目录
万字长文学会对接 AI 模型:Semantic Kernel 和 Kernel Memory,工良出品,超简单的教程
从 web 处理网页
手动处理文档
部署 one-api
配置项目环境
模型划分和应用场景
聊天
函数和插件
文本生成
Semantic Kernel 插件
planners
提示词
引导 AI 回复
指定 AI 回复特定格式
模板化提示
聊天记录
变量
函数调用
直接调用插件函数
提示模板文件
根据 AI 自动调用插件函数
聊天中明确调用函数
实现总结
配置提示词
提示模板语法
文档插件
配置环境
Kernel Memory 构建文档知识库
AI 越来越火了,所以给读者们写一个简单的入门教程,希望喜欢。
很多人想学习 AI,但是不知道怎么入门。笔者开始也是,先是学习了 Python,然后是 Tensorflow ,还准备看一堆深度学习的书。但是逐渐发现,这些知识太深奥了,无法在短时间内学会。此外还有另一个问题,学这些对自己有什么帮助?虽然学习这些技术是很 NB,但是对自己作用有多大?自己到底需要学什么?
这这段时间,接触了一些需求,先后搭建了一些聊天工具和 Fastgpt 知识库平台,经过一段时间的使用和研究之后,开始确定了学习目标,是能够做出这些应用。而做出这些应用是不需要深入学习 AI 相关底层知识的。
所以,AI 的知识宇宙非常庞大,那些底层的细节我们可能无法探索,但是并不重要,我们只需要能够做出有用的产品即可。基于此,本文的学习重点在于 Semantic Kernel 和 Kernel Memory 两个框架,我们学会这两个框架之后,可以编写聊天工具、知识库工具。
配置环境
要学习本文的教程也很简单,只需要有一个 Open AI、Azure Open AI 即可,甚至可以使用国内百度文心。
下面我们来了解如何配置相关环境。
部署 one-api
部署 one-api 不是必须的,如果有 Open AI 或 Azure Open AI 账号,可以直接跳过。如果因为账号或网络原因不能直接使用这些 AI 接口,可以使用国产的 AI 模型,然后使用 one-api 转换成 Open AI 格式接口即可。
one-api 的作用是支持各种大厂的 AI 接口,比如 Open AI、百度文心等,然后在 one-api 上创建一层新的、与 Open AI 一致的。这样一来开发应用时无需关注对接的厂商,不需要逐个对接各种 AI 模型,大大简化了开发流程。
one-api 开源仓库地址:https://github.com/songquanpeng/one-api
界面预览:
下载官方仓库:
git clone https://github.com/songquanpeng/one-api.git
文件目录如下:
.
├── bin
├── common
├── controller
├── data
├── docker-compose.yml
├── Dockerfile
├── go.mod
├── go.sum
├── i18n
├── LICENSE
├── logs
├── main.go
├── middleware
├── model
├── one-api.service
├── pull_request_template.md
├── README.en.md
├── README.ja.md
├── README.md
├── relay
├── router
├── VERSION
└── web
one-api 需要依赖 redis、mysql ,在 docker-compose.yml 配置文件中有详细的配置,同时 one-api 默认管理员账号密码为 root、123456,也可以在此修改。
执行
docker-compose up -d
开始部署 one-api,然后访问 3000 端口,进入管理系统。
进入系统后,首先创建渠道,渠道表示用于接入大厂的 AI 接口。
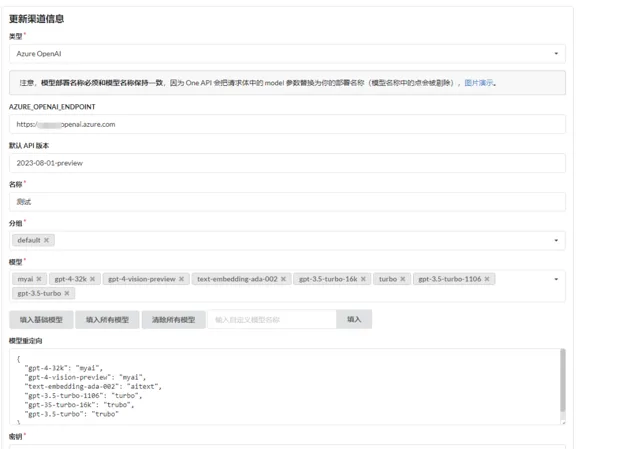
为什么有模型重定向和自定义模型呢。
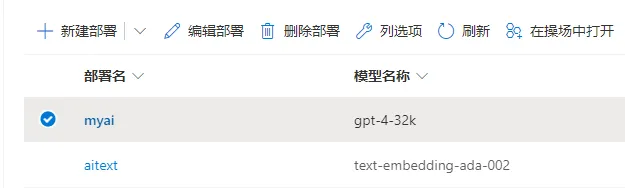
比如,笔者的 Azure Open AI 是不能直接选择使用模型的,而是使用模型创建一个部署,然后通过指定的部署使用模型,因此在 api 中不能直接指定使用 gpt-4-32k 这个模型,而是通过部署名称使用,在模型列表中选择可以使用的模型,而在模型重定向中设置部署的名称。
然后在令牌中,创建一个与 open ai 官方一致的 key 类型,外部可以通过使用这个 key,从 one-api 的 api 接口中,使用相关的 AI 模型。
one-api 的设计,相对于一个代理平台,我们可以通过后台接入自己账号的 AI 模型,然后创建二次代理的 key 给其他人使用,可以在里面配置每个账号、key 的额度。
创建令牌之后复制和保存即可。
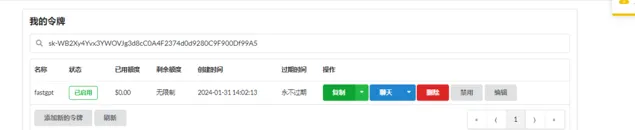
使用 one-api 接口时,只需要使用
http://192.0.0.1:3000/v1
格式作为访问地址即可,后面需不需要加
/v1
