Grafana Labs 杰出工程师 Bryan Boreham 在 KubeCon 上详细介绍了他如何减少 Prometheus 的内存使用量。

Prometheus 内存消耗是观测可观察性可能导致系统崩溃的方式之一。
Grafana Labs 的杰出工程师Bryan Boreham在 KubeCon+CloudNativeCon 的演讲中,详细介绍了他如何尝试各种方法,最终减少Prometheus的内存使用量的经历。他演讲的标题是「Prometheus 如何将内存使用减半」,讲述了他对 Prometheus 的研究,特别是标签的内存消耗,揭示了减少内存消耗的方法。
根据Prometheus 文档,标签用于 区分 正在测量的事物的特征:
api_http_requests_total – 区分请求类型: **operation=create|update|delete**
api_request_duration_seconds – 区分请求阶段: stage=extract|transform|load
Boreham 的工作也本着开源精神,展示了贡献如何能够带来实质成果。在两年时间内,向监控系统项目提出了 30 个拉取(Pull)请求,修改了2500多行代码,Boreham 的工作帮助最新版本的 Prometheus 内存使用量锐减至之前版本的一半。
「这是一条漫长的道路,但最终(结果)令人非常满意。」 Boreham 在KubeCon+CloudNativeCon 之后告诉 The New Stack,「数十万台 Prometheus 服务器在运行,通过降低内存需求,我们降低了运行它们的成本及其碳足迹。」
Go 的内存分析器
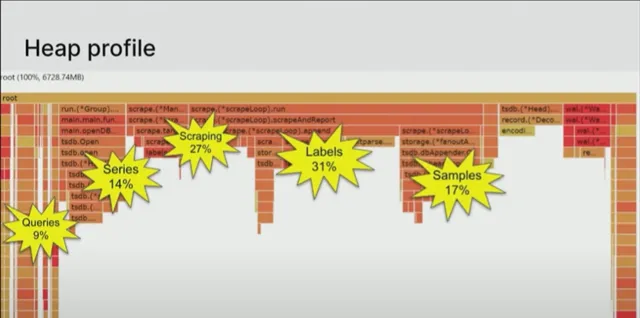
图表中出现了所谓的 锯齿效应(sawtooth effect) 。Boreham 告诉 The New Stack,随着时间推移垃圾不断积累,然后被收集,因此内存急剧下降,然后垃圾重新积累,这就是锯齿效应。
「Go 内存分析器报告上次垃圾回收时的内存使用情况,因此,您在这张图片中永远不会看到垃圾。很多人认为,‘哦,这可能主要是垃圾,我不需要考虑它’。「Boreham说道,「但是当你查看 Go 的配置文件时,这绝不是垃圾。这是锯齿底部,是不能丢弃的内容。」
