❝
目前大语言模型十分火爆,相信不少开发者都想上手体验一番,但是对于我们这种技术有限的开发者,很难理清模型的推理过程以及输出输出处理,使得我们望尘莫及。那么现在随着OpenVINO™ 2024.2工具包的发布,他带来了最新的大语言模型部署工具OpenVINO.GenAI ,该工具包封装了目前一些常用的大语言模型部署流程,能够让我们对大语言模型刚入门的开发者也能够在自己电脑上跑起来。
本视频中,我们将结合常见的大语言模型Qwen1.5-7B-Chat、Qwen1.5-7B-Chat-GPTQ-Int4,在本地电脑CPU上演示使用OpenVINO.GenAI 的运行效果。
1. 前言
英特尔发行版 OpenVINO™ 工具套件基于 oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO™ 可赋能开发者在现实世界中部署高性能应用程序和算法。
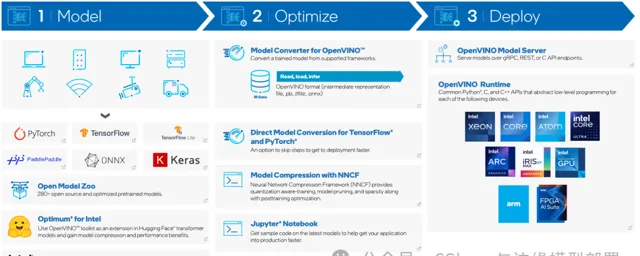
2024年6月17日,英特尔发布了开源 OpenVINO™ 2024.2工具包:更多的 Gen AI 覆盖范围和框架集成,以最大限度地减少代码更改,并针对 CPU、内置 GPU 和独立 GPU 的 Llama 3 优化,可提高性能和提高内存使用效率。同时支持更多大型语言模型 (LLM)模型压缩技术,其中NNCF 中添加了用于 4 位权重压缩的 GPTQ 方法,以提高推理效率并提高压缩 LLM 的性能,同时提高了 LLM 性能,并降低了内置 GPU 和独立 GPU 的延迟。
其中非常引人注目的是,在该版本中推出了 OpenVINO.GenAI 软件包和 LLM特定 API。目前生成式 AI 正在被应用程序设计人员快速地使用着,这不仅体现在使用来自商业云服务模型的传统REST API形式上,而且还发生在客户端和边缘。所以目前最新的版本中引入了新的软件包 openvino-genai,它基于OpenVINO™ 以及openvino_tokenizers,可以轻松实现运行 LLM。
因此,在本文中,我们将使用OpenVINO最新版提供的GenAI接口,演示如何快速构建一个简单的Chat案例,此处我们将结合
TinyLlama-1.1B-Chat-v1.0
和
Qwen1.5-7B-Chat-GPTQ-Int4
这两个大模型演示从模型下载到项目实现的全部流程。
2. 项目开发环境
下面简单介绍一下项目的开发环境,开发者可以根据自己的设备情况进行配置:
系统平台:Windows 11
Intel Core i7-1165G7
开发平台:Visual Studio 2022
OpenVINO™ GenAI:2024.2.0
3. 模型下载与转换
3.1 环境配置
模型下载与转换需要使用的Python环境,因此此处我们采用Anaconda,然后用下面的命令创建并激活名为optimum_intel的虚拟环境:
conda create -n optimum_intel python=3.11 #创建虚拟环境
conda activate optimum_intel #激活虚拟环境
python -m pip install --upgrade pip #升级pip到最新版本
由于Optimum Intel代码迭代速度很快,所以选用从源代码安装的方式,安装Optimum Intel和其依赖项OpenVINO与NNCF。
python -m pip install "optimum-intel[openvino,nncf]"@git+https://github.com/huggingface/optimum-intel.git
3.2 下载模型
目前一些大语言模型发布在Hugging Face上,但由于在国内我们很难访问,因此此处模型下载我们使用国内的魔塔社区进行模型下载:
首先下载
Qwen1.5-7B-Chat-GPTQ-Int4
大模型,输入以下命令即可进行下载:
git clone https://www.modelscope.cn/qwen/Qwen1.5-7B-Chat-GPTQ-Int4.git
接着下载
TinyLlama-1.1B-Chat-v1.0
大模型,输入以下命令即可进行下载:
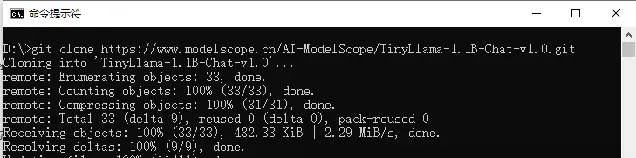
git clone https://www.modelscope.cn/AI-ModelScope/TinyLlama-1.1B-Chat-v1.0.git
输入上面命令后,输出如下面所示,则说明已经完成了模型下载:
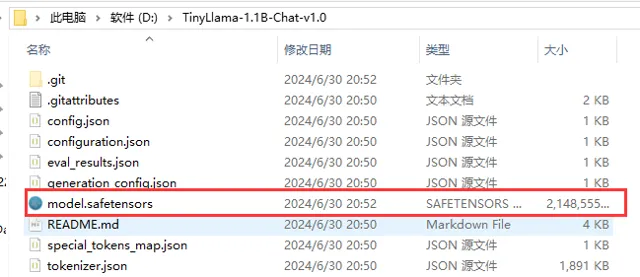
然后我们查看一下下载后的文件夹,如下图所示,文件中已经包含了下载的大模型以及一些配置文件:
3.3 模型转换与量化
最后我们使用Optimum Intel工具,将模型转为OpenVINO™ 的IR格式,同时为了提升模型推理速度,我们还将模型进行INT4量化,此处我们可以使用Optimum Intel工具一条指令便可完成。
首先进行
Qwen1.5-7B-Chat-GPTQ-Int4
模型的转换与量化,在上文创建的环境下输入以下命令即可:
optimum-cli export openvino --trust-remote-code --model D:\Qwen1.5-7B-Chat-GPTQ-Int4 --task text-generation-with-past --weight-format int4 --sym Qwen1.5-7B-Chat-GPTQ-Int4
