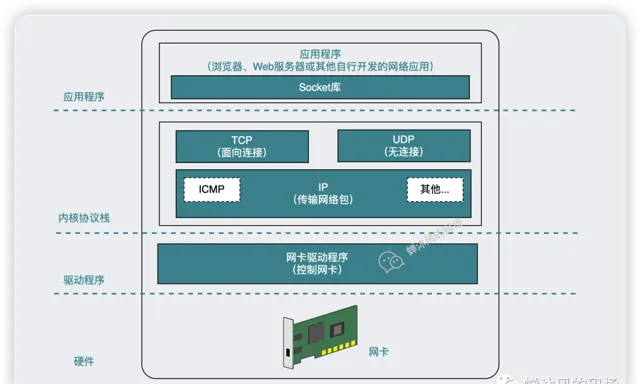
用户进程向操作系统内核的协议栈发出委托时,需要按照指定的顺序来调用 Socket 库中的程序组件。
本文的所有案例都以TCP协议为例进行讲解。
大家可以把数据收发想象成在两台计算机之间创建了一条数据通道,计算机通过这条通道进行数据收发的双向操作,当然,这条通道是逻辑上的,并非实际存在。
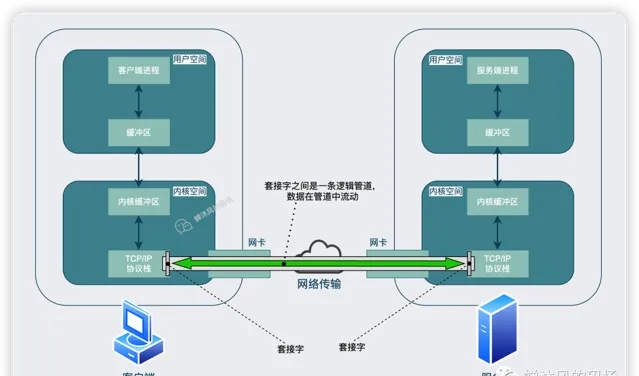
数据通过管道流动这个比较好理解,但是问题在于这条管道虽然只是逻辑上存在,但是这个「逻辑」也不是光用脑袋想想就会出现的。就好比我们手机打电话,你总得先把号码拨出去呀。
对应到网络I/O中,就意味着双方必须创建各自的数据出入口,然后将两个数据出入口像连接水管一样接通,这个数据出入口就是上图中的套接字,就是大名鼎鼎的socket。
客户端和服务端之间的通信可以被概括为如下4个步骤:
服务端创建socket,等待客户端连接(创建socket阶段);
客户端创建socket,连接到服务端(连接阶段);
收发数据(通信阶段);
断开管道并删除socket(断开连接)。
每一步都是通过特定语言的API调用Socket库,Socket库委托协议栈进行操作的。socket就是调用Socket库中程序组件之后的产成品,比如Java中的ServerSocket,本质上还是调用操作系统的Socket库,因此下文的代码实例虽然采用Java语言,但是希望各位读者注意: 只有语法上抽象与具体的区别,socket的操作逻辑是完全一致的 。
但是,我还是得花点口舌啰嗦一下这几个步骤的一些细节,为了不至于太枯燥,接下来将这4个步骤和
BIO
一起讲解。
3. 阻塞I/O(Blocking I/O,BIO)
我们先从比较简单的客户端开始谈起。
3.1 客户端的socket流程
public classBlockingClient{
publicstaticvoidmain(String[] args){
try {
// 创建套接字 & 建立连接
Socket socket = new Socket("localhost", 8099);
// 向服务端写数据
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("我是客户端,收到请回答!!\n");
bufferedWriter.flush();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String line = bufferedReader.readLine();
System.out.println("收到服务端返回的数据:" + line);
} catch (IOException e) {
// 错误处理
}
}
}
上面展示了一段非常简单的Java BIO的客户端代码,相信你们一定不会感到陌生,接下来我们一点点分析客户端的socket操作究竟做了什么。
Socket socket = new Socket("localhost", 8099);
虽然只是简单的一行语句,但是其中包含了两个步骤,分别是创建套接字、建立连接,等价于下面两行伪代码:
<描述符> = socket(<使用IPv4>, <使用TCP>, ...);
connect(<描述符>, <服务器IP地址和端口号>, ...);
注意:
文中会出现多个关于*ocket的术语,比如Socket库,就是操作系统提供的库函数;socket组件就是Socket库中和socket相关的程序的统称;socket()函数以及socket(或称:套接字)就是接下来要讲的内容,我会尽量在描述过程中不产生混淆,大家注意根据上下文进行辨析。
3.1.1 何为socket?
