1. 目标
掌握Postgresql数据库主从部署搭建配置
2. 脉络
部署规划
PostgreSQL单节点安装
PostgreSQL主从部署配置
主从同步验证
3. 知行
3.1 简介
PostgreSQL是一个比较高性能的数据库, 结合PostGIS插件, 使PostgreSQL成为了一个空间数据库,能够进行空间数据管理、数量测量与几何拓扑分析。PostgreSQL从9.3开始支持JSON数据类型, 9.4开始支持JSONB, 具备NoSQL数据库功能, 在性能上甚至超过MongoDB。
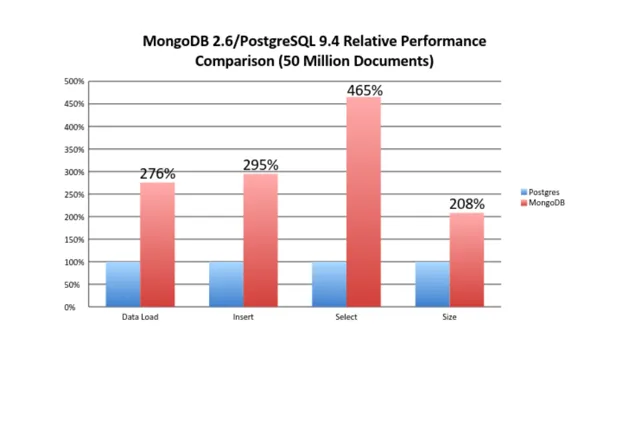
3.2 部署规划
主节点: 10.10.20.26
从节点: 10.10.20.27
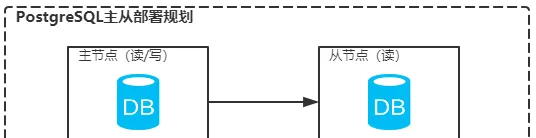
3.3 单节点安装
在主从部署安装之前, 先要在两台节点上分别都安装Postgresql, 这里以安装Postgresql10版本为例。
1、安装yum源
yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm
查看安装包
[root@localhost local]# yum list | grep postgresql10Repository mariadb is listed more than once in the configurationpostgresql10.x86_64 10.10-1PGDG.rhel7 @pgdg10 postgresql10-contrib.x86_64 10.10-1PGDG.rhel7 @pgdg10 postgresql10-devel.x86_64 10.10-1PGDG.rhel7 @pgdg10 postgresql10-libs.x86_64 10.10-1PGDG.rhel7 @pgdg10 postgresql10-server.x86_64 10.10-1PGDG.rhel7 @pgdg10 postgresql10-debuginfo.x86_64 10.10-1PGDG.rhel7 pgdg10 postgresql10-docs.x86_64 10.10-1PGDG.rhel7 pgdg10 postgresql10-odbc.x86_64 11.01.0000-1PGDG.rhel7 pgdg10 postgresql10-plperl.x86_64 10.10-1PGDG.rhel7 pgdg10 postgresql10-plpython.x86_64 10.10-1PGDG.rhel7 pgdg10 postgresql10-pltcl.x86_64 10.10-1PGDG.rhel7 pgdg10 postgresql10-tcl.x86_64 2.4.0-1.rhel7 pgdg10 postgresql10-tcl-debuginfo.x86_64 2.3.1-1.rhel7 pgdg10 postgresql10-test.x86_64 10.10-1PGDG.rhel7 pgdg10
2、执行安装
需要安装postgresql10-contrib.x86_64 、postgresql10-devel.x86_64 和postgresql10-server.x86_64。
yum -y install postgresql10-client postgresql10-server postgresql10-contrib postgresql10-devel
注意, 与单机节点安装不同, 要加上contrib与devel组件。
3、初始化数据库信息
/usr/pgsql-10/bin/postgresql-10-setup initdb
默认生成的数据库信息存放路径是在/var/lib/pgsql/版本号/data下面。
4、启动数据库
systemctl enable postgresql-10.service
设置为开机启动
systemctl start postgresql-10
5、设置用户信息
设置管理用户postgres
su - postgrespsql
进入postgresql控制台
[root@localhost local]-bash-4.2$ psqlpsql (10.10)Type "help" for help.postgres=
修改用户密码:
postgres=# alter user postgres with password '654321';ALTER ROLE
其他命令:
退出: \q列出所有库 \l列出所有用户 \du列出库下所有表 \d
6、设置远程连接权限
默认是不能通过客户端远程连入, 需要做些配置:
修改绑定地址
vi /var/lib/pgsql/10/data/postgresql.conf
绑定所有IP, 以「*」星号替代:
listen_addresses = '*'
修改访问权限
vi /var/lib/pgsql/10/data/pg_hba.conf
注释最后三行, 并增加一行设置, 允许所有远程主机连接:
#local replication all peer#host replication all 127.0.0.1/32 ident#host replication all ::1/128 identhost all all 0.0.0.0/0 md5
7、登陆验证
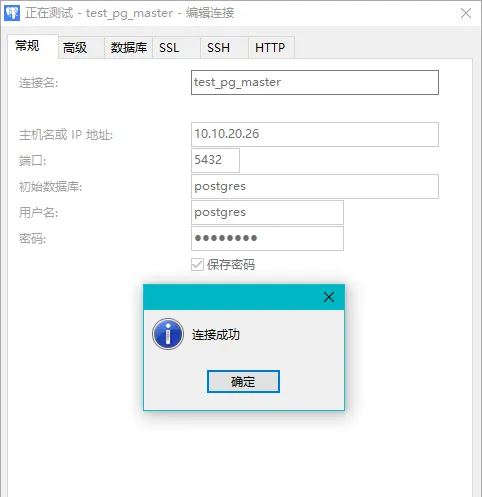
填写IP与用户连接信息,点击「连接测试」出现连接成功提示。
3.4 主从部署配置
3.4.1 简介
PostgreSQL在9.X版本之后提供了基于Standby的异步流复制, 所谓流复制,就是从服务器通过tcp流从主服务器中同步相应的数据。与基于文件日志传送相比,流复制允许保持从服务器更新。从服务器连接主服务器,其产生的流WAL记录到从服务器, 而不需要等待主服务器写完WAL文件。
PostgreSQL在数据目录下的pg_xlog子目录中维护了一个WAL日志文件,该文件用于记录数据库文件的每次改变,这种日志文件机制提供了一种数据库热备份的方案,即:在把数据库使用文件系统的方式备份出来的同时也把相应的WAL日志进行备份,即使备份出来的数据块不一致,也可以重放WAL日志把备份的内容推到一致状态。这也就是基于时间点的备份(Point-in-Time Recovery),简称PITR。而把WAL日志传送到另一台服务器有两种方式,分别是:
WAL日志归档(base-file)
写完一个WAL日志后,才把WAL日志文件拷贝到standby数据库中,简言之就是通过cp命令实现远程备份,这样通常备库会落后主库一个WAL日志文件。
流复制(streaming replication)
流复制是postgresql9.x之后才提供的新的传递WAL日志的方法,它的好处是只要master库一产生日志,就会马上传递到standby库,同第一种相比有更低的同步延迟,从实时性角度优先采用流复制方案。
接下来采用hot_standby 流复制方式来实现主从同步。
3.4.2 主库配置
1、创建主从同步用户
进入终端:
su - postgrespsql
创建用于主从同步的用户, 用户名replica, 密码replica:
CREATE ROLE replica login replication encrypted password 'replica';
2、修改连接权限
vi /var/lib/pgsql/10/data/pg_hba.conf
增加一行配置, 允许10.10.20.27从节点连入:
#local replication all peer#host replication all 127.0.0.1/32 ident#host replication all ::1/128 identhost all all 0.0.0.0/0 md5host replication replica 10.10.20.27/32 md5
修改数据库配置:
vi /var/lib/pgsql/10/data/postgresql.conf
修改以下内容:
# 绑定监听所有IPlisten_addresses = '*' # 允许归档archive_mode = on # 通过命令指定归档路径/archive_command = 'cp %p /opt/pgsql/pg_archive/%f' # 写入WAL的级别(minimal:不能通过基础备份和wal日志恢复数据库; replica: 支持wal归档和复制; logical: 在replica级别添加了逻辑解码所需的信息)wal_level = logical # 允许最多的流复制连接发送数量, 根据从节点数量来设定max_wal_senders = 32 # 设置流复制保留的最多的xlog数目wal_keep_segments = 256 # 设置流复制发送数据的超时时间wal_sender_timeout = 60s # 最大连接数量,根据从节点与客户端连接数来设定max_connections = 1000
3、重启生效