❝
错误提醒:在转换的时候如果出现
PackageNotFoundError: No package metadata was found for auto-gptq
的错误,请输入以下指令安装缺失的程序包:
pip install auto-gptq
然后进行
TinyLlama-1.1B-Chat-v1.0
模型的转换与量化,在上文创建的环境下输入以下命令即可:
optimum-cli export openvino --model D:\TinyLlama-1.1B-Chat-v1.0 --task text-generation-with-past --weight-format int4 --sym TinyLlama-1.1B-Chat-v1.0
模型转换完成后输出如下所示:

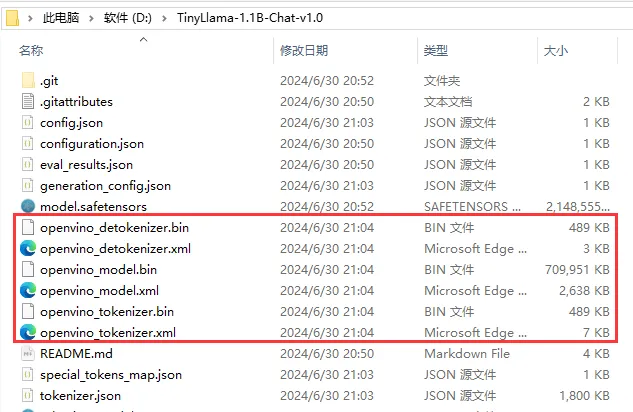
转换完成后,我们查看一下模型路径,可以看到模型路径下多了三个转换好的OpenVINO™ 的IR格式文件,如下图所示:
到此为止我们已经完成了模型的准备与转换环节。
4.OpenVINO™ GenAI 安装与 C++项目配置
OpenVINO™ GenAI C++项目的安装与配置与OpenVINO™基础版本完全一致,如果你之前配置过OpenVINO™,那么此处可以完全忽略。
4.1 OpenVINO™ GenAI 下载与安装
首先访问下面链接,进入下载页面:
https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html
然后再下载页面选择相应的包以及环境,然后点击下载链接进行下载,如下图所示:
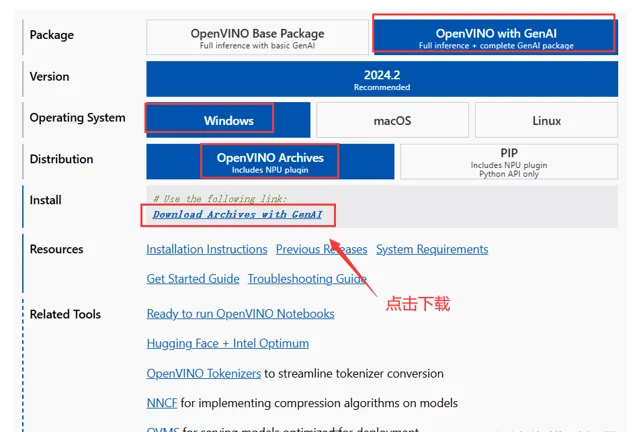
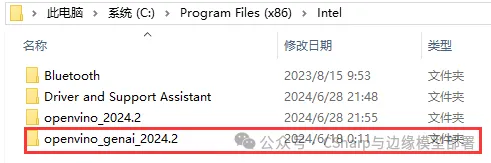
文件下载完成后,将其解压到任意目录,此处建议解压到
C:\Program Files (x86)\Intel
目录下,并将文件夹名修改为较为简洁表述,如下图所示:
最后在环境变量PATH中添加以下路径:
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\bin\intel64\Debug
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\bin\intel64\Release
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\3rdparty\tbb\bin
至此为止,我们便完成了OpenVINO™ GenAI 下载与安装。
4.2 OpenVINO™ GenAI C++项目配置
C++项目主要是需要配置包含目录、库目录以及附加依赖项,分别在C++项目中依次进行配置就可以:
包含目录:
# Debug和Release
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\include
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\include\openvino\genai
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\include\openvino
库目录:
# Debug
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\lib\intel64\Debug
# Release
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\lib\intel64\Release
附加依赖项
# Debug
openvinod.lib
openvino_genaid.lib
# Release
openvino.lib
openvino_genai.lib
5. 模型推理代码
下面是模型推理的代码,由于OpenVINO™ GenAI已经将模型的前后处理流程进行了封装,因此在使用时代码十分简洁,如下所示:
#include"openvino/genai/llm_pipeline.hpp"
#include<iostream>
intmain(int argc, char* argv[])
{
std::string model_path = "D:\\model\\TinyLlama-1.1B-Chat-v1.0";
std::string prompt;
ov::genai::LLMPipeline pipe(model_path, "CPU");
ov::genai::GenerationConfig config;
config.max_new_tokens = 1000;
std::function<bool(std::string)> streamer = [](std::string word) {
std::cout << word << std::flush;
returnfalse;
};
pipe.start_chat();
for (;;) {
std::cout << "question:\n";
std::getline(std::cin, prompt);
if (prompt == "Stop!")