上文已经说了,逻辑管道存在的前提是需要各自先创建socket(就好比你打电话之前得先有手机),然后将两个socket进行关联。客户端创建socket非常简单,只需要调用Socket库中的socket组件的
socket()
函数就可以了。
<描述符> = socket(<使用IPv4>, <使用TCP>, ...);
客户端代码调用
socket()
函数向协议栈申请创建socket,协议栈会根据你的参数来决定socket是
IPv4
还是
IPv6
,是
TCP
还是
UDP
。除此之外呢?
基本的脏活累活都是协议栈完成的,协议栈想传递消息总得知道目的IP和端口吧,要是你用的是
TCP
协议,你甚至还得记录每个包的发送时间以及每个包是否收到回复,否则
TCP
的超时重传就不会正常工作。。。等等。。。
因此,协议栈会申请一块内存空间,在其中存放诸如此类的各种控制信息,协议栈就是根据这些控制信息来工作的,这些控制信息我们就可以理解为是socket的实体。怎么样,是不是之前感觉虚无缥缈的socket突然鲜活了起来?
我们看一个更鲜活的例子,我在本级上执行
netstat -anop
命令,得到的每一行信息我们就可以理解为是一个socket,我们重点看一下下图中标注的两条。
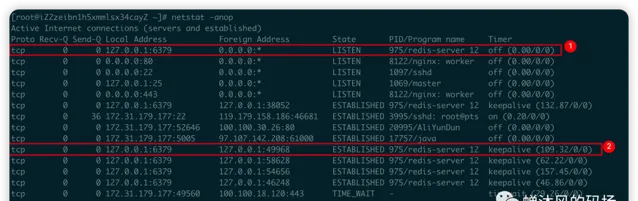
这两条都是
redis-server
的socket信息,第1条表示
redis-server
服务正在IP为
127.0.0.1
,端口为
6379
的主机上等待远程客户端连接,因为Foreign address为
0.0.0.0:*
,表示通信还未开始,IP无法确定,因此State为
LISTEN
状态;第2条表示
redis-server
服务已经建立了与IP为
127.0.0.1
的客户端之间的连接,且客户端使用
49968
的端口号,目前该socket的状态为
ESTABLISHED
。
协议栈创建完socket之后,会返回一个描述符给应用程序。描述符用来识别不同的socket,可以将描述符理解成某个socket的编号,就好比你去洗澡的时候,前台会发给你一个手牌,原理差不多。
之后对socket进行的任何操作,只要我们出示自己的手牌,啊呸,描述符,协议栈就能知道我们想通过哪个socket进行数据收发了。
至于为什么不直接返回socket的内存地址以及其他细节,可以参考我之前写的文章
3.1.2 何为连接?
connect(<描述符>, <服务器IP地址和端口号>, ...);
socket刚创建的时候,里边没啥有用的信息,别说自己即将通信的对象长啥样了,就是叫啥,现在在哪儿也不知道,更别提协议栈,自然是啥也知道!