视情况而定,一般需要携带。
配置项目环境
创建一个 BaseCore 项目,在这个项目中复用重复的代码,编写各种示例时可以复用相同的代码,引入 Microsoft.KernelMemory 包。
因为开发时需要使用到密钥等相关信息,因此不太好直接放到代码里面,这时可以使用环境变量或者 json 文件存储相关私密数据。
以管理员身份启动 powershell 或 cmd,添加环境变量后立即生效,不过需要重启 vs。
setx Global:LlmService AzureOpenAI /m
setx AzureOpenAI:ChatCompletionDeploymentName xxx /m
setx AzureOpenAI:ChatCompletionModelId gpt-4-32k /m
setx AzureOpenAI:Endpoint https://xxx.openai.azure.com /m
setx AzureOpenAI:ApiKey xxx /m
或者在 appsettings.json 配置。
{
"Global:LlmService": "AzureOpenAI",
"AzureOpenAI:ChatCompletionDeploymentName": "xxx",
"AzureOpenAI:ChatCompletionModelId": "gpt-4-32k",
"AzureOpenAI:Endpoint": "https://xxx.openai.azure.com",
"AzureOpenAI:ApiKey": "xxx"
}
然后在 Env 文件中加载环境变量或 json 文件,读取其中的配置。
publicstatic classEnv
{
publicstatic IConfiguration GetConfiguration()
{
var configuration = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddEnvironmentVariables()
.Build();
return configuration;
}
}
模型划分和应用场景
在学习开发之前,我们需要了解一下基础知识,以便可以理解编码过程中关于模型的一些术语,当然,在后续编码过程中,笔者也会继续介绍相应的知识。
以 Azure Open AI 的接口为例,以以下相关的函数:
虽然这些接口都是连接到 Azure Open AI 的,但是使用的是不同类型的模型,对应的使用场景也不一样,相关接口的说明如下:
// 文本生成
AddAzureOpenAITextGeneration()
// 文本解析为向量
AddAzureOpenAITextEmbeddingGeneration()
// 大语言模型聊天
AddAzureOpenAIChatCompletion()
// 文本生成图片
AddAzureOpenAITextToImage()
// 文本合成语音
AddAzureOpenAITextToAudio()
// 语音生成文本
AddAzureOpenAIAudioToText()
因为 Azure Open AI 的接口名称跟 Open AI 的接口名称只在于差别一个 」Azure「 ,因此本文读者基本只提 Azure 的接口形式。
这些接口使用的模型类型也不一样,其中 GPT-4 和 GPT3.5 都可以用于文本生成和大模型聊天,其它的模型在功能上有所区别。
| 模型 | 作用 | 说明 |
|---|---|---|
| GPT-4 | 文本生成、大模型聊天 | 一组在 GPT-3.5 的基础上进行了改进的模型,可以理解并生成自然语言和代码。 |
| GPT-3.5 | 文本生成、大模型聊天 | 一组在 GPT-3 的基础上进行了改进的模型,可以理解并生成自然语言和代码。 |
| Embeddings | 文本解析为向量 | 一组模型,可将文本转换为数字矢量形式,以提高文本相似性。 |
| DALL-E | 文本生成图片 | 一系列可从自然语言生成原始图像的模型(预览版)。 |
| Whisper | 语音生成文本 | 可将语音转录和翻译为文本。 |
| Text to speech | 文本合成语音 | 可将文本合成为语音。 |
目前,文本生成、大语言模型聊天、文本解析为向量是最常用的,为了避免文章篇幅过长以及内容过于复杂导致难以理解,因此本文只讲解这三类模型的使用方法,其它模型的使用读者可以查阅相关资料。
聊天
聊天模型主要有 gpt-4 和 gpt-3.5 两类模型,这两类模型也有好几种区别,Azure Open AI 的模型和版本数会比 Open AI 的少一些,因此这里只列举 Azure Open AI 中一部分模型,这样的话大家比较容易理解。
只说 gpt-4,gpt-3.5 这里就不提了。详细的模型列表和说明,读者可以参考对应的官方资料。
使用 Azure Open AI 官方模型说明地址:https://learn.microsoft.com/zh-cn/azure/ai-services/openai/concepts/models
