点击「 IT码徒 」, 关注,置顶 公众号
每日技术干货,第一时间送达!
ChatGPT的问世,在科技圈刮起了一股AI之风,各类人工智能驱动的自然语言处理模型就纷纷冒出来了,它们可以理解和学习人类的语言跟人类进行对话,并能根据聊天的上下文来进行互动。目前ChatGPT-4在某些专业知识领域已经达到甚至超过博士生的水平了。在翻译、创作、知识问答、图片生成、视频剪辑、编程、测试、检验等等领域,AI大模型可谓大放异彩!网上也议论纷纷,说以后AI要淘汰这个职业,那个职业的,搞得大家都人心惶惶的。实际上,AI大模型还是有一些局限性的,难以处理过于复杂的任务。但AI大模型的发展已经是大势所趋,不可逆转,它将深刻改变我们的工作和生活方式,相信大家都深有感触。因此,我们要积极拥抱AI大模型,不断提升自己的AI技能,与时俱进。
作为一个程序员,更应该紧跟技术的发展,才不会被淘汰,我们在通过大模型帮助我们解决问题的同时,也应该更近距离的去接触大模型,安装测试一些开源大模型,这样才能更深刻的理解大模型。
本次测试我们选择了 阿里最新开源的通义Qwen2大模型 ,其主要有以下优势:
最新发布的Qwen2系列性能很强,在十多个大模型权威测评榜单一举夺冠,超越Llama3,且作为一款开源模型,在各项测评中性能均超过文心4.0、豆包pro等闭源模型;
同时,Qwen的开源生态非常好,LLaMA-Factory、vLLM、Ollama等开源平台和工具都可支持;
通义的开源频率和速度全球无二、模型性能也不断进化,且多次登顶HuggingFace的开源大模型榜首,开发者口碑很好。
作为对比,我们会先安装Qwen1.5。下面是本次详细安装测试步骤,带领大家
更近距离体验大模型的魅力。
1
下载Ollama工具
官网: https://ollama.com
Github: https://github.com/ollama/ollama
开始测试前,我们先介绍一款工具, Ollama ,一个开源的大模型工具框架,它能在本地轻松部署和运行大型语言模型,如Llama 3, Phi 3, Mistral, Gemma,Qwen。它是专门设计用于在本地运行大型语言模型。 Ollama 和LLM(大型语言模型)的关系,有点类似于docker和镜像,我们可以在 Ollama 服务中管理和运行各种LLM,它将模型权重、配置和数据捆绑到一个包中,优化了设置和配置细节,包括GPU使用情况。
通过该工具,我们可以大大简化环境部署等问题,省去许多麻烦。
工具下载可以去官网 根据自己的电脑系统,直接下载。
|
|
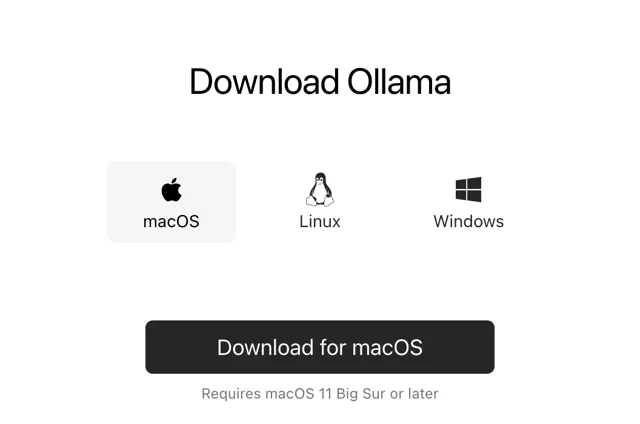
点击图片 查看大图
下载速度相对较慢,大家耐心等待下。
2
安装
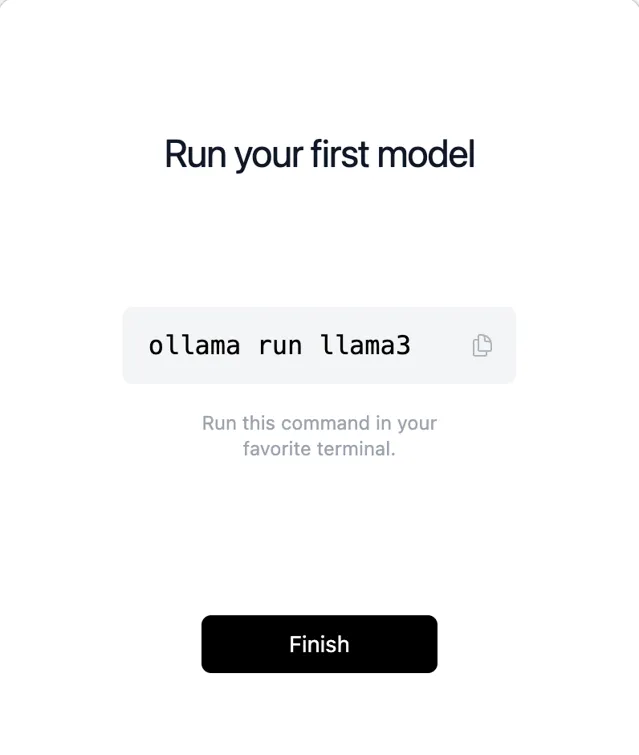
1、安装 Ollama
比较简单,本人是Mac,下载的是一个zip压缩包,直接解压安装,Win和Linux也是一样的,直接安装。
|
|
|
|