因此,第1件事情就是应用程序需要把服务器的
IP地址
和
端口号
告诉协议栈,有了街道和门牌号,接下来协议栈就可以去找服务器了。
对于服务器也是一样的情况,服务器也有自己的socket,在接收到客户端的信息的同时,服务器也得知道客户端的
IP
和
端口号
啊,要不然只能单线联系了。因此对客户端做的第1件事情就有了要求,必须把客户端自己的
IP
以及
端口号
告知服务器,然后两者就可以愉快的聊天了。
这就是 3次握手 。
一句话概括连接的含义: 连接实际上是通信的双方交换控制信息,并将必要的控制信息保存在各自的socket中的过程 。
连接过后,每个socket就被4个信息唯一标识,通常我们称为四元组:

趁热打铁,我们赶紧再说一说服务器端创建socket以及接受连接的过程。
3.2 服务端的socket流程
public classBIOServerSocket{
publicstaticvoidmain(String[] args){
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8099);
System.out.println("启动服务:监听端口:8099");
// 等待客户端的连接过来,如果没有连接过来,就会阻塞
while (true) {
// 表示阻塞等待监听一个客户端连接,返回的socket表示连接的客户端信息
Socket socket = serverSocket.accept();
System.out.println("客户端:" + socket.getPort());
// 表示获取客户端的请求报文
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// 读操作也是阻塞的
String clientStr = bufferedReader.readLine();
System.out.println("收到客户端发送的消息:" + clientStr);
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("ok\n");
bufferedWriter.flush();
}
} catch (IOException e) {
// 错误处理
} finally {
// 其他处理
}
}
}
上面一段是非常简单的Java BIO的服务端代码,代码的含义就是:
创建socket;
将socket设置为等待连接状态;
接受客户端连接;
收发数据。
这些步骤调用的底层代码的伪代码如下:
// 创建socket
<Server描述符> = socket(<使用IPv4>, <使用TCP>, ...);
// 绑定端口号
bind(<Server描述符>, <端口号等>, ...);
// 设置socket为等待连接状态
listen(<Server描述符>, ...);
// 接受客户端连接
<新描述符> = accept(<Server描述符>, ...);
// 从客户端连接中读取数据
<读取的数据长度> = read(<新描述符>, <接受缓冲区>, <缓冲区长度>);
// 向客户端连接中写数据
write(<新描述符>, <发送的数据>, <发送的数据长度>);
3.2.1 创建socket
创建socket这一步和客户端没啥区别,不同的是这个socket我们称之为 等待连接socket(或监听socket) 。
3.2.2 绑定端口号
bind()
函数会将端口号写入上一步生成的监听socket中,这样一来,监听socket就完整保存了服务端的
IP
和
端口号
。
3.2.3 listen()的真正作用
listen(<Server描述符>, <最大连接数>);
很多小伙伴一定会对这个
listen()
有疑问,监听socket都已经创建完了,端口也已经绑定完了,为什么还要多调用一个
listen()
呢?
我们刚说过监听socket和客户端创建的socket没什么区别,问题就出在这个没什么区别上。
socket被创建出来的时候都默认是一个
主动socket
,也就说,内核会认为这个socket之后某个时候会调用
connect()
主动向别的设备发起连接。这个默认对客户端socket来说很合理,但是监听socket可不行,它只能等着客户端连接自己,因此我们需要调用
listen()
将监听socket从主动设置为被动,明确告诉内核:你要接受指向这个监听socket的连接请求!
此外,
listen()
的第2个参数也大有来头!监听socket真正接受的应该是已经完整完成3次握手的客户端,那么还没完成的怎么办?总得找个地方放着吧。于是内核为每一个监听socket都维护了两个队列:
半连接队列(未完成连接的队列)
这里存放着暂未彻底完成3次握手的socket(为了防止半连接攻击,这里存放的其实是占用内存极小的request _sock,但是我们直接理解成socket就行了),这些socket的状态称为
SYN_RCVD
。
已完成连接队列
每个已完成TCP3次握手的客户端连接对应的socket就放在这里,这些socket的状态为
ESTABLISHED
。
文字太多了,有点干,上个图!