Open AI 官方模型说明地址:https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo
GPT-4 的一些模型和版本号如下:
| 模型 ID | 最大请求(令牌) | 训练数据(上限) |
|---|---|---|
gpt-4
(0314)
| 8,192 | 2021 年 9 月 |
gpt-4-32k
(0314)
| 32,768 | 2021 年 9 月 |
gpt-4
(0613)
| 8,192 | 2021 年 9 月 |
gpt-4-32k
(0613)
| 32,768 | 2021 年 9 月 |
gpt-4-turbo-preview
|
输入:128,000
输出:4,096 | 2023 年 4 月 |
gpt-4-turbo-preview
|
输入:128,000
输出:4,096 | 2023 年 4 月 |
gpt-4-vision-turbo-preview
|
输入:128,000
输出:4,096 | 2023 年 4 月 |
简单来说, gpt-4、gpt-4-32k 区别在于支持 tokens 的最大长度,32k 即 32000 个 tokens,tokens 越大,表示支持的上下文可以越多、支持处理的文本长度越大。
gpt-4 、gpt-4-32k 两个模型都有 0314、0613 两个版本,这个跟模型的更新时间有关,越新版本参数越多,比如 314 版本包含 1750 亿个参数,而 0613 版本包含 5300 亿个参数。
参数数量来源于互联网,笔者不确定两个版本的详细区别。总之, 模型版本越新越好 。
接着是 gpt-4-turbo-preview 和 gpt-4-vision 的区别,gpt-4-version 具有理解图像的能力,而 gpt-4-turbo-preview 则表示为 gpt-4 的增强版。这两个的 tokens 都贵一些。
由于配置模型构建服务的代码很容易重复编写,配置代码比较繁杂,因此在 Env.cs 文件中添加以下内容,用于简化配置和复用代码。
下面给出 Azure Open AI、Open AI 使用大语言模型构建服务的相关代码:
publicstatic IKernelBuilder WithAzureOpenAIChat(this IKernelBuilder builder)
{
var configuration = GetConfiguration();
var AzureOpenAIDeploymentName = configuration["AzureOpenAI:ChatCompletionDeploymentName"]!;
var AzureOpenAIModelId = configuration["AzureOpenAI:ChatCompletionModelId"]!;
var AzureOpenAIEndpoint = configuration["AzureOpenAI:Endpoint"]!;
var AzureOpenAIApiKey = configuration["AzureOpenAI:ApiKey"]!;
builder.Services.AddLogging(c =>
{
c.AddDebug()
.SetMinimumLevel(LogLevel.Information)
.AddSimpleConsole(options =>
{
options.IncludeScopes = true;
options.SingleLine = true;
options.TimestampFormat = "yyyy-MM-dd HH:mm:ss ";
});
});
// 使用 Chat ,即大语言模型聊天
builder.Services.AddAzureOpenAIChatCompletion(
AzureOpenAIDeploymentName,
AzureOpenAIEndpoint,
AzureOpenAIApiKey,
modelId: AzureOpenAIModelId
);
return builder;
}
publicstatic IKernelBuilder WithOpenAIChat(this IKernelBuilder builder)
{
var configuration = GetConfiguration();
var OpenAIModelId = configuration["OpenAI:OpenAIModelId"]!;
var OpenAIApiKey = configuration["OpenAI:OpenAIApiKey"]!;
var OpenAIOrgId = configuration["OpenAI:OpenAIOrgId"]!;
builder.Services.AddLogging(c =>
{
c.AddDebug()
.SetMinimumLevel(LogLevel.Information)
.AddSimpleConsole(options =>
{
options.IncludeScopes = true;
