点击「 IT码徒 」, 关注,置顶 公众号
每日技术干货,第一时间送达!
今天给大家介绍一款 Python 爬虫项目,支持小红书爬虫,抖音爬虫, 快手爬虫, B站爬虫, 微博爬虫...。
❝
目前能抓取小红书、抖音、快手、B站、微博的视频、图片、评论、点赞、转发等信息。
❞功能列表
下面不支持的项目,相关的代码架构已经搭建好,只需要实现对应的方法即可
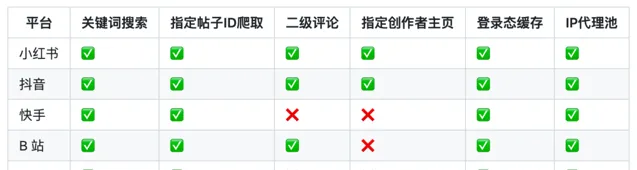
使用方法
创建并激活 python 虚拟环境
# 进入项目根目录
cd MediaCrawler
# 创建虚拟环境
# 注意python 版本需要3.7 - 3.9
python -m venv venv
# macos & linux 激活虚拟环境
source venv/bin/activate
# windows 激活虚拟环境
venv\Scripts\activate
安装依赖库
pip3 install -r requirements.txt
安装 playwright浏览器驱动
playwright install
运行爬虫程序
### 项目默认是没有开启评论爬取模式,如需评论请在config/base_config.py中的 ENABLE_GET_COMMENTS 变量修改
### 一些其他支持项,也可以在config/base_config.py查看功能,写的有中文注释
# 从配置文件中读取关键词搜索相关的帖子并爬取帖子信息与评论
python main.py --platform xhs --lt qrcode --type search
# 从配置文件中读取指定的帖子ID列表获取指定帖子的信息与评论信息
python main.py --platform xhs --lt qrcode --type detail
# 打开对应APP扫二维码登录
# 其他平台爬虫使用示例,执行下面的命令查看
python main.py --help
数据保存
支持保存到关系型数据库(Mysql、PgSQL等)
执行 python db.py 初始化数据库数据库表结构(只在首次执行)
支持保存到csv中(data/目录下)
支持保存到json中(data/目录下)
免责声明
❝
大家请以学习为目的使用本仓库,爬虫违法违规的案件:https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China
本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
❞开源地址
https://github.com/NanmiCoder/MediaCrawler
— END —
PS:防止找不到本篇文章,可以收藏点赞,方便翻阅查找哦。
往期推荐