解释一下动图中的内容:
客户端调用
connect()函数,开始3次握手,首先发送一个SYN X的报文(X是个数字,下同);服务端收到来自客户端的
SYN,然后在监听socket对应的半连接队列中创建一个新的socket,然后对客户端发回响应SYN Y,捎带手对客户端的报文给个ACK;直到客户端完成第3次握手,刚才新创建的socket就会被转移到已连接队列;
当进程调用
accept()时,会将已连接队列头部的socket返回;如果已连接队列为空,那么进程将被睡眠,直到已连接队列中有新的socket,进程才会被唤醒,将这个socket返回 。
第4步就是阻塞的本质啊,朋友们!
3.3 答疑时间
Q1.队列中的对象是socket吗?
呃。。。乖,咱就把它当成socket就好了,这样容易理解,其实具体里边存放的数据结构是啥,我也很想知道,等我写完这篇文章,我研究完了告诉你。
Q2.accept()这个函数你还没讲是啥意思呢?
accept()
函数是由服务端调用的,用于从已连接队列中返回一个socket描述符;如果socket为阻塞式的,那么如果已连接队列为空,
accept()
进程就会被睡眠。BIO恰好就是这个样子。
Q3.accept()为什么不直接把监听socket返回呢?
因为在队列中的socket经过3次握手过程的控制信息交换,socket的4元组的信息已经完整了,用做socket完全没问题。
监听socket就像一个客服,我们给客服打电话,然后客服找到解决问题的人,帮助我们和解决问题的人建立联系,如果直接把监听socket返回,而不使用连接socket,就没有socket继续等待连接了。
哦对了,
accept()
返回的socket也有个名字,叫
连接socket
。
3.4 BIO究竟阻塞在哪里
拿Server端的BIO来说明这个问题,阻塞在了
serverSocket.accept()
以及
bufferedReader.readLine()
这两个地方。有什么办法可以证明阻塞吗?
简单的很!你在
serverSocket.accept();
的下一行打个断点,然后debug模式运行
BIOServerSocket
,在没有客户端连接的情况下,这个断点绝不会触发!同样,在
bufferedReader.readLine();
下一行打个断点,在已连接的客户端发送数据之前,这个断点绝不会触发!
readLine()
的阻塞还带来一个非常严重的问题,如果已经连接的客户端一直不发送消息,
readLine()
进程就会一直阻塞(处于睡眠状态),结果就是代码不会再次运行到
accept()
,这个
ServerSocket
没办法接受新的客户端连接。
解决这个问题的核心就是别让代码卡在
readLine()
就可以了,我们可以使用新的线程来
readLine()
,这样代码就不会阻塞在
readLine()
上了。
3.5 改造BIO
改造之后的BIO长这样,这下子服务端就可以随时接受客户端的连接了,至于啥时候能read到客户端的数据,那就让线程去处理这个事情吧。
public classBIOServerSocketWithThread{
publicstaticvoidmain(String[] args){
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8099);
System.out.println("启动服务:监听端口:8099");
// 等待客户端的连接过来,如果没有连接过来,就会阻塞
while (true) {
// 表示阻塞等待监听一个客户端连接,返回的socket表示连接的客户端信息
Socket socket = serverSocket.accept(); //连接阻塞
System.out.println("客户端:" + socket.getPort());
// 表示获取客户端的请求报文
new Thread(new Runnable() {
@Override
publicvoidrun(){
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(socket.getInputStream())
);
String clientStr = bufferedReader.readLine();
System.out.println("收到客户端发送的消息:" + clientStr);
BufferedWriter bufferedWriter = new BufferedWriter(
new OutputStreamWriter(socket.getOutputStream())
);
bufferedWriter.write("ok\n");
bufferedWriter.flush();
} catch (Exception e) {
//...
}
}
}).start();
}
} catch (IOException e) {
// 错误处理
} finally {
// 其他处理
}
}
}
事情的顺利进展不禁让我们飘飘然,我们居然是使用高阶的多线程技术解决了BIO的阻塞问题,虽然目前每个客户端都需要一个单独的线程来处理,但
accept()
总归不会被
readLine()
卡死了。
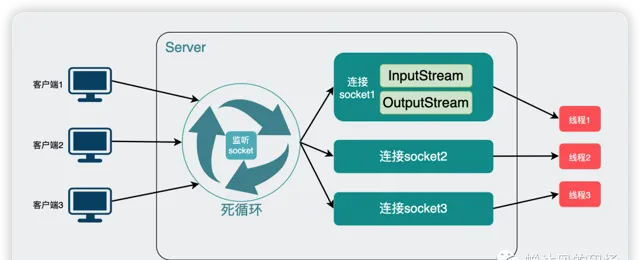
所以我们改造完之后的程序是不是就是非阻塞IO了呢?
想多了。。。我们只是用了点奇技淫巧罢了,改造完的代码在系统调用层面该阻塞的地方还是阻塞,说白了, Java提供的API完全受限于操作系统提供的系统调用,在Java语言级别没能力改变底层BIO的事实!

3.6 掀开BIO的遮羞布
接下来带大家看一下改造之后的BIO代码在底层都调用了哪一些系统调用,让我们在底层上对上文的内容加深一下理解。
给大家打个气,接下来的内容其实非常好理解,大家跟着文章一步步地走,一定能看得懂,如果自己动手操作一遍,那就更好了。
对了,我下来使用的JDK版本是JDK8。
strace
是Linux上的一个程序,该程序可以追踪并记录参数后边运行的进程对内核进行了哪些系统调用。
strace -ff -o out java BIOServerSocketWithThread
其中:
-o
:
将系统调用的追踪信息输出到
out
文件中,不加这个参数,默认会输出到标准错误
stderr
。
-ff
如果指定了
-o
选项,
strace
会追踪和程序相关的每一个进程的系统调用,并将信息输出到以进程id为后缀的out文件中。举个例子,比如
BIOServerSocketWithThread
程序运行过程中有一个ID为30792的进程,那么该进程的系统调用日志会输出到out.30792这个文件中。
我们运行
strace
命令之后,生成了很多个out文件。
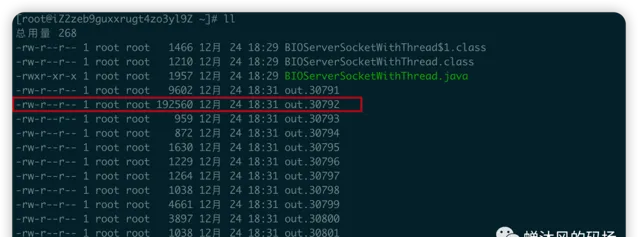
这么多进程怎么知道哪个是我们需要追踪的呢?我就挑了一个容量最大的文件进行查看,也就是out.30792,事实上,这个文件也恰好是我们需要的,截取一下里边的内容给大家看一下。
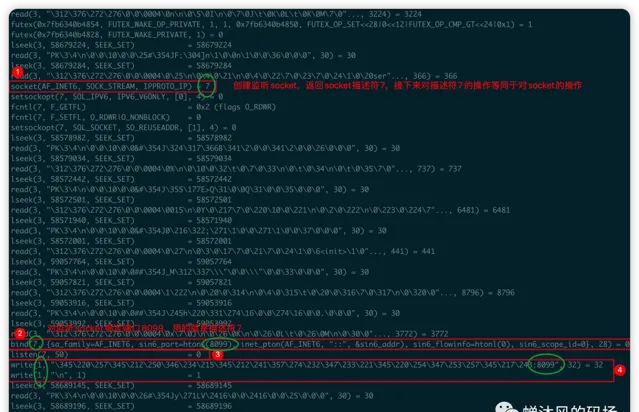
可以看到图中的有非常多的行,说明我们写的这么几行代码其实默默调用了非常多的系统调用,抛开细枝末节,看一下上图中我重点标注的系统调用,是不是就是上文中我解释过的函数?我再详细解释一下每一步,大家联系上文,会对BIO的底层理解的更加通透。
生成监听socket,并返回socket描述符
7,接下来对socket进行操作的函数都会有一个参数为7;将
8099端口绑定到监听socket,bind的第一个参数就是7,说明就是对监听socket进行的操作;listen()将监听socket(参数为7)设置为被动接受连接的socket,并且将队列的长度设置为50;实际上就是
System.out.println("启动服务:监听端口:8099");这一句的系统调用,只不过中文被编码了,所以我特意把:8099圈出来证明一下;
额外说两点:
其一:可以看到,这么一句简单的打印输出在底层实际调用了两次
write
系统调用,这就是为什么不推荐在生产环境下使用打印语句的原因,多少会影响系统性能;
其二:
write()
的第一个参数为
1
,也是文件描述符,表示的是标准输出
stdout
,关于标准输入、标准输出、标准错误和文件描述符之间的关系可以参见
。
系统调用阻塞在了
poll()函数,怎么看出来的阻塞?out文件的每一行运行完毕都会有一个= 返回值,而poll()目前没有返回值,因此阻塞了。实际上poll()系统调用对应的Java语句就是serverSocket.accept();。
不对啊?为什么底层调用的不是
accept()
而是
poll()
?