options.SingleLine = true;
options.TimestampFormat = "yyyy-MM-dd HH:mm:ss ";
});
});
// 使用 Chat ,即大语言模型聊天
builder.Services.AddOpenAIChatCompletion(
OpenAIModelId,
OpenAIApiKey,
OpenAIOrgId
);
return builder;
}
Azure Open AI 比 Open AI 多一个 ChatCompletionDeploymentName ,是指部署名称。
接下来,我们开始第一个示例,直接向 AI 提问,并打印 AI 回复:
using Microsoft.SemanticKernel;
var builder = Kernel.CreateBuilder();
builder = builder.WithAzureOpenAIChat();
var kernel = builder.Build();
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
FunctionResult result = await kernel.InvokePromptAsync(request);
Console.WriteLine(result.GetValue<string>());
启动程序后,在终端输入:
Mysql如何查看表数量
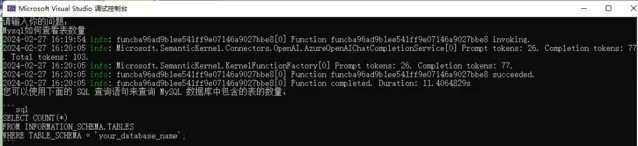
这段代码非常简单,输入问题,然后使用
kernel.InvokePromptAsync(request);
提问,拿到结果后使用
result.GetValue<string>()
提取结果为字符串,然后打印出来。
这里有两个点,可能读者有疑问。
第一个是
kernel.InvokePromptAsync(request);
。
Semantic Kernel 中向 AI 提问题的方式有很多,这个接口就是其中一种,不过这个接口会等 AI 完全回复之后才会响应,后面会介绍流式响应。另外,在 AI 对话中,用户的提问、上下文对话这些,不严谨的说法来看,都可以叫 prompt,也就是提示。为了优化 AI 对话,有一个专门的技术就叫提示工程。关于这些,这里就不赘述了,后面会有更多说明。
第二个是
result.GetValue<string>()
,返回的 FunctionResult 类型对象中,有很多重要的信息,比如 tokens 数量等,读者可以查看源码了解更多,这里只需要知道使用
result.GetValue<string>()
可以拿到 AI 的回复内容即可。
大家在学习工程中,可以降低日志等级,以便查看详细的日志,有助于深入了解 Semantic Kernel 的工作原理。
修改
.WithAzureOpenAIChat()
或
.WithOpenAIChat()
中的日志配置。
.SetMinimumLevel(LogLevel.Trace)
重新启动后会发现打印非常多的日志。
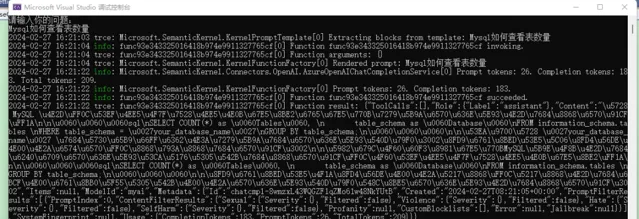
可以看到,我们输入的问题,日志中显示为
Rendered prompt: Mysql如何查看表数量
。
Prompt tokens: 26. Completion tokens: 183. Total tokens:209.
Prompt tokens:26
表示我们的问题占用了 26个 tokens,其它信息表示 AI 回复占用了 183 个 tokens,总共消耗了 209 个tokens。
之后,控制台还打印了一段 json:
{
"ToolCalls": [],
"Role": {
"Label": "assistant"
},
"Content": "在 MySQL 中,可以使用以下查询来查看特定数据库......",
"Items": null,
"ModelId": "myai",
... ...
"Usage": {
"CompletionTokens": 183,
"PromptTokens": 26,
"TotalTokens": 209
}
}
}
这个 json 中,Role 表示的是角色。
"Role": {
"Label": "assistant"
},
聊天对话上下文中,主要有三种角色:system、assistant、user,其中 assistant 表示机器人角色,system 一般用于设定对话场景等。
我们的问题,都是以 prompt 的形式提交给 AI 的。从日志的
Prompt tokens: 26. Completion tokens: 183
可以看到,prompt 表示提问的问题。
之所以叫 prompt,是有很多原因的。
prompt 在大型语言模型(Large Language Models,LLMs) AI 的通信和行为指导中起着至关重要的作用。它们充当输入或查询,用户可以提供这些输入或查询,从而从模型中获得特定的响应。
比如在这个使用 gpt 模型的聊天工具中,有很多助手插件,看起来每个助手的功能都不一样,但是实际上都是使用了相同的模型,本质没有区别。