「减少内存消耗的过程首先要问,‘好吧,是什么让它变得这么大?’。但总体而言,获胜者是大约两年前的情况,Prometheus 内部几乎三分之一的内存都被标签占用了(图中为 31%)。」
Prometheus 标签的问题
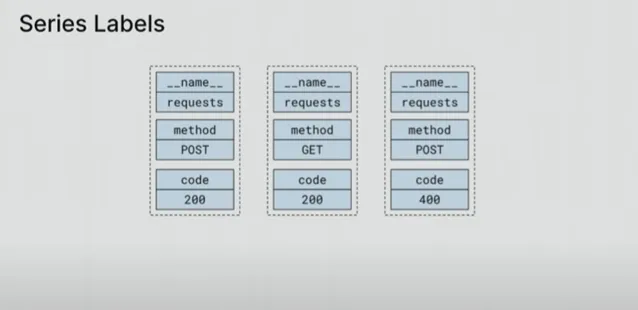
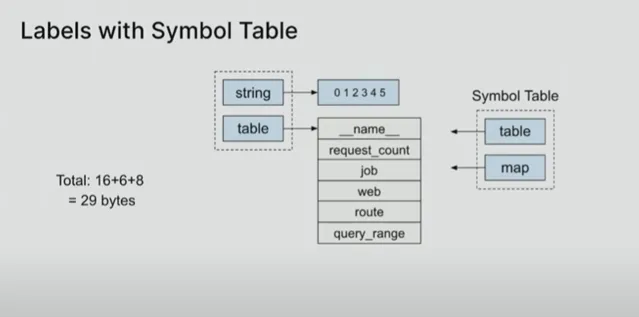
Boreham 解释说,Prometheus 中的每个系列(Series)都由这个名称/值对集唯一标识。如果你有另一个相关的系列,唯一的区别在于方法,实际上,你会得到一套全新的字符串。「所以,你看了会说,好吧,这很愚蠢,我只有一份字符串。但事情并没有那么简单。」
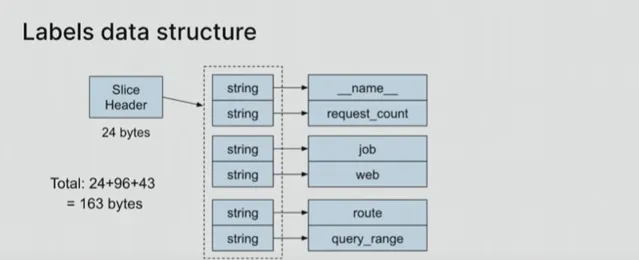
上图展示了其中的数据结构。指向所有标签的切片标头为24字节,每个字符串都有一个16字节的字符串标头。「它是一个指向内容和长度的指针, 如果你把它们全部加起来,就会发现数据结构中的所有这些指针的大小都比字符串本身大得多。」
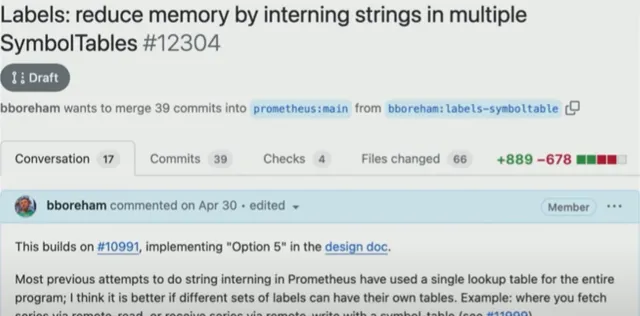
使用Prometheus PR 10991,Boreham 将所有字符串放入一个字符串中,并用长度对它们进行编码:
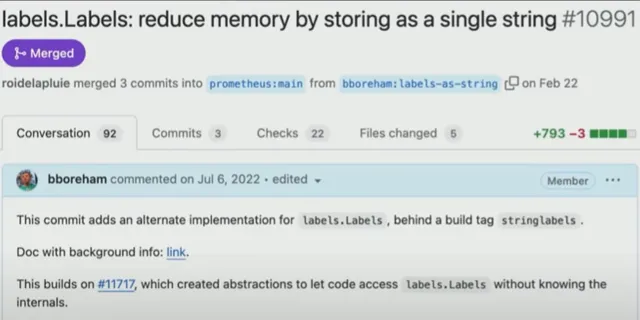


「花一年的时间更改了2500行代码,因为有大量代码只是假设它自己知道数据结构是什么样的。」
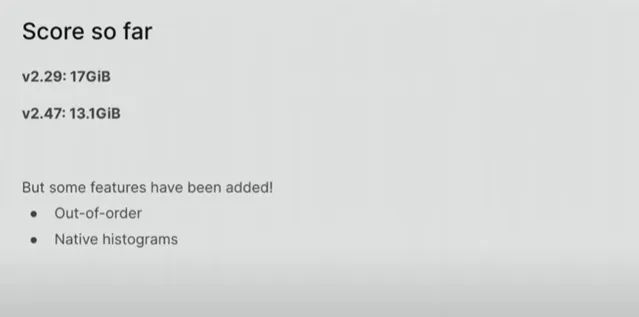
在 Prometheus 2.74.2 中,虽然之前的版本会在17 GB内存消耗时崩溃,但 Boreham 运行2.47.2,内存消耗为13.1GB,没有发生任何事故:
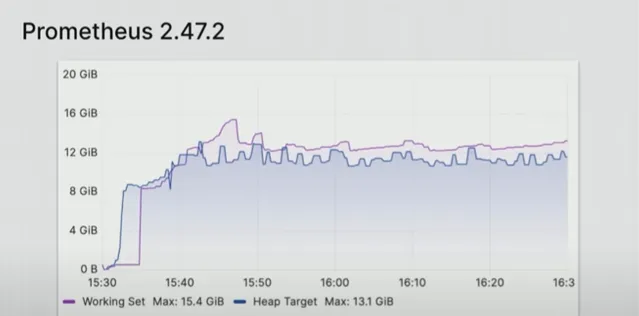
虽然2.47.2中添加了样本处理和原生直方图功能,但「它们并没有真正耗尽所有内存,」Boreham 说,虽然内存消耗显著减少,但尚未完全达到50%的水平。
Boreham 随后发现并修复了 2.39 中的一个错误:事务隔离环,该错误「过去在某些条件下会变得巨大」,Boreham 说。「但我算了一下,内存消耗仍然没有完全减少一半」:
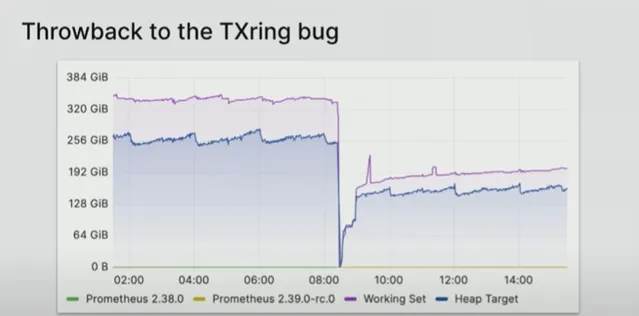
该错误修复将内存消耗减少至 10 GB:

Boreham 继续研究 Go 分析器,以瞄准内存消耗的罪魁祸首。