poll()
应该是多路复用才是啊。在JDK4之前,底层确实直接调用的是
accept()
,但是之后的JDK对这一步进行了优化,除了调用
accept()
,还加上了
poll()
。
poll()
的细节我们下文再说,这里可以起码证明了
poll()
函数依然是阻塞的,所以整个BIO的阻塞逻辑没有改变。
接下来我们起一个客户端对程序发起连接,直接用Linux上的
nc
程序即可,比较简单:
nc localhost 8099
发起连接之后(但并未主动发送信息),out.30792的内容发生了变化:
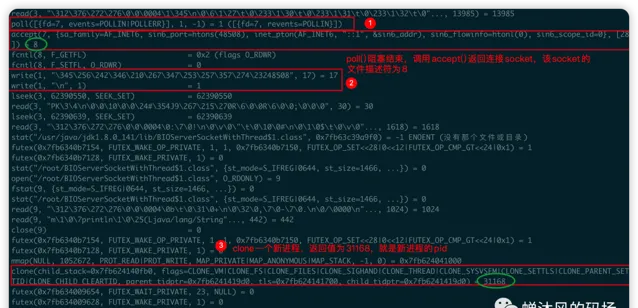
poll()函数结束阻塞,程序接着调用accept()函数返回一个连接socket,该socket的描述符为8;就是
System.out.println("客户端:" + socket.getPort());的底层调用;底层使用
clone()创造了一个新进程去处理连接socket,该进程的pid为31168,因此JDK8的线程在底层其实就是轻量级进程;回到
poll()函数继续阻塞等待新客户端连接。
由于创建了一个新的进程,因此在目录下对多出一个out.31168的文件,我们看一下该文件的内容:
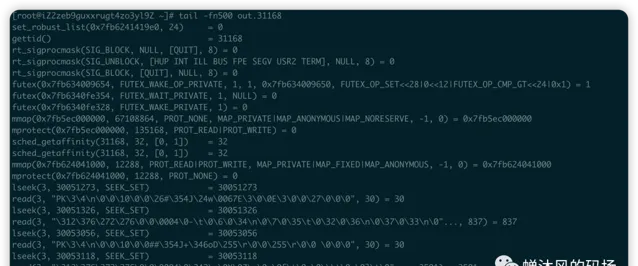
发现子进程阻塞在了
recvfrom()
这个系统调用上,对应的Java源码就是
bufferedReader.readLine();
,直到客户端主动给服务端发送消息,阻塞才会结束。
3.7 BIO总结
到此为止,我们就通过底层的系统调用证明了BIO在
accept()
以及
readLine()
上的阻塞。最后用一张图来结束BIO之旅。
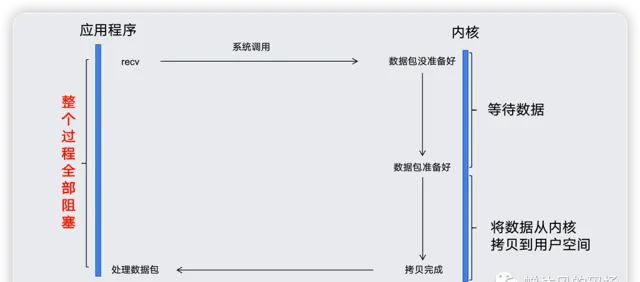
BIO之所以是BIO,是因为系统底层调用是阻塞的,上图中的进程调用
recv
,其系统调用直到数据包准备好并且被复制到应用程序的缓冲区或者发生错误为止才会返回,在此整个期间,进程是被阻塞的,啥也干不了。
4. 非阻塞I/O(NonBlocking I/O)
上文花了太多的笔墨描述BIO,接下来的非阻塞IO我们只抓主要矛盾,其余参考BIO即可。
如果你看过其他介绍非阻塞IO的文章,下面这个图片你多少会有点眼熟。
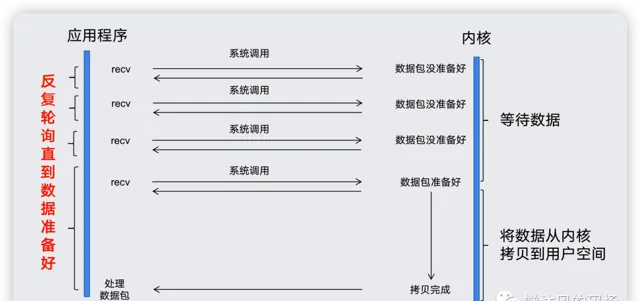
非阻塞IO指的是进程发起系统调用之后,内核不会将进程投入睡眠,而是会立即返回一个结果,这个结果可能恰好是我们需要的数据,又或者是某些错误。
你可能会想,这种非阻塞带来的轮询有什么用呢?大多数都是空轮询,白白浪费CPU而已,还不如让进程休眠来的合适。
4.1 Java的非阻塞实现
这个问题暂且搁置一下,我们先看Java在 语法层面 是如何提供非阻塞功能的,细节慢慢聊。
public classNoBlockingServer{
publicstatic List<SocketChannel> channelList = new ArrayList<>();
publicstaticvoidmain(String[] args)throws InterruptedException {
