项目简介
MedicalGPT 是一个基于ChatGPT训练流程的医疗行业语言模型项目,主要包括增量预训练、有监督微调和强化学习。项目旨在通过不同的训练阶段,优化模型以更好地适应医疗数据,提高问答和文本生成的准确性和质量。此外,该项目还引入了直接偏好优化(DPO)和无参考模型的优化(ORPO)技术,使得模型在无需复杂的强化学习框架下,能够有效学习并适应人类偏好。项目通过多种数据集和训练策略,实现了模型的持续进化和功能扩展。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)


特点
基于ChatGPT训练流程,本项目实现了一个专注于医疗行业的语言大模型训练:
第一阶段:PT(Continue PreTraining,持续预训练)在海量领域文档数据上进行增量预训练,以使GPT模型适应领域数据分布。
第二阶段:SFT(Supervised Fine-tuning,有监督微调)构建有指令的微调数据集,在已预训练的模型基础上进行指令精调,以匹配指令意图并融入领域知识。
第三阶段包括两部分:
· RM(Reward Model,奖励模型)通过构建人类偏好排序的数据集训练奖励模型,用以模拟人类偏好,主要遵循「有益、诚实、无害」(HHH)的原则。
· RL(Reinforcement Learning,强化学习)利用奖励模型训练SFT模型,使得生成模型通过奖励或惩罚更新其策略,从而生成更高质量、更符合人类偏好的文本。
DPO(Direct Preference Optimization,直接偏好优化)方法通过直接优化语言模型的行为,无需复杂的强化学习流程,有效地学习人类偏好,相较于RLHF,DPO更易实现且训练效果更优。
ORPO(无需参考模型的优化方法)使语言大模型能够同时学习遵循指令和满足人类偏好。
DEMO
开发了一个基于Gradio的简洁交互式Web界面。服务启动后,可以通过浏览器访问,输入问题,随后模型将提供答案。
启动服务的命令如下:
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type base_model_type --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir
参数详情如下:
--model_type {base_model_type}:指定预训练模型的类型,支持的类型包括llama、bloom、chatglm等。
--base_model {base_model}:指定存储LLaMA模型权重和配置文件的目录,也可以使用来自HF Model Hub的模型调用名称。
--lora_model {lora_model}:指定LoRA文件的存储目录,也可以使用HF Model Hub的模型调用名称。如果LoRA权重已经整合到预训练模型中,可省略此参数。
--tokenizer_path {tokenizer_path}:指定tokenizer文件的存储目录。如果未指定此参数,其默认值与--base_model相同。
--template_name:设定模板名称,例如vicuna、alpaca等。如果未指定,其默认值为vicuna。
--only_cpu:设置仅使用CPU进行模型推理。
--resize_emb:设置是否调整embedding的大小。如果不进行调整,则使用预训练模型中的embedding大小,默认为不调整。
安装
要适配最新功能,requirements.txt 文件可能需要不时进行更新。更新依赖时,使用以下命令:
git clone https://github.com/shibing624/MedicalGPTcd MedicalGPTpip install -r requirements.txt --upgrade
此外,对于硬件需求,特别是显存(VRAM),请确保你的设备符合最新功能的需求。更新硬件规格可以帮助确保应用程序运行流畅并充分利用新功能。
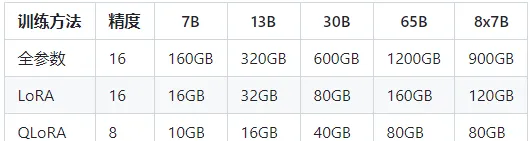
训练

1.提供完整PT+SFT+DPO全阶段串起来训练的pipeline:run_training_dpo_pipeline.ipynb ,其对应的colab:
https://colab.research.google.com/github/shibing624/MedicalGPT/blob/main/run_training_dpo_pipeline.ipynb
运行完大概需要15分钟,运行成功后的副本colab:
https://colab.research.google.com/drive/1kMIe3pTec2snQvLBA00Br8ND1_zwy3Gr?usp=sharing
2.提供完整PT+SFT+RLHF全阶段串起来训练的pipeline:run_training_ppo_pipeline.ipynb ,其对应的colab:
https://colab.research.google.com/github/shibing624/MedicalGPT/blob/main/run_training_ppo_pipeline.ipynb
运行完大概需要20分钟,运行成功后的副本colab:
https://colab.research.google.com/drive/1RGkbev8D85gR33HJYxqNdnEThODvGUsS?usp=sharing
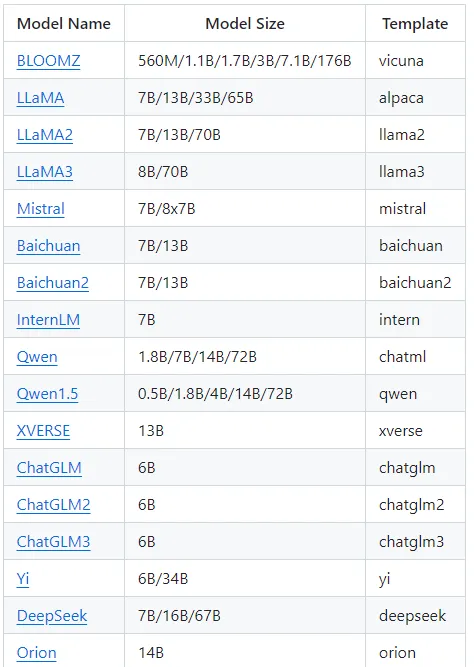
支持的模型
推理
训练完成后,加载训练好的模型,验证模型生成文本的效果
CUDA_VISIBLE_DEVICES=0 python inference.py \ --model_type base_model_type \ --base_model path_to_model_hf_dir \ --tokenizer_path path_to_model_hf_dir \ --lora_model path_to_lora \ --interactive
多卡推理
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 inference_multigpu_demo.py --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chat
项目链接
https://github.com/shibing624/MedicalGPT
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点











