项目简介
ID-Animator 是一个无需重新训练就能生成身份特定的人类视频的框架。利用单张面部参考图像,它可以生成高质量的个性化视频。此框架采用基于扩散的视频生成技术,并结合面部适配器来编码与身份相关的嵌入式表示。它还引入了一个面向身份的数据集构建流程,以及一个基于随机面部参考的训练方法,从而在不需要精细调整的情况下,有效提高视频的身份保真度和模型的泛化能力。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)

Demo
·重新语境化
· 使用社区模型进行推理
·身份混合
·与 ControlNet 结合
技术方案
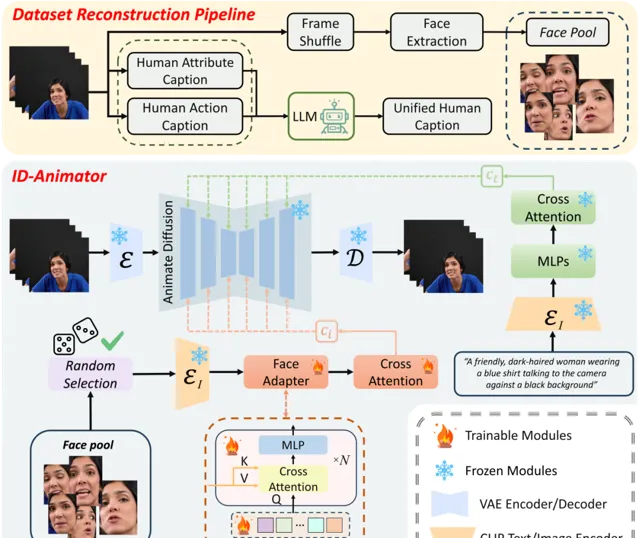
生成高保真人物视频并指定身份在内容生成社区引起了广泛关注。然而,现有技术在训练效率和身份保留之间难以取得平衡,要么需要繁琐的逐例微调,要么在视频生成过程中通常无法保留身份细节。
在本研究中,提出了一种名为ID-Animator的零样本人物视频生成方法,该方法能够使用单个参考面部图像进行个性化视频生成,无需进一步训练。
ID-Animator继承了现有基于扩散的视频生成骨干网络,并增加了一个面部适配器,用以从可学习的面部潜在查询中编码与身份相关的嵌入。
为了在视频生成中便于提取身份信息,我们引入了一个面向身份的数据集构建流程,该流程采用从构建的面部图像池中解耦的人类属性和行为标题技术。
基于此流程,进一步设计了一种随机面部参考训练方法,以精确捕获参考图像中与身份相关的嵌入,从而提高模型在特定身份视频生成中的保真度和泛化能力。
广泛的实验表明,ID-Animator在生成个性化人物视频方面优于之前的模型。此外,此方法与流行的预训练T2V模型如animatediff以及各种社区支持的骨干模型高度兼容,显示出在现实世界应用中的高扩展性,特别是在需要高度身份保留的视频生成场景中。
项目链接
https://github.com/id-animator/id-animator
论文链接
https://arxiv.org/abs/2404.15275
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点











