今天给大家介绍的这个项目真的太强了!
很新颖,还没见过一样的开源项目。
跳舞视频加一张人物照片,就让这个人像原视频一样跳舞的开源项目之前给大家推荐过。
一张人物照片,用音频给照片驱动变成讲话视频的项目之前也推荐很多了。
今天给大家推荐的 One Shot, One Talk 就很牛了,功能上有点像是这两类项目的结合体。 上传一段说话人视频,再上传一张人物照片,就可以把视频里的说话人替换掉。
这。。。可用场景是不是太多。。。
不过很刑的事大家可不要去做!!!
One Shot, One Talk现在论文已经发了,代码也马上开源。
这么强的项目,咱们必须得抢先看一下!
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

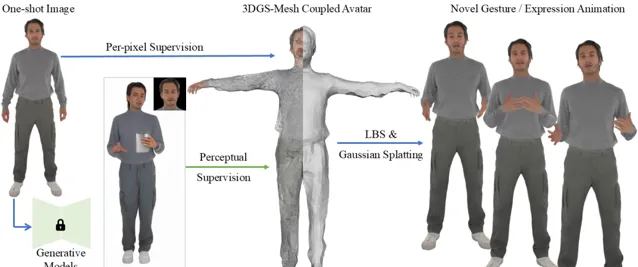
项目简介
One Shot, One Talk 是一个创新的虚拟人物生成项目,通过一张静态图像生成生动的 3D 虚拟人物,并实现其面部与肢体的自然动画。 该项目结合了先进的 3D 高斯点云和 SMPL-X 模型,采用了一种新颖的 3DGS-Mesh 结合表示,能够在保证形态一致性的同时,提供出色的表达能力。 通过结合人类动作扩散模型和面部动画技术,系统可以在仅有一张输入图片的情况下,生成高质量的虚拟人物动画。通过优化伪标签和加入感知指导,项目在面部细节、肢体动态和高保真渲染方面实现了很好的效果。
DEMO
技术特点
1.3DGS-Mesh联合表示
项目采用了3DGS与SMPL-X相结合的创新方式。在该模型中,3DGS通过在网格的基础上初始化并建模细致的面部和肢体特征,使得虚拟人物能够表现出更加细腻的动态变化和面部表情细节。结合网格的几何先验信息和高斯场的表达能力,避免了传统3D网格对复杂细节的表现力不足,同时也不失真实感的渲染效果。
2. 无视频输入的单图生成
与传统的需要视频输入或多张图像的生成方法不同,本项目实现了从单张图片中生成动态虚拟人物。通过结合SMPL-X模型与3D高斯点云,系统能够捕捉到人物的面部和肢体表情,生成具有高保真度的虚拟动画。这使得用户可以通过提供一张图片就能获得一个生动、真实的虚拟人物,具有广泛的应用潜力。
3. 高效的伪标签生成与优化
本项目采用了伪标签生成技术,并通过基于扩散模型的生成网络(如MimicMotion)来生成多样化的动作和表情帧。通过伪标签的引导,结合SMPL-X参数的映射,能够有效处理面部与肢体的动态变化。这种方法可以大大减少对大量训练数据的依赖,使得单图生成技术能够在缺乏多样数据的情况下仍然表现出色。
4. 高保真动画与面部重建
本项目不仅能够生成全身的虚拟人物,还特别优化了面部表情与手部动作的重建。传统的3D网格和高斯点云方法通常难以处理这些细节,但本项目通过引入面部重建优化模块,成功解决了复杂细节区域(如手部、面部等)的精准再现。这种细腻的面部与手部动画生成能力,为虚拟主播、虚拟娱乐等应用提供了非常高的表现力。
5. 虚拟人物与伪标签的感知一致性
在处理输入图像与生成结果的匹配时,采用了LPIPS感知损失来确保生成的虚拟人物在感知层面上与原始输入图像保持高度一致。该损失函数不仅帮助保留了输入图像中的高层次结构特征,还能有效减少传统像素对齐损失带来的模糊和失真问题。通过深度学习感知损失,最终生成的虚拟人物在动态与静态之间实现了平滑过渡,增强了用户体验。
6. 高效的优化策略
在训练过程中,本项目结合了Adam优化器和一系列的正则化方法,包括法线一致性损失、遮罩损失和拉普拉斯平滑损失,有效提高了生成模型的稳定性和鲁棒性。此外,伪标签回追踪(Re-Tracking)技术的引入,有效解决了扩散模型带来的误对齐问题,从而减少了生成过程中的细节丢失和纹理错误,进一步提升了最终输出的质量。
7. 端到端训练与部署
项目采用了端到端训练流程,结合3D网格和高斯点云的联合表示,经过大量数据训练后,能够在没有大量人工标注数据的情况下完成虚拟人物的生成与动画演绎。优化后的模型能够直接应用于多种平台,并实现高效的实时动画生成,满足不同领域如虚拟主播、游戏角色、虚拟演艺等的需求。
项目链接
https://ustc3dv.github.io/OneShotOneTalk/
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯
关注「 向量光年 」公众号
加速全行业向AI转变