try {
// 相当于serverSocket
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 将监听socket设置为非阻塞
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(8099));
while (true) {
// 这里将不再阻塞
SocketChannel socketChannel = serverSocketChannel.accept();
if (socketChannel != null) {
// 将连接socket设置为非阻塞
socketChannel.configureBlocking(false);
channelList.add(socketChannel);
} else {
System.out.println("没有客户端连接!!!");
}
for (SocketChannel client : channelList) {
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// read也不阻塞
int num = client.read(byteBuffer);
if (num > 0) {
System.out.println("收到客户端【" + client.socket().getPort() + "】数据:" + new String(byteBuffer.array()));
} else {
System.out.println("等待客户端【" + client.socket().getPort() + "】写数据");
}
}
// 加个睡眠是为了避免strace产生大量日志,否则不好追踪
Thread.sleep(1000);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Java提供了新的API,
ServerSocketChannel
以及
SocketChannel
,相当于BIO中的
ServerSocket
和
Socket
。此外,通过下面两行的配置,将监听socket和连接socket设置为非阻塞。
// 将监听socket设置为非阻塞
serverSocketChannel.configureBlocking(false);
// 将连接socket设置为非阻塞
socketChannel.configureBlocking(false);
我们上文强调过, Java自身并没有将socket设置为非阻塞的本事,一定是在某个时间点上,操作系统内核提供了这个功能,才使得Java设计出了新的API来提供非阻塞功能 。
之所以需要上面两行代码的显式设置,也恰好说明了内核是默认将socket设置为阻塞状态的,需要非阻塞,就得额外调用其他系统调用。我们通过
man
命令查看一下
socket()
这个方法(截图的中间省略了一部分内容):
man 2 socket
我们可以看到
socket()
函数提供了
SOCK_NONBLOCK