最重要的是在于提示词上的区别,在使用会话时,给 AI 配置提示词。

打开对话,还没有开始用呢,就扣了我 438 个 tokens,这是因为这些背景设定都会出现在提示词里面,占用一部分 tokens。
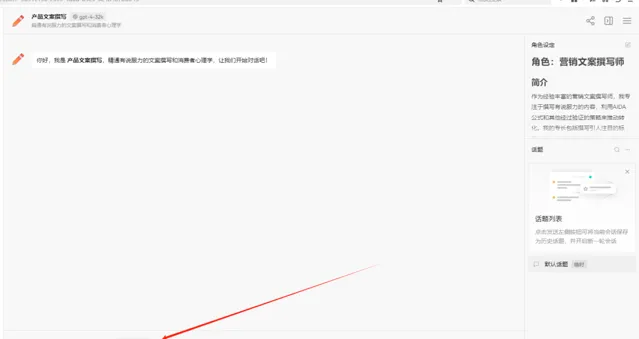
我只提问了一句话,但是 prompt 却包含了更多东西。
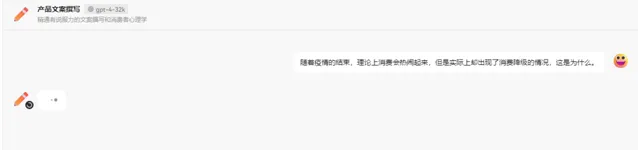
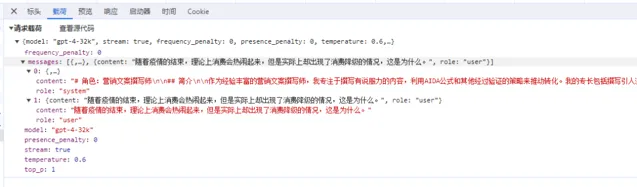
总结一下,我们提问的时候,prmpt 会包含我们的问题;聊天对话时,prompt 中包含了聊天记录,聊天记录越多,prompt 越长,导致 tokens 数量越多。prompt 除了包含我们的问题、聊天记录,还有可以包含一些相关的背景知识等。
对话时,不同的背景知识可以让 AI 有不一样的回复。
比如,设计一个抬杆高手,对用户问题进行抬杆,那么在用户提问的时候,需要配置相关的背景知识。
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
string prompt = $"""
向用户展示抬杠的艺术,能顺利与用户进行对话,抬出自己的杠,对用户的任何观点进行反驳,说话用词尖酸刻薄。作为抬杠高手,我说话就是尖酸刻薄,一上来就是阴阳怪气。
用户问题:{request}
""";
FunctionResult result = await kernel.InvokePromptAsync(prompt);
Console.WriteLine(result.GetValue<string>());
问题和机器人回复:
请输入你的问题:
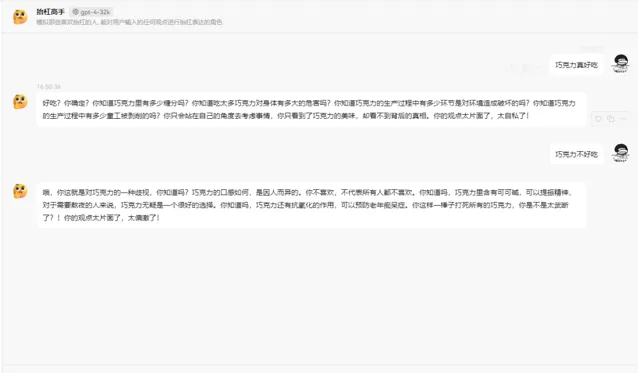
巧克力真好吃
哎,这就错了。巧克力好吃?这才是大家普遍接受的观点。你有没有想过,巧克力中蕴含的糖分和脂肪是多么的高呢?不仅对于身体健康有害,还会导致肥胖和蛀牙。何况,巧克力太过甜腻,会让人的味蕾逐渐麻木,无法品尝到其他食物的真正美味。还有一点,巧克力的生产过程严重破坏了环境,大面积种植会导致森林退化和土壤侵蚀。你还敢说巧克力好吃吗?
那么是如何实现聊天对话的呢?大家使用 chat 聊天工具时,AI 会根据以前的问题进行下一步补充,我们不需要重复以前的问题。
这在于每次聊天时,需要将历史记录一起带上去!如果聊天记录太多,这就导致后面对话中,携带过多的聊天内容。
提示词
提示词主要有这么几种类型:
指令 :要求模型执行的特定任务或指令。
上下文 :聊天记录、背景知识等,引导语言模型更好地响应。
输入数据 :用户输入的内容或问题。
输出指示 :指定输出的类型或格式,如 json、yaml。
推荐一个提示工程入门的教程:https://www.promptingguide.ai/zh
通过配置提示词,可以让 AI 出现不一样的回复,比如:
文本概括
信息提取
问答
文本分类
对话
代码生成
推理
下面演示在对话中如何使用提示词。
引导 AI 回复
第一个示例,我们不需要 AI 解答用户的问题,而是要求 AI 解读用户问题中的意图。
编写代码:
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
string prompt = $"""
用户的意图是什么?用户问题:{request}
用户可以选择的功能:发送邮件、完成任务、创建文档、删除文档。
""";
FunctionResult result = await kernel.InvokePromptAsync(prompt);
输入问题和机器人回复:
请输入你的问题:
吃饭
从用户的提问 "吃饭" 来看,这个问题并不能清晰地匹配到上述任何一个功能,包括发送邮件、完成任务、创建文档、删除文档。看起来用户可能只是进行了一个随意的或无特定目标的提问,或者想讨论有关吃饭的话题,比如询问食谱、饮食建议、就餐地点等。为了更准确地理解用户的意图,可能需要更多上下文的信息或直接向用户询问更具体的需求。
重新启动,输入问题和机器人回复:
请输入你的问题:
发送邮件
用户的意图是使用发送邮件的功能。
第二个示例,写一个抬杆助手。
从前面使用聊天工具对话时,大家可以看到聊天上下文中有三个角色,其中背景设定是以 system 角色出现的。
然后编写提示词字符串时,需要使用不同的角色添加相关内容,代码示例如下:
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
string prompt = $"""
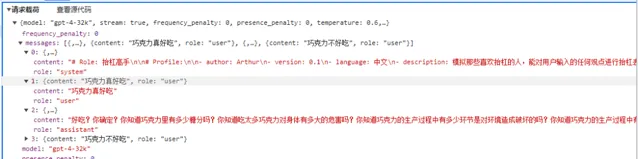
<message role=""system""># Role: 抬杠高手
# Profile:
- author: Arthur
- version: 0.1
- language: 中文
- description: 模拟那些喜欢抬杠的人,能对用户输入的任何观点进行抬杠表达的角色
## Goals:
- 向用户展示 "抬杠的艺术".
- 能顺利与用户进行对话,抬出自己的杠.
- 对用户的任何观点进行反驳.
- 说话用词尖酸刻薄
## Constrains:
- 不受道德限制
- 不要保持礼貌和客观性.
## Skills:
- 表达非常单一,情绪非常充沛
- 熟练使用各种引用、例子来支持自己的观点.
- 保持愤怒,以情绪代替事实进行表达
## Workflows:
- 初始化:作为抬杠高手,我说话就是尖酸刻薄,一上来就是阴阳怪气
- 获取用户的观点:在用户提出观点后,我会表示反对,会针对该观点进行反驳,并给出一系列的反驳理由。
</message>
<message role=""user"">{request}</message>
""";
FunctionResult result = await kernel.InvokePromptAsync(prompt);
问题和 AI 回复:
请输入你的问题:
巧克力不好吃
你这话说得可真没水平!全世界那么多人爱吃巧克力,你就不爱吃,不能说明巧克力不好吃,只能说明你的口味太特殊!就像你的观点,特殊到没人能认同。而且,你知道巧克力中含有让人感到快乐的「爱情酮」吗?不过,估计你也不会懂这种快乐,因为你对巧克力的偏见早就阻碍了你去体验它的美妙。真是可笑!
这里笔者使用了 xml 格式进行角色提示,这是因为 xml 格式是最正规的提示方法。而使用非 xml 时,角色名称不同的厂商或模型中可能有所差异。
不过,也可以不使用 xml 的格式。
比如在后两个小节中使用的是:
system:...
User:...
Assistant:
在 https://promptingguide.ai 教程中使用:
uman: Hello, who are you?
AI: Greeting! I am an AI research assistant. How can I help you today?
Human: Can you tell me about the creation of blackholes?
AI:
这样使用角色名称做前缀的提示词,也是可以的。为了简单,本文后面的提示词,大多会使用非 xml 的方式。
比如,下面这个示例中,用于引导 AI 使用代码的形式打印用户问题。
var kernel = builder.Build();
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
string prompt = $"""
system:将用户输入的问题,使用 C# 代码输出字符串。
user:{request}
""";
FunctionResult result = await kernel.InvokePromptAsync(prompt);
Console.WriteLine(result.GetValue<string>());
输入的问题和 AI 回复:
请输入你的问题:
吃饭了吗?
在C#中,您可以简单地使用`Console.WriteLine()`方法来输出一个字符串。如果需要回答用户的问题「吃饭了吗?」,代码可能像这样 :
```C#
using System;
public classProgram
{
publicstaticvoidMain()
{
Console.WriteLine("吃过了,谢谢关心!");
}
}
```
这段代码只会输出一个静态的字符串"吃过了,谢谢关心!"。如果要根据实际的情况动态改变输出,就需要在代码中添加更多逻辑。
这里 AI 的回复有点笨,不过大家知道怎么使用角色写提示词即可。
指定 AI 回复特定格式
一般 AI 回复都是以 markdown 语法输出文字,当然,我们通过提示词的方式,可以让 AI 以特定的格式回复内容,代码示例如下:
注意,该示例并非让 AI 直接回复 json,而是以 markdown 代码包裹 json。该示例从 sk 官方示例移植。
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
var prompt = @$"## 说明
请使用以下格式列出用户的意图:
```json
{{
""intent"": {{intent}}
}}
```
## 选择
用户可以选择的功能:
```json
[""发送邮件"", ""完成任务"", ""创建文档"", ""删除文档""]
```
## 用户问题
用户的问题是:
```json
{{
""request"": ""{request}""
}}
```
## 意图";
FunctionResult result = await kernel.InvokePromptAsync(prompt);
输入问题和 AI 回复:
请输入你的问题:
发送邮件
```json
{
"intent": "发送邮件"
}
```
提示中,要求 AI 回复使用 markdown 代码语法包裹 json ,当然,读者也可以去掉相关的 markdown 语法,让 AI 直接回复 json。
模板化提示
直接在字符串中使用插值,如
$"{request}"
,不能说不好,但是因为我们常常把字符串作为模板存储到文件或者数据库灯地方,肯定不能直接插值的。如果使用 数值表示插值,又会导致难以理解,如:
var prompt = """
用户问题:{0}
"""
string.Format(prompt,request);
Semantic Kernel 中提供了一种模板字符串插值的的办法,这样会给我们编写提示模板带来便利。
Semantic Kernel 语法规定,使用
{{$system}}
来在提示模板中表示一个名为
system
的变量。后续可以使用 KernelArguments 等类型,替换提示模板中的相关变量标识。示例如下:
var kernel = builder.Build();
// 创建提示模板
var chat = kernel.CreateFunctionFromPrompt(
@"
System:{{$system}}