点击图片 查看大图
最后,点击Finish,安装完毕。
我们需要什么模型,可以直接在ollama.com 网站搜索我们需要下载的模型, 这里首先使用的是 阿里开源的通义千问大模型Qwen ,我们可以在网站搜下Qwen,如下:
|
|
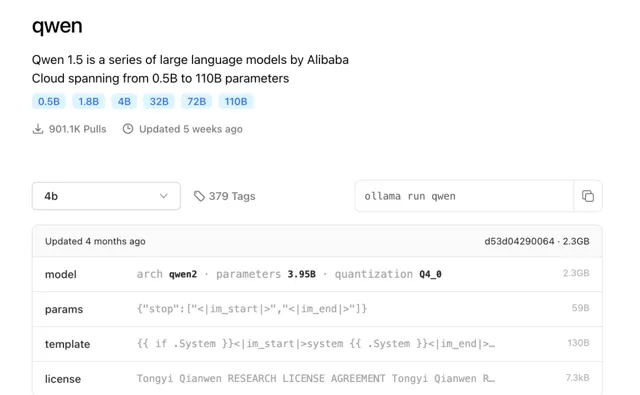

点击图片 查看大图
可以看到目前有多个不同参数训练的Qwen开源模型,不同数值对应不同的参数大小,第一次使用,先从最小的,使用了模型1.8b(18亿参数)。整个模型不到2G的大小。
具体操作,打开终端直接运行命令,下载速度比较快。
ollamarunqwen:1.8b
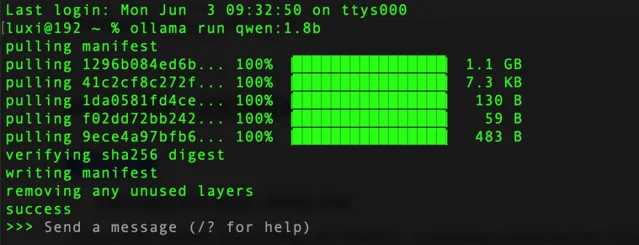
看到success表示已经安装完成,我们可以直接在终端下使用,进行提问。

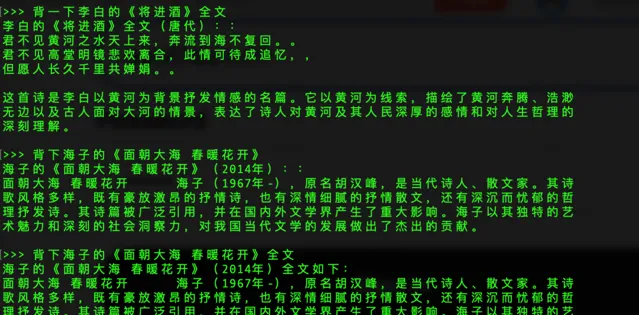
可以看到Qwen-1.8b的回答并不是很理想,初级版本明显问题较多,我们先放着,等下再下载其他更先进更准确的模型测试。
2、安装Docker(可选, 更好的体验 )
终端下操作,体验并不是很好,想要更好的体验,我们可以安装Docker,并启动open-webUI,这样我们可以在浏览器上使用自己下载的大模型,Docker的安装比较简单,这里不在过多介绍,基本是傻瓜式安装,官方下载。
地址: https://www.docker.com/products/docker-desktop/
安装时配置和注册信息我们都可以直接跳过。如果无法访问,请开魔法。
|
|

