不知道大家有没有发现一个问题,凡是现在通过语音调用大模型的场景都会有延迟导致用户体验不好 ,比如AI陪伴类的硬件玩偶、AI电话客服还有实时对话的AI女友。
本质上都是因为跟大模型通过语音对话都要把语音转换成文本发送给大模型,再把大模型的回答转换成语音,我们才能听得到。
这样一来一回耗费的时间,才导致了我们跟大模型对话流畅度和自然感不够完美。
Ultravox是一个端到端的多模态大模型,能直接理解音频,不需要再把音频和文本相互转换。
现在已经在Llama 3、Mistral 和 Gemma 上训练了版本,可用度就很高了。
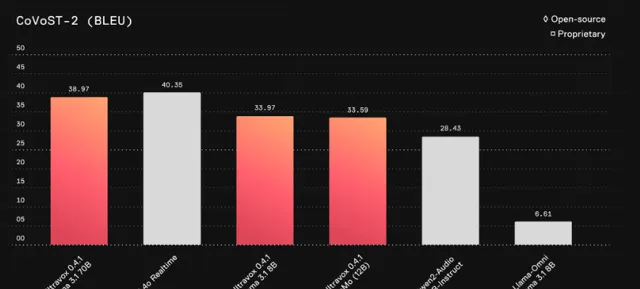
Ultravox 的语音理解能力接近GPT-4o的专有解决方案。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
Ultravox 是一种全新的多模态大语言模型,能够直接理解文本和人类语音,无需独立的语音识别阶段。Ultravox 通过与 LLM 高维空间的直接耦合,能够快速响应语音输入,具有约 150 毫秒的首次响应时间,并可达每秒 60 个 tokens。Ultravox 在 Llama 3、Mistral 和 Gemma 等 LLM 基础上进行训练,优化了多模态理解,且具有扩展性,可用于不同语言或自定义数据集的训练。
DEMO
技术特点
1.多模态输入处理:
Ultravox 能够同时处理文本和语音输入,并将音频直接转换为 LLM 所需的高维空间数据,而不需要额外的语音识别(ASR)阶段。这种设计使得系统在响应速度和资源消耗上都比传统的分离式 ASR 与 LLM 系统更高效。
2.快速响应:
当前版本 Ultravox 0.4 在处理音频输入时,首次生成 token 的时间大约为 150 毫秒,并且每秒生成约 60 个 tokens,具备很高的实时响应能力。虽然已有较高的性能,但团队认为还存在进一步优化的空间。
3.高效的模型耦合:
Ultravox 通过直接将音频与 LLM 模型耦合,避免了传统方法中将语音转文本再进行理解的复杂流程。这种方法显著减少了处理延迟,并提高了模型对语音的理解能力,未来还将加入情感和语音节奏等副语言线索的理解。
4.灵活的模型训练:
Ultravox 支持用户基于不同的 LLM(如 Llama 3、Mistral、Gemma 等)和音频编码器进行自定义训练。用户可以通过修改配置文件,选择不同的基础模型,并训练适配器以改进特定领域或语种的性能。
5.低资源需求的实时推理:
Ultravox 的实时推理可以通过 API 进行访问,并支持将音频内容以 WAV 文件的形式输入。对于需要实时语音理解的应用场景,Ultravox 提供了一套灵活且高效的推理框架。
6.支持扩展与自定义:
Ultravox 允许用户使用自己的音频数据进行训练,以添加新的语言或领域知识。训练过程支持通过 MosaicML 等平台进行大规模并行处理,也可以在本地环境中部署。
7.未来的语音流生成:
当前 Ultravox 支持将语音转换为文本,未来将扩展为可以生成语音流(通过 vocoder 进行语音合成)。这意味着 Ultravox 不仅能够理解语音,还能够以自然语音的形式进行回应。
8.训练和评估工具:
Ultravox 提供了丰富的训练与评估工具,支持用户自行训练模型或进行实验评估。模型训练过程使用简单的配置文件,支持多种分布式训练方式,如 DDP(分布式数据并行)训练,并且支持集成 WandB 等工具进行实验日志记录。
项目链接
https://github.com/fixie-ai/ultravox
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯
关注「 向量光年 」公众号
加速全行业向AI转变