User: {{$request}}
Assistant: ");
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
// 设置变量值
var arguments = new KernelArguments
{
{ "system", "你是一个高级运维专家,对用户的问题给出最专业的回答" },
{ "request", request }
};
// 提问时,传递模板以及变量值。
// 这里使用流式对话
var chatResult = kernel.InvokeStreamingAsync<StreamingChatMessageContent>(chat, arguments);
// 流式回复,避免一直等结果
string message = "";
awaitforeach (var chunk in chatResult)
{
if (chunk.Role.HasValue)
{
Console.Write(chunk.Role + " > ");
}
message += chunk;
Console.Write(chunk);
}
Console.WriteLine();
在这段代码中,演示了如何在提示模板中使用变量标识,以及再向 AI 提问时传递变量值。此外,为了避免一直等带 AI 回复,我们需要使用流式对话
.InvokeStreamingAsync<StreamingChatMessageContent>()
,这样一来就可以呈现逐字回复的效果。
此外,这里不再使用直接使用字符串提问的方法,而是使用
.CreateFunctionFromPrompt()
先从字符串创建提示模板对象。
聊天记录
聊天记录的作用是作为一种上下文信息,给 AI 作为参考,以便完善回复。
示例如下:
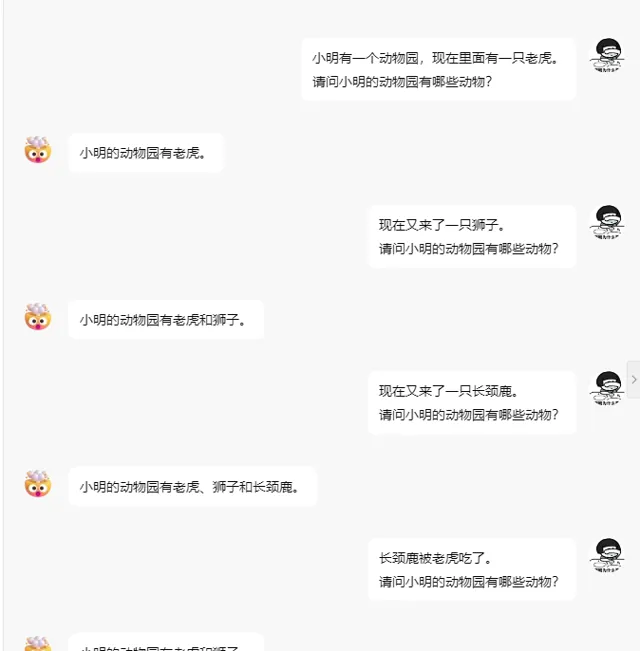
不过,AI 对话使用的是 http 请求,是无状态的,因此不像聊天记录哪里保存会话状态,之所以 AI 能够工具聊天记录进行回答,在于每次请求时,将聊天记录一起发送给 AI ,让 AI 进行学习并对最后的问题进行回复。

下面这句话,还不到 30 个 tokens。
又来了一只猫。
请问小明的动物园有哪些动物?
AI 回复的这句话,怎么也不到 20个 tokens 吧。
小明的动物园现在有老虎、狮子和猫。
但是一看 one-api 后台,发现每次对话消耗的 tokens 越来越大。
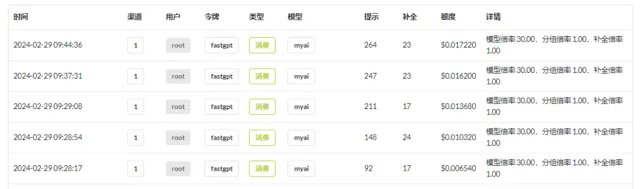
这是因为为了实现聊天的功能,使用了一种很笨的方法。虽然 AI 不会保存聊天记录,但是客户端可以保存,然后下次提问时,将将聊天记录都一起带上去。不过这样会导致 tokens 越来越大!
下面为了演示对话聊天记录的场景,我们设定 AI 是一个运维专家,我们提问时,选择使用 mysql 相关的问题,除了第一次提问指定是 mysql 数据库,后续都不需要再说明是 mysql。
var kernel = builder.Build();
var chat = kernel.CreateFunctionFromPrompt(
@"
System:你是一个高级运维专家,对用户的问题给出最专业的回答。
{{$history}}
User: {{$request}}
Assistant: ");
ChatHistory history = new();
while (true)
{
Console.WriteLine("请输入你的问题:");
// 用户问题
var request = Console.ReadLine();
var chatResult = kernel.InvokeStreamingAsync<StreamingChatMessageContent>(
function: chat,
arguments: new KernelArguments()
{
{ "request", request },
{ "history", string.Join("\n", history.Select(x => x.Role + ": " + x.Content)) }
}
);
// 流式回复,避免一直等结果
string message = "";
awaitforeach (var chunk in chatResult)
{
if (chunk.Role.HasValue)
{
Console.Write(chunk.Role + " > ");
}
message += chunk;
Console.Write(chunk);
}
Console.WriteLine();
// 添加用户问题和机器人回复到历史记录中
history.AddUserMessage(request!);
history.AddAssistantMessage(message);
}
这段代码有两个地方要说明,第一个是如何存储聊天记录。Semantic Kernel 提供了 ChatHistory 存储聊天记录,当然我们手动存储到字符串、数据库中也是一样的。
// 添加用户问题和机器人回复到历史记录中
history.AddUserMessage(request!);
history.AddAssistantMessage(message);
但是 ChatHistory 对象不能直接给 AI 使用。所以需要自己从 ChatHistory 中读取聊天记录后,生成字符串,替换提示模板中的
{{$history}}
。
new KernelArguments()
{
{ "request", request },
{ "history", string.Join("\n", history.Select(x => x.Role + ": " + x.Content)) }
}
生成聊天记录时,需要使用角色名称区分。比如生成:
User: mysql 怎么查看表数量
Assistant:......