点击图片 查看大图
3、安装Open-WebUI
安装完毕Docker,我们打开终端,执行open-webui安装口令,如下:
docker run -d -p3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
|
|
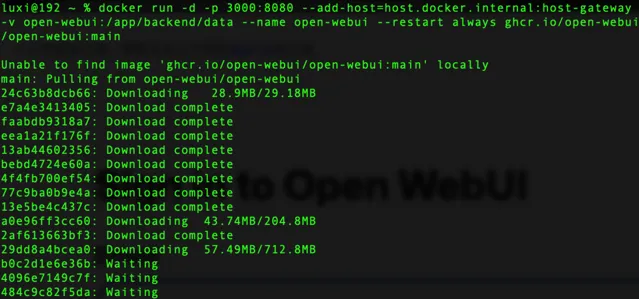
点击图片 查看大图
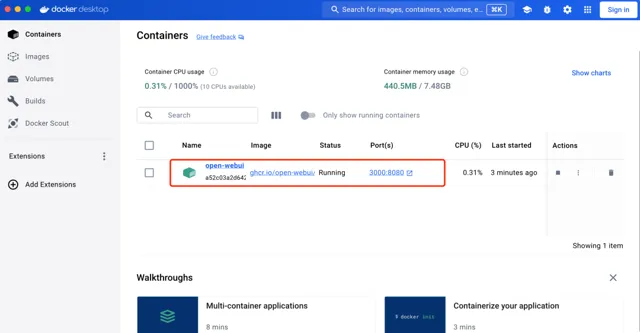
需要安装相应的组件,耐心等待下,下载完。我们可以通过Docker工具看到运行的open-webui,浏览器访问地址: http://localhost:3000/auth/
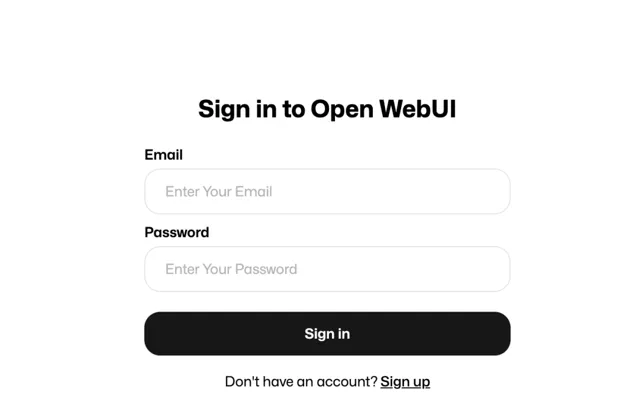
首次登陆,需要先点击Sign up注册,随便注册下,进入到管理后台。
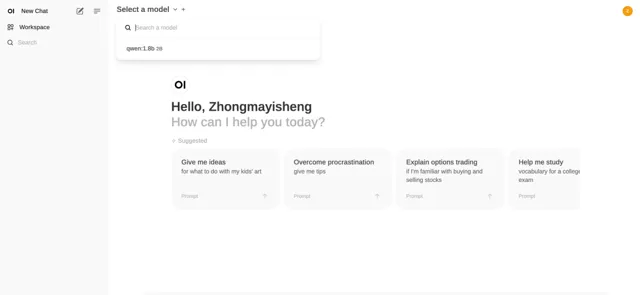
界面是不是有点似曾相识,没错,和GPT后台很相似。同样的,左上角可以选择我们安装的Qwen模型,如果我们安装多个模型的话,可以切换不同模型使用。

4、添加更先进的模型(Qwen2-7b)
因为刚才安装的1.8b,回答效果并不理想,这次我们添加刚刚开源的 通义千问Qwen2-7b ,70亿模型,大小在4G左右(当然,还有更先进,大家根据自己的电脑配置选择)
ollamarunqwen2:7b

