DeepMind再放大招!!
新方法拯救大模型算力问题!省时省力!!🥳
新方法
JEST
将模型训练时间
缩短13倍
!!
节省90%的算力
!!
许多算力不足的问题在此刻迎来了曙光!!🤩

扫码加入AI交流群
获得更多技术支持和交流

技术简介
对模型进行大规模的预训练时,训练数据的质量对模型的性能起到十分重要的作用。
无论在语言、视觉,还是多模态模型中,优质高质量的数据集的使用能够显著减少所需的数据量,大幅提高模型的性能表现。
但对训练数据管道传统上都是进行手动筛选,这是十分昂贵且不灵活的。
联合示例选择技术——JEST 通过联合选择批次训练数据,比单独选择数据更能够加速学习过程,优先数据点大大加快训练速度。
技术原理
为了确定哪些数据最容易学习,JEST使用两个模型:当前正在训练的模型和已经训练的参考模型。
对于那些正在训练的模型来说很难,但对于参考模型来说很容易的数据被认为是高质量的。
并采用对批次数据进行评分的策略,根据这些评分来采样。主要使用三种评分准则:困难学习器、简单参考和可学习性。
最终可学习性评分结合了前两种评分准则,通过优先选择那些未被学习但易于学习的数据加速大规模学习过程。
技术效果
为了减少评估「超级批次」时增加的计算工作量,团队还引入了一个名为 Flexi-JEST 的变体。
在达到相同的训练后模型性能的情况下,
JEST
比当前最好的方法
SigLIP
最高缩短13倍的迭代次数。
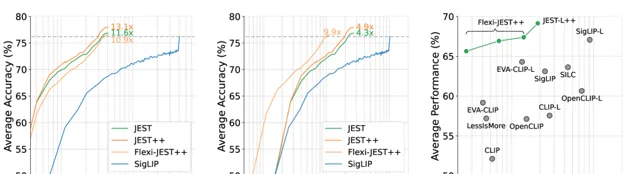
同时第二张图能看出 Flexi-JEST 仅用10% 的训练数据就取得 SigLIP 用100%取得的分数。
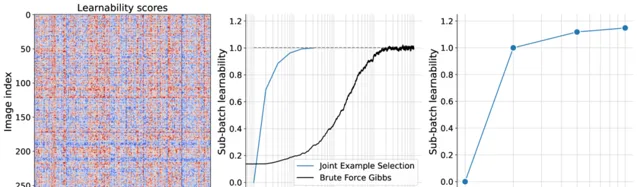
并且JEST能够产生更多可学习的批次,第一张图达到批次的可学习性高度结构化且非对角化。
从二图我们能看出JEST更少的迭代发现与吉布斯抽样相当的具有高可学习性的子批次。
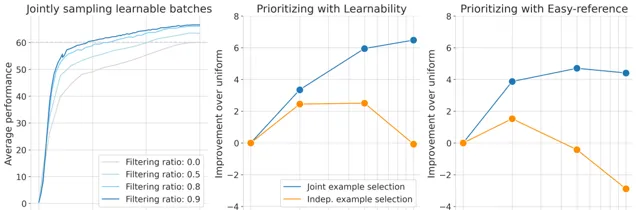
采样批次的可学习性随着过滤率的提高而提高,能够从更大的超批次中进行选择。
JEST从超批次中选择出的最具学习能力的子批次上进行训练显著加速多模态学习。
同时下面清楚地表现出联合优先排序可学习批次比简单地优先排序单个样本能产生更好的结果。
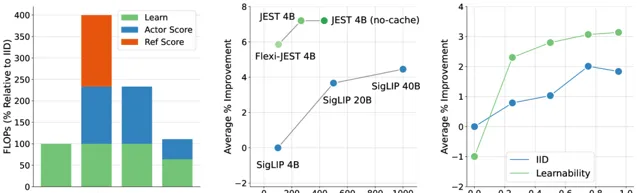
多分辨率训练对于提升JEST的性能十分重要且显著,同时在数据集中缓存固定的参考模型分数,可以将JEST 在大型超批量进行评分时每次迭代产生的大量的计算成本减少一半。
基于现有的技术相比较,JEST能够让模型达到用最少的训练量达到超越其他技术的性能,并在T2I以及I2T的应用上达到最好的效果。
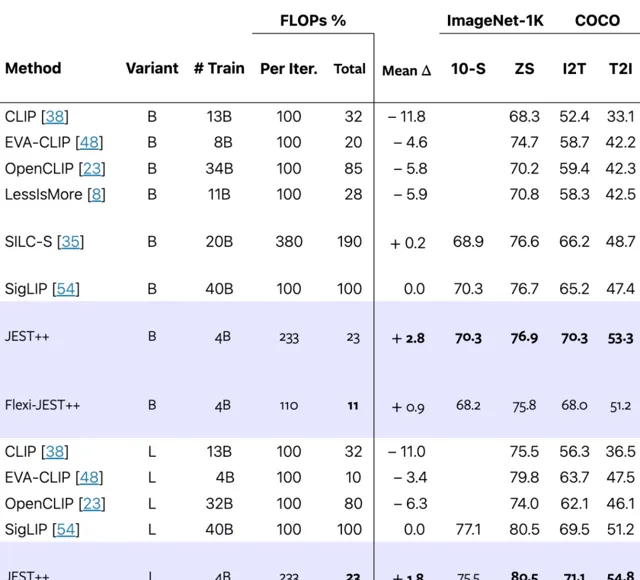
COCO 性能表示图像到文本和文本到图像检索的平均值,JEST ++ 大大超越了现有技术,同时需要的训练迭代次数明显减少。
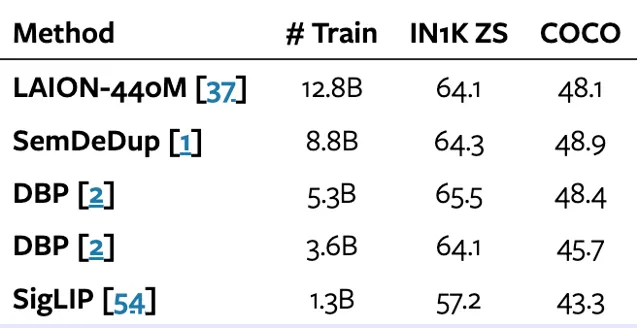
总的来说,JEST 方法在实验中展示了显著的优势。相比于传统的独立样本选择方法,JEST 不仅提升了训练效率,还显著减少了所需的计算量。
JEST 为多模态学习中的数据筛选提供了一种新的高效方法,小编觉得在未来的各种新技术里会看到它的身影!
🔗 项目链接 :
https://arxiv.org/abs/2406.17711
关注「 向量光年 」公众号
加速全行业向AI的改变
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新咨询