systemctl restart postgresql-10
若生产环境不能随意重启, 也可采用重新加载命令:
systemctl reload postgresql-10
3.4.3 从库配置
1、清空从节点数据
su - postgrescd /var/lib/pgsql/10/datarm -rf *
2、将主库的基础数据复制到从库
pg_basebackup -D $PGDATA -Fp -Xstream -R -c fast -v -P -h 10.10.20.26 -U replica -W
接下来会要求输入上面创建的replica用户密码:
Password: pg_basebackup: initiating base backup, waiting for checkpoint to completepg_basebackup: checkpoint completedpg_basebackup: write-ahead log start point: 0/6000028 on timeline 1pg_basebackup: starting background WAL receiverpg_basebackup: created temporary replication slot "pg_basebackup_27275"pg_basebackup: write-ahead log end point: 0/60000F8pg_basebackup: waiting for background process to finish streaming ...pg_basebackup: base backup completed
3、修改从库配置
vi /var/lib/pgsql/10/data/postgresql.conf
修改配置内容:
# 写入WAL的级别(minimal:不能通过基础备份和wal日志恢复数据库; replica: 支持wal归档和复制; logical: 在replica级别添加了逻辑解码所需的信息)wal_level = logical# 根据实际应用情况, 设定最大连接数max_connections = 1000 # 从机不仅用于数据归档,也可用于数据查询hot_standby = on # 数据流备份的最大延迟时间max_standby_streaming_delay = 30s# 多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,这里只是设置最长的间隔时间wal_receiver_status_interval = 10s # 如果有错误的数据复制,是否向主进行反馈hot_standby_feedback = on
修改同步恢复配置:
vi /var/lib/pgsql/10/data/recovery.conf
修改配置内容:
standby_mode = 'on'primary_conninfo = 'user=replica password=replica host=10.10.20.26 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres target_session_attrs=any'recovery_target_timeline = 'latest'
4、重启从库服务
systemctl restart postgresql-10
3.5 主从同步验证
1、查看同步状态信息
进入主节点:
su - postgrespsql
执行查询:
postgres=# \xExpanded display is on.postgres=# select * from pg_stat_replication;-[ RECORD 1 ]----+------------------------------pid | 8790usesysid | 16384usename | replicaapplication_name | walreceiverclient_addr | 10.10.20.27client_hostname | client_port | 54460backend_start | 2020-04-26 19:22:38.334961+08backend_xmin | state | streamingsent_lsn | 0/726DC08write_lsn | 0/726DC08flush_lsn | 0/726DC08replay_lsn | 0/726DC08write_lag | flush_lag | replay_lag | sync_priority | 0sync_state | async
可以看到从节点10.10.20.27的同步信息。
2、创建用户
在主节点, 创建一个业务数据库的用户office:
create user office password '654321';
赋予用户角色权限, 根据实际情况选择:
alter user office superuser createrole createdb replication;
3、新建数据库
通过客户端工具, 建立数据库连接:

在主节点, 新建mirson数据库:
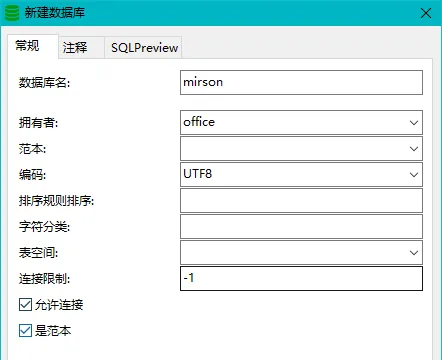
在从节点,刷新一下, 可以看到新创建的数据库:
4、导出原数据库:
选中数据库【mirson】-【office】, 右键【转储SQL文件】-【结构和数据】, 导出数据库。
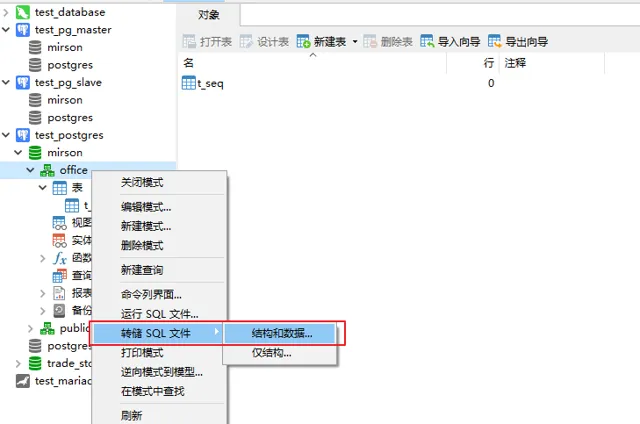
如果工具导出有问题, 可以采用命令行方式导出:
pg_dump -h 127.0.0.1 -p 5432 -U office mirson > /usr/local/mirson.sql
5、导入数据库
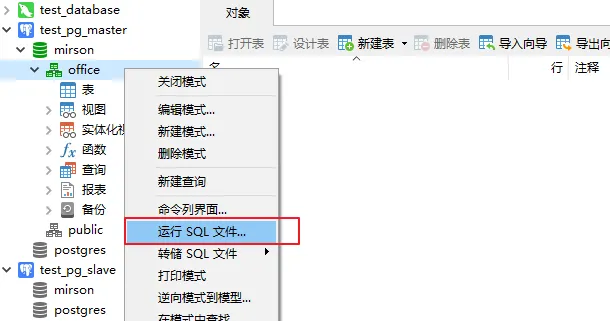
在主节点上,创建模式 【office】:

选择对应模式-【office】, 点击【运行SQL文件】, 选择上面导出的数据库文件。
如果采用的是命令行方式导出, 也要用命令行方式导入:
psql -h 127.0.0.1 -p 5432 -U office mirson < /usr/local/mirson.sql
导入报错:
psql: FATAL: Ident authentication failed for user
要检查配置是否加入:
vi /var/lib/pgsql/10/data/pg_hba.conf
配置检查是否添加trust:
hostallall 127.0.0.1/32 trust
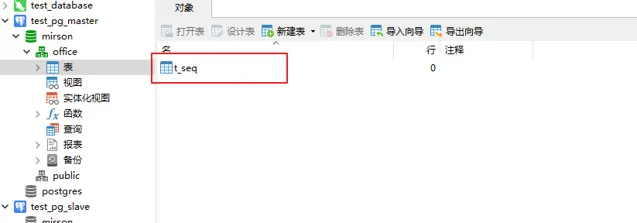
6、查看主从节点数据
10.10.20.26主节点
10.10.20.27从节点
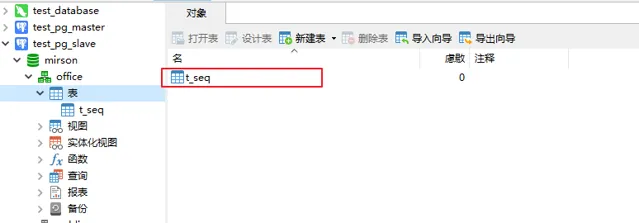
可以看到, 两台节点的数据一致, 主从同步功能正常。
4、合一
通过PostgreSQL主从同步部署, 能够有效保障主节点数据的安全, 即便主库归档日志损坏, 也可以通过从节点恢复获取数据,主从部署还可以有效减少主节点的负载压力, 将集中读取的数据通过从节点处理,减少主节点的IO瓶颈和CPU负载, 如果一台从节点不够, 也可以参照以上部署方式,扩展多个从节点, 从而提升整体数据库吞吐性能。
虽然PostgreSQL原生对多主集群模式没有较好的支持,对于复杂的海量数据的业务, 我们可以从架构设计上做改进, 将复杂的业务进行拆分, 设为多个微服务, 搭建多个PostgreSQL主从服务群, 分散负载, 消除瓶颈,从而有效支撑海量数据的业务服务。
如喜欢本文,请点击右上角,把文章分享到朋友圈
如有想了解学习的技术点,请留言给若飞安排分享
因公众号更改推送规则,请点「在看」并加「星标」 第一时间获取精彩技术分享
·END·
相关阅读:
作者:麦神-mirso
来源:https://blog.csdn.net/hxx688/article/details/105778256
版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
架构师
我们都是架构师!

关注 架构师(JiaGouX),添加「星标」
获取每天技术干货,一起成为牛逼架构师
技术群请 加若飞: 1321113940 进架构师群
投稿、合作、版权等邮箱: [email protected]