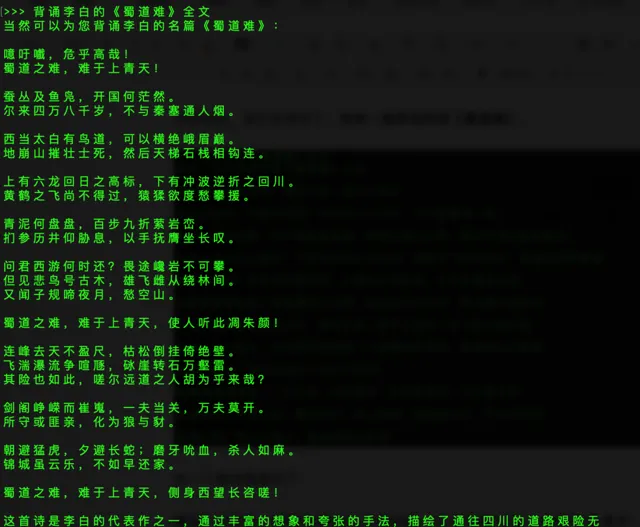
安装完成,我们在测试下, 先来一首李白的诗【蜀道难】 。
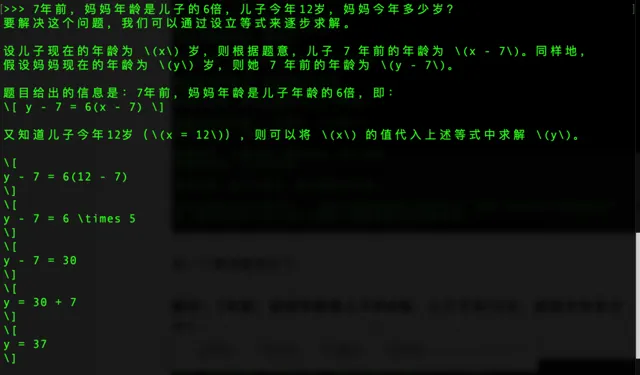
来一个算法题测试下
提问:7年前,妈妈年龄是儿子的6倍,儿子今年12岁,妈妈今年多少岁?
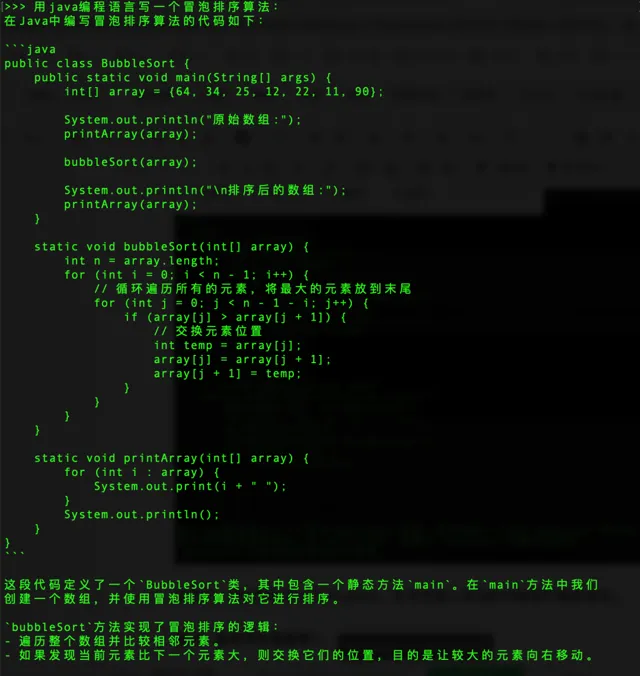
再来一个编程
提问:用java编程语言写一个冒泡排序算法:
当然了,我们同样可以打开webUI,在浏览器上来回的切换我们模型使用。
提问:如何评价陈独秀?

可以看出来,相比之前模型,Qwen-14b模型很明显理解能力和准确性要提升了许多,回答内容也更加优质。当然还有更先进的模型,像Qwen-32B,Qwen-72B和Qwen-110B,以及文章开头提到的Qwen2系列,也有不同尺寸,完全能够满足我们的需求,都可以按照上述方法部署。
3
最后
好了,今天的部署测试就到这里。 是不是很香,很方便,再也不用到处注册账号,申请试用了。现在完全可以自己搭建一个大模型,在本地就可以使用大模型。马上自己操作体验一下吧!!