这个类型,可以通过
fcntl()
这个方法将socket从默认的阻塞修改为非阻塞,不管是对监听socket还是连接socket都是一样的。
4.2 Java的非阻塞解释
现在解释上面提到的问题:这种非阻塞带来的轮询有什么用?观察一下上面的代码就可以发现,我们全程只使用了1个main线程就解决了所有客户端的连接以及所有客户端的读写操作。
serverSocketChannel.accept();
会立即返回调用结果。
返回的结果如果是一个
SocketChannel
对象(系统调用底层就是个socket描述符),说明有客户端连接,这个
SocketChannel
就表示了这个连接;然后利用
socketChannel.configureBlocking(false);
将这个连接socket设置为非阻塞。这个设置非常重要,设置之后对连接socket所有的读写操作都变成了非阻塞,因此接下来的
client.read(byteBuffer);
并不会阻塞while循环,导致新的客户端无法连接。再之后将该连接socket加入到
channelList
队列中。
如果返回的结果为空(底层系统调用返回了错误),就说明现在还没有新的客户端要连接监听socket,因此程序继续向下执行,遍历
channelList
队列中的所有连接socket,对连接socket进行读操作。而读操作也是非阻塞的,会理解返回一个整数,表示读到的字节数,如果
>0
,则继续进行下一步的逻辑处理;否则继续遍历下一个连接socket。
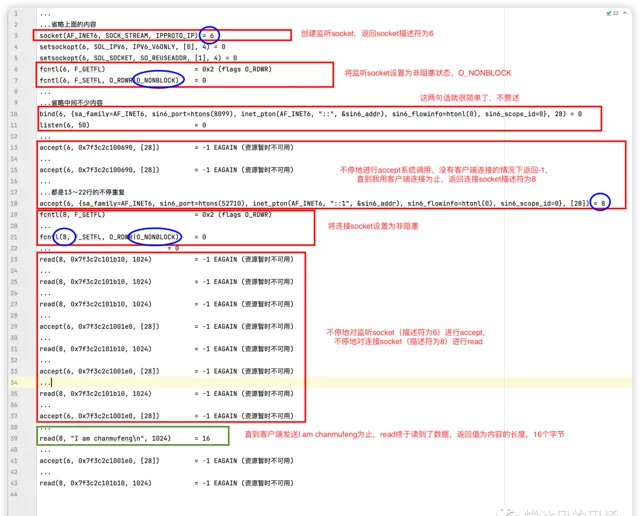
4.3 掀开非阻塞IO的底裤
我将上面的程序在CentOS下再次用
strace
程序追踪一下,具体步骤不再赘述,下面是out日志文件的内容(我忽略了绝大多数没用的)。
4.4 非阻塞IO总结
再放一遍这个图,有一个细节需要大家注意,系统调用向内核要数据时,内核的动作分成两步:
等待数据(从网卡缓冲区拷贝到内核缓冲区)
拷贝数据(数据从内核缓冲区拷贝到用户空间)
只有在第1步时,系统调用是非阻塞的,第2步进程依然需要等待这个拷贝过程,然后才能返回,这一步是阻塞的。
非阻塞IO模型仅用一个线程就能处理所有操作,对比BIO的一个客户端需要一个线程而言进步还是巨大的。但是他的致命问题在于会不停地进行系统调用,不停的进行
accept()
,不停地对连接socket进行
read()
操作,即使大部分时间都是白忙活。要知道,系统调用涉及到用户空间和内核空间的多次转换,会严重影响整体性能。
所以,一个自然而言的想法就是,能不能别让进程瞎轮询。
如此浪潮下,作为程序员的你,还没用过ChatGPT4o吗?还没用过Copilot吗?
国内直接使用ChatGPT4o:
谷歌浏览器直接使用:https://www.nezhasoft.cn
无需魔法,同时支持手机、电脑
个人独享
ChatGPT4o mini永久免费
支持Copilot、DALLE AI绘画、上传文件等
长按识别下方二维码,备注ai,发给你


回复gpt,获取ChatGPT4o直接使用地址
点击阅读原文,国内直接使用ChatGpt4o











