今天的这个项目牛!
现在市面上有很多克隆数字人,也就是用音频驱动图片、视频。
但实际上只是驱动了口型,并不是完全意义上的数字人。至少开源的类似项目没有见到过对动作优化的很好的,如果有的话你也可以在评论区告诉大家。
蚂蚁集团把EchoMimic项目升级了,EchoMimic是一个音频驱动图片的项目。这几天开源了EchoMimicV2,做了一个很大的升级, 现在可以驱动半身的照片了,而且有了肢体动作,还有一点很重要,它对生成的手做了特殊优化! 如果参考图中没有手或者手部变形,就会重新生成一个高质量的手。

扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
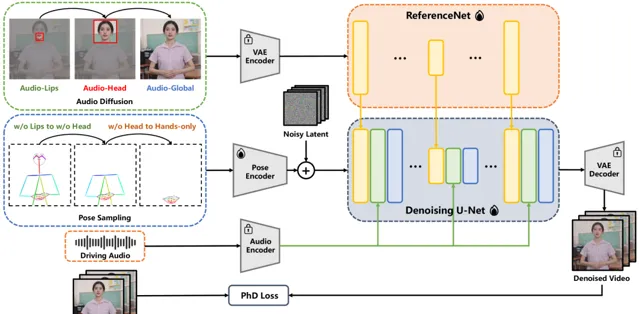
EchoMimicV2是蚂蚁集团开源的音频驱动半身人体动画生成技术,它通过简化的条件来实现高质量的动画效果。该项目利用音频姿态动态协调策略(APDH),通过音频和姿态的精细调节,显著降低了姿态条件的冗余,同时增强了动画的表现力和细节质量。EchoMimicV2还引入了头部偏注意力机制来强化半身数据的面部表情,无需额外模块即可提升动画的自然性和表达力。
DEMO
先看下EchoMimicV1版本的效果,只是驱动了口型,类似项目很多。
V2版本实在是太给力了!
对中文也做了特殊的优化。
技术特点
1.音频姿态动态协调(APDH): EchoMimicV2核心的APDH策略,通过动态调整音频和姿态输入,优化了条件复杂性。这一策略包括姿态采样和音频扩散两个主要环节,使得音频不仅控制口部动作,还能扩展到整个半身的动画表现,实现更加和谐的视听一致性。

2. 用于数据增强的 头部偏注意力(HPA)机制: 为了解决半身动画数据稀缺的问题,EchoMimicV2采用了头部偏注意力机制。通过这一机制,可以在不增加额外计算负担的情况下,将面部表情的细节加以强化,提高动画的真实感和表现力。EchoMimicV2能够无缝地利用已有的头像数据增强训练集,增强模型对半身图像中面部表情的学习和再现能力,无需依赖于额外的数据处理模块。
3.阶段特定去噪损失(PhD Loss): 该技术通过定义不同的去噪阶段,为每个阶段定制了特定的损失函数,包括姿态主导损失、细节主导损失和低级别损失。这种分阶段的优化方法,确保了动画在动作表现、细节丰富性和视觉质量上的均衡提升。

项目链接
https://www.dongaigc.com/p/antgroup/echomimic_v2
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯
关注「 向量光年 」公众号
加速全行业向AI转变