break;
pipe.generate(prompt, config, streamer);
std::cout << "\n----------\n";
}
pipe.finish_chat();
}
6. 效果演示
在运行代码后,我们想起进行提问「Please generate a C # code to implement matrix transpose」,主要是让其生成一段C #代码,实现矩阵的转置,输出如下所示:
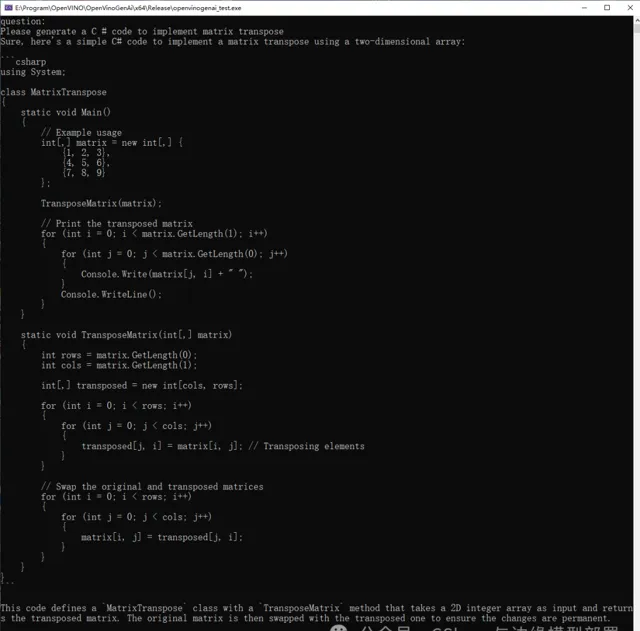
同时我们查看一下运行过程中CPU以及内存情况,下图是CPU以及内存占用情况:
| CPU占用 | 内存占用 |
|---|---|
|
|
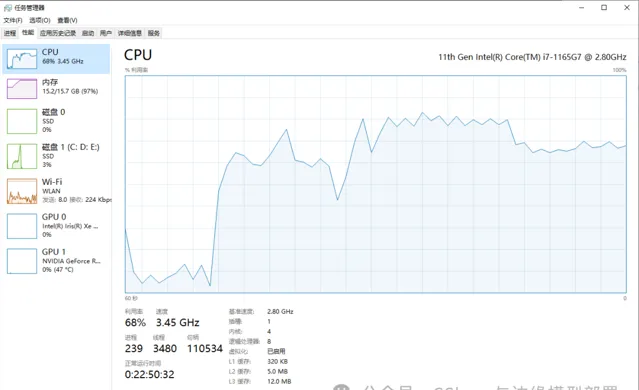
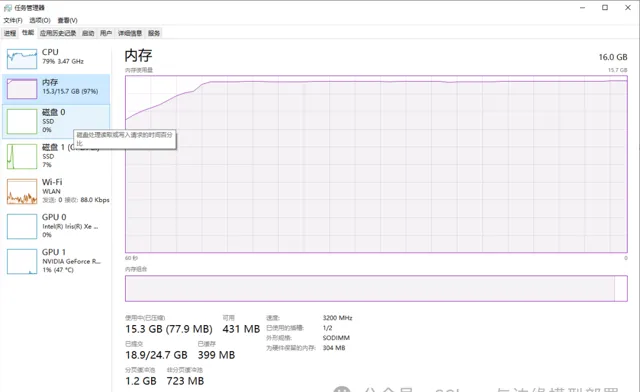
本机电脑使用的是一块16GB的内存,可以看出在OpenVINO的加持下,依然可以很流畅的使用大语言模型进行推理。
7. 总结
在本文中,我们演示了常见的大语言模型Qwen1.5-7B-Chat、Qwen1.5-7B-Chat-GPTQ-Int4,在本地电脑CPU上演示使用OpenVINO.GenAI 的运行效果。最后如果各位开发者在使用中有任何问题,欢迎大家与我联系。

猜你喜欢的文章
▶
▶
▶
▶
▶