选择最大的数字,然后研究它,如果可以找到其中的一些低效之处,然后再做一遍。原来第二大数字现在变成了最大数字,一开始并没有那么大的数字现在已经是很大的数字了。所以这是一次很好的自我强化过程。
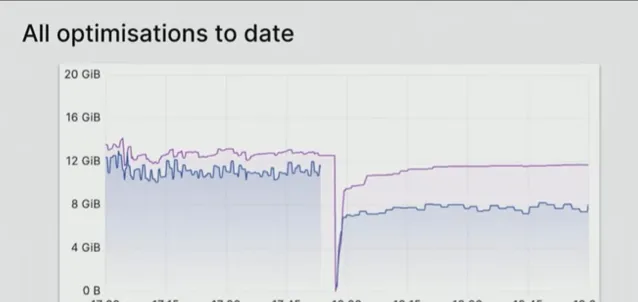
这是 2.47 加上上图中的所有 PR,总共 8.6 GB 内存消耗,几乎达到了 50% 的减少标记:

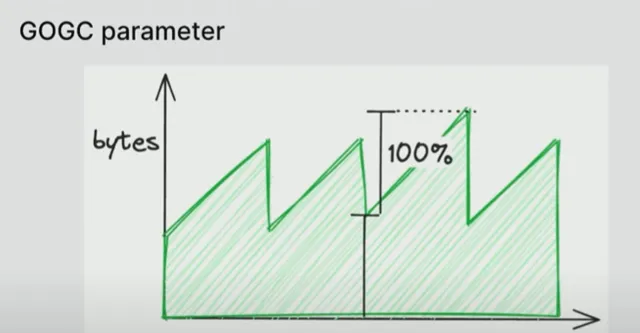
正如 Boreham 的解释,Go 运行时中有一个参数名为 GoGC,默认值为 100。锯齿大小增长到锯齿底部大小的 100%,即 7 GB。对于那些拥有 100 GB Prometheus 的人来说,它增长了 50 GB,但出于维护目的,你不需要 50 GB 的垃圾来运行有效的堆,你可以调整这个数字——这是一个可设置的环境变量,它会增长到你设置的百分比,超过其最小值,并且垃圾收集速度会加快一些。
Prometheus 此后一直在 8 GB 内存下运行——内存消耗已达到 50%。Boreham已经达到了他的目标:
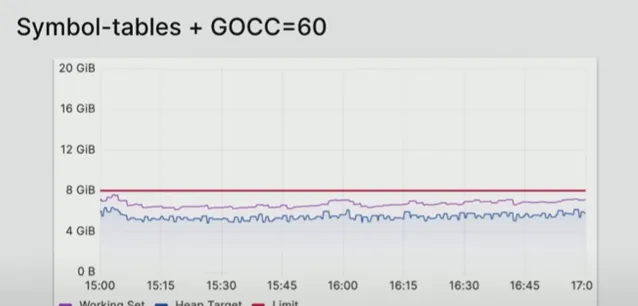
Prometheus 用户必然倾心更低的内存消耗,而大多数人怎么实现内存低消耗可能不太感兴趣。
但对于那些喜欢回馈开源社区的人来说,Boreham 的艰辛表明,只要付出大量的工作和耐心,就可以提出能够产生实际影响的拉取请求 (PR)。虽然Boreham的工作在事后看来可能很简单,但显然并非如此——数学和科学研究中经常出现这种情况。Prometheus 以及一般的开源项目为用户和那些对计算感兴趣的人提供了做出贡献的机会。
Boreham告诉 The New Stack:「这确实是一种为爱发电的工作,让计算机程序变得更小、更快对我来说是一种痴迷爱好,所以能够在如此受欢迎和广泛使用的项目中被采用真是太好了。而且,在 Grafana Labs,‘开源深植于我们的DNA中’。」
编译丨公众号:DevOps云学堂(ID:idevopsvip)
来源丨thenewstack.io/30-pull-requests-later-prometheus-memory-use-is-cut-in-half/
dbaplus社群欢迎广大技术人员投稿,投稿邮箱: [email protected]












