引言
AI经过长时间的发展,已经能够生成从一维到四维的内容了。
从一维的生成文字,到二维生成图片和视频再到生成三维模型,再到在三维模型的基础之上加上动作生成四维模型。
而从一维到三维的生成人工智能方面已经有了较为不错的研究成果,一维的ChatGPT、二维的Sora、三维的Google的CAT3等,唯独四维还没有较好的模型出现。
直到最近 由多伦多大学,北京交通大学,德克萨斯大学奥斯汀分校和剑桥大学团队最新提出的4D生成扩散模型 Diffusion出现 。
详细介绍
那有人可能就问了,不就是个4D合成吗,又不是第一个,有什么牛的?
那你可就不知道了吧!
在 Diffusion4D模型 发布之前,早期的4D合成工作借鉴了预训练的图像或视频扩散模型中的外观和运动经验,并利用 得分蒸馏采样(SDS) 进行优化。
这种策略由于需要大量的监督反向传播,使得计算效率低下,耗时长,限制了其广泛的应用性。
并且在生成4D模型时会产生优化速度慢和多视图不一致问题。简而言之就是形成4D模型的速度慢且生成的模型不一定好。
而我们今天要介绍的这个Diffision4D模型,是首个利用 大规模数据集 , 训练视频生成模型生成4D内容 的框架。这可真谓是大姑娘上轿——头一回!
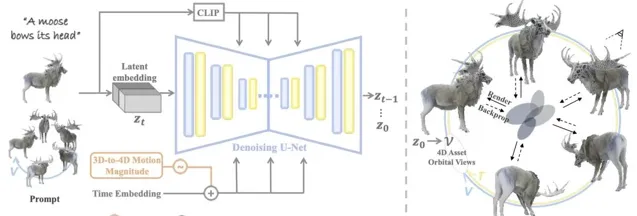
通过该种训练模式, Diffusion4D 在 生成效率 和各种提示模式的4D 几何一致性 方面超越了现有技术。
不管是文字内容,图片内容还是视频内容,它都能很好地将其转化成4D形式。
文字转4D
图像转4D
视频转4D
应用前景
看到这有人可能会接着疑惑了,它再厉害和我们有什么关系呢。
害。这你可能就又有所不知了,它跟我们日常生活的关系可大着呢!
让我们想象一下,在我们参观博物馆时,出现在我们眼前的不只是放在展台里的展品,还有漂浮在空中的全方位的展品,并能感受到展品随着时间的变迁产生的变化。
当医学生在上课时,白板上出现的不再只是一张张图片,而是一个个4D的正在蠕动着的器官,这样的课堂岂不是很生动自然,学生们学习的热情也会更加高涨。
诸如此类的应用还有很多等着我们去开发,为我们的生活带来更多的便捷。
项目链接:
https://vita-group.github.io/Diffusion4D/
扫码加入AI交流群
获得更多技术支持和交流

关注「 向量光年 」公众号
加速全行业向AI的改变
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯











