项目简介
DBRX是Databricks推出的最新一代开源大型语言模型(LLM),在多个标准基准测试中创下新的最高记录,超越了GPT-3.5并与Gemini 1.0 Pro具有竞争力。它特别擅长编程任务,比专门的编程模型CodeLLaMA-70B还要优秀。DBRX采用细粒度混合专家(MoE)架构,使得训练和推理性能大幅提升,推理速度比LLaMA2-70B快2倍,模型大小只有Grok-1的40%。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)

性能
这种最先进的质量伴随着在训练和推理性能上的显著改进。DBRX在开放模型中以其细粒度的混合专家(MoE)架构,推进了效率的最先进水平。与LLaMA2-70B相比,推理速度提高了2倍,而且DBRX的总参数量和活跃参数量约为Grok-1的40%。
当部署在Mosaic AI Model Serving上时,DBRX可以实现每秒最多150个token的文本生成速率。与训练相同最终模型质量的密集模型相比,训练MoEs的FLOP效率也提高了约2倍。从端到端来看,DBRX总体配方(包括预训练数据、模型架构和优化策略)几乎可以用不到4倍的计算量匹配上一代MPT模型的质量。
DBRX是什么
DBRX是一个基于Transformer的仅解码器大型语言模型(LLM),通过下一个token的预测进行训练。它采用了一个细粒度的混合专家(MoE)架构,总共有1320亿个参数,其中360亿个参数在任何输入上都是活跃的。它在12T个文本和代码数据的token上进行了预训练。
与其他开放的MoE模型如Mixtral和Grok-1相比,DBRX是细粒度的,这意味着它使用了更多数量但更小的专家。DBRX拥有16个专家并选择4个,而Mixtral和Grok-1有8个专家并选择2个。这提供了65倍更多可能的专家组合,发现这提高了模型质量。DBRX使用旋转位置编码(RoPE)、门控线性单元(GLU)和分组查询注意力(GQA)。它使用的是tiktoken仓库提供的GPT-4分词器。基于详尽的评估和规模实验做出了这些选择。
DBRX在12T个精心策划的数据上进行了预训练,最大上下文长度为32k个token。估计这些数据的token对token的质量至少比用于预训练MPT系列模型的数据好2倍。这个新数据集是使用Databricks的全套工具开发的,包括Apache Spark™和Databricks笔记本进行数据处理,Unity Catalog进行数据管理和治理,以及MLflow进行实验跟踪。使用了课程学习进行预训练,在训练过程中改变数据混合,发现这在显著提高模型质量方面很有帮助。
对比
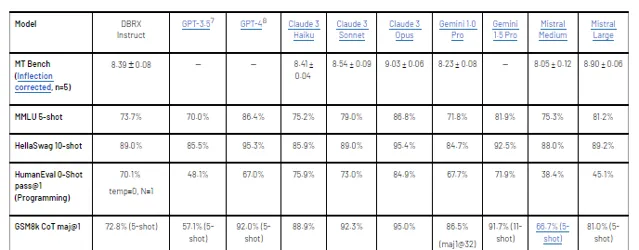
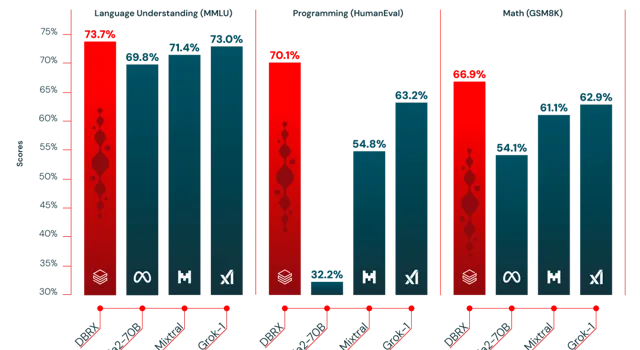
根据每个模型创建者报告的分数,DBRX Instruct超过了GPT-3.5(如GPT-4论文所描述),并且与Gemini 1.0 Pro和Mistral Medium具有竞争力。
在考虑的几乎所有基准测试中,DBRX Instruct要么超过要么至少与GPT-3.5持平。在由MMLU测量的通用知识上,DBRX Instruct的表现超过了GPT-3.5(73.7%对70.0%),在由HellaSwag和WinoGrande测量的常识推理上,也超过了GPT-3.5(分别为89.0%对85.5%和81.8%对81.6%)。特别是在由HumanEval和GSM8k测量的编程和数学推理上,DBRX Instruct表现尤为出色(分别为70.1%对48.1%和72.8%对57.1%)。
DBRX Instruct与Gemini 1.0 Pro和Mistral Medium具有竞争力。在Inflection Corrected MTBench、MMLU、HellaSwag和HumanEval上,DBRX Instruct的分数高于Gemini 1.0 Pro,而Gemini 1.0 Pro在GSM8k上更强。DBRX Instruct与Mistral Medium在HellaSwag上的分数相似,而在Winogrande和MMLU上Mistral Medium更强,DBRX Instruct则在HumanEval、GSM8k和Inflection Corrected MTBench上更强。
推理速度
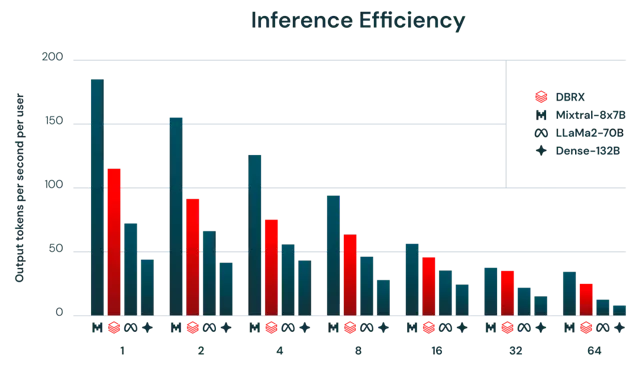
一般来说,MoE模型的推理速度比其总参数数量所暗示的要快。这是因为它们对每个输入使用相对较少的参数。我们发现DBRX在这方面也不例外。DBRX的推理吞吐量比一个132B非MoE模型高2-3倍。
推理效率和模型质量通常存在紧张关系:更大的模型通常能达到更高的质量,但较小的模型在推理时更高效。使用MoE架构可以实现在模型质量和推理效率之间比密集模型通常能达到的更好的权衡。例如,DBRX不仅质量高于LLaMA2-70B,而且由于活跃参数数量大约减半,DBRX的推理吞吐量可达到2倍(图2所示)。
Mixtral是MoE模型达到的改进帕累托最前沿的另一个示例:它比DBRX小,并且相应地在质量上较低,但达到了更高的推理吞吐量。使用Databricks基础模型API的用户可以期待在优化的模型服务平台上使用8位量化的DBRX达到每秒最多150个token。
项目链接
https://github.com/databricks/dbrx
关注「 开源AI项目落地 」公众号











