这一天来的猝不及防,一夜之间「王位」易主!!
Transformer架构作为现在AI领域的霸主,地位不保😱😱
最新发布的测试时间训练层
Test-Time Training——TTT
横空出世!
TTT是具有表达性隐藏状态的 RNN层,它能够 代替 Transformer中的自注意力层。
这个一举打败transformer和mamba的新层次架构近日在AI界掀起惊涛骇浪,吸引了所有人的注意。
作者分别来自斯坦福、加州伯克利、加州圣迭戈和 Meta联合研究发表。

扫码加入AI交流群
获得更多技术支持和交流

Transformer的自注意力层在处理长文本上下文时表现突出,但其计算复杂度为二次方,成本十分昂贵。
而Mamba中的循环神经网络RNN层会在时间步上压缩为固定大小,在处理非常长文本时,隐藏状态表达能力十分受限。
由此产生了一个奇妙的想法:能不能让隐藏状态像模型一样学习?🤔
于是TTT将RNN隐藏状态本身变成一个机器学习模型,并将更新规则设定为自监督学习的一个步骤,自监督学习将上下文压缩为模型权重进行参数学习。
这种创新使得隐藏状态在测试序列上的更新相当于在测试时间进行训练,因此被称为 测试时间训练层 。TTT因此具有 线性复杂度和强大的隐藏状态表达能力。
参数学习器需要定义模型和优化器,每个学习器唯一地诱导一个TTT层。团队提出了两个诱导 TTT 层:TTT-Linear 和 TTT-MLP,其中隐藏状态分别是线性模型和两层多层感知机MLP。
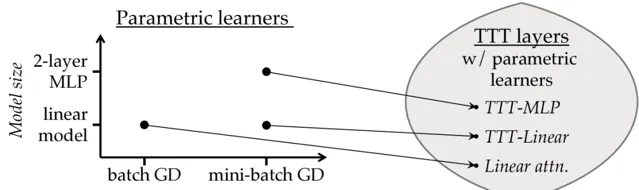
团队在规模从125M到1.3B参数的模型上对TTT-Linear和TTT-MLP进行了评估,并与Transformer和Mamba进行了比较。
与Mamba和Transformer相比,TTT-Linear 具有更好的困惑度和更少的 FLOPs,并且更好地利用了长上下文。
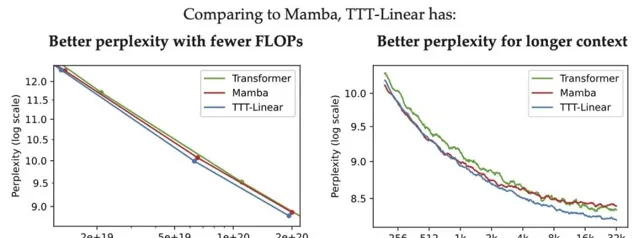
TTT-MLP 与TTT-Linear相比在短上下文中的表现略差,但在长上下文中表现更好,这表现出作为隐藏状态的 MLP 比线性模型更具表现力。
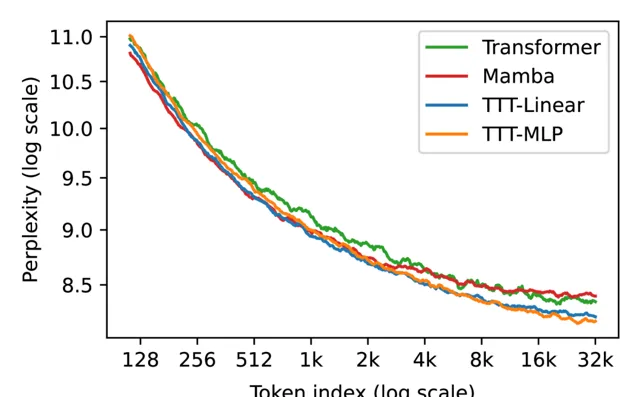
团队在大规模数据集The Pile 上下文长度 2k 和 8k 进行评估,TTT的表现都比较优秀。
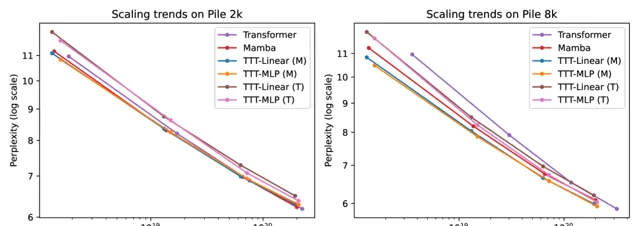
为了评估长上下文中的能力,团队使用从 1k 到 32k 的上下文长度的Pile 的一个流行子集 Books进行评估。
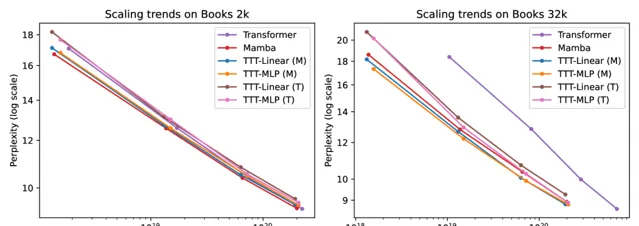
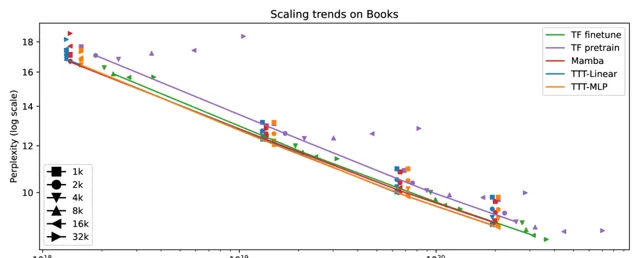
同时团队在上下文长度从1k到32k的Books上进行实验,将上下文长度视为超参数并连接选定的点,得到完整结果,其中包括性能更好的微调后的transformer。
TTT层在硬件效率方面也进行了优化,通过小批量TTT和双重形式,使TTT-Linear在8k上下文长度时已经比Transformer更快,和Mamba持平,并随着上下文的增加差距愈加明显。
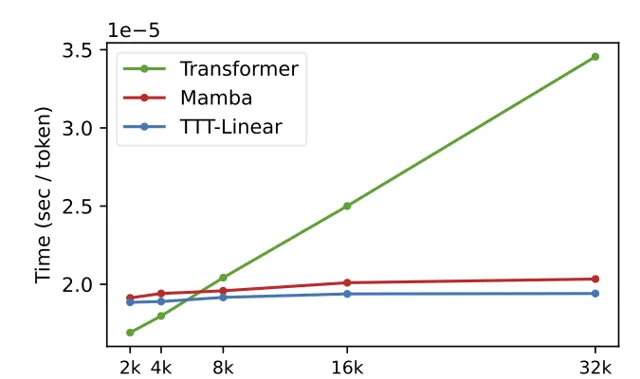
由此大量比较数据可见TTT-Linear和TTT-MLP在多个实验中表现优异,小编相信这会在未来研究中的闪闪发光。
尽管TTT-Linear和TTT-MLP在现有实验中表现出色,但TTT-MLP在内存I/O方面仍面临挑战,且在长文本上下文中显示出更大的潜力。
这为未来的研究指出了一个有前景的方向,即进一步优化TTT层的内存使用和并行计算能力。
🔗 项目链接 :
https://github.com/test-time-training/ttt-lm-jax
关注「 向量光年 」公众号
加速全行业向AI的改变
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新咨询