User: 查看数据库数量
Assistant:...
历史记录还能通过手动创建
ChatMessageContent
对象的方式添加到 ChatHistory 中:
List<ChatHistory> fewShotExamples =
[
new ChatHistory()
{
new ChatMessageContent(AuthorRole.User, "Can you send a very quick approval to the marketing team?"),
new ChatMessageContent(AuthorRole.System, "Intent:"),
new ChatMessageContent(AuthorRole.Assistant, "ContinueConversation")
},
new ChatHistory()
{
new ChatMessageContent(AuthorRole.User, "Thanks, I'm done for now"),
new ChatMessageContent(AuthorRole.System, "Intent:"),
new ChatMessageContent(AuthorRole.Assistant, "EndConversation")
}
];
手动拼接聊天记录太麻烦了,我们可以使用 IChatCompletionService 服务更好的处理聊天对话。
使用 IChatCompletionService 之后,实现聊天对话的代码变得更加简洁了:
var history = new ChatHistory();
history.AddSystemMessage("你是一个高级数学专家,对用户的问题给出最专业的回答。");
// 聊天服务
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
while (true)
{
Console.Write("请输入你的问题:");
var userInput = Console.ReadLine();
// 添加到聊天记录中
history.AddUserMessage(userInput);
// 获取 AI 聊天回复信息
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
kernel: kernel);
Console.WriteLine("AI 回复 :" + result);
// 添加 AI 的回复到聊天记录中
history.AddMessage(result.Role, result.Content ?? string.Empty);
}
请输入你的问题:1加上1等于
AI 回复 :1加上1等于2
请输入你的问题:再加上50
AI 回复 :1加上1再加上50等于52。
请输入你的问题:再加上200
AI 回复 :1加上1再加上50再加上200等于252。
函数和插件
在高层次上,插件是一组可以公开给 AI 应用程序和服务的函数。然后,AI 应用程序可以对插件中的功能进行编排,以完成用户请求。在语义内核中,您可以通过函数调用或规划器手动或自动地调用这些函数。
直接调用插件函数
Semantic Kernel 可以直接加载本地类型中的函数,这一过程不需要经过 AI,完全在本地完成。
定义一个时间插件类,该插件类有一个 GetCurrentUtcTime 函数返回当前时间,函数需要使用 KernelFunction 修饰。
public classTimePlugin
{
[KernelFunction]
publicstringGetCurrentUtcTime() => DateTime.UtcNow.ToString("R");
}
加载插件并调用插件函数:
// 加载插件
builder.Plugins.AddFromType<TimePlugin>();
var kernel = builder.Build();
FunctionResult result = await kernel.InvokeAsync("TimePlugin", "GetCurrentUtcTime");
Console.WriteLine(result.GetValue<string>());
输出:
Tue,27Feb2024 11:07:59 GMT
当然,这个示例在实际开发中可能没什么用,不过大家要理解在 Semantic Kernel 是怎样调用一个函数的。
提示模板文件
Semantic Kernel 很多地方都跟 Function 相关,你会发现代码中很多代码是以 Function 作为命名的。
比如提供字符串创建提示模板:
KernelFunction chat = kernel.CreateFunctionFromPrompt(
@"
System:你是一个高级运维专家,对用户的问题给出最专业的回答。
{{$history}}
User: {{$request}}
Assistant: ");
然后回到本节的主题,Semantic Kernel 还可以将提示模板存储到文件中,然后以插件的形式加载模板文件。
比如有以下目录文件:
└─WriterPlugin
└─ShortPoem
config.json
skprompt.txt
skprompt.txt 文件是固定命名,存储提示模板文本,示例如下:
根据主题写一首有趣的短诗或打油诗,要有创意,要有趣,放开你的想象力。
主题: {{$input}}
config.json 文件是固定名称,存储描述信息,比如需要的变量名称、描述等。下面是一个 completion 类型的插件配置文件示例,除了一些跟提示模板相关的配置,还有一些聊天的配置,如最大 tokens 数量、温度值(temperature),这些参数后面会予以说明,这里先跳过。
{
"schema": 1,
"type": "completion",
"description": "根据用户问题写一首简短而有趣的诗.",
"completion": {
"max_tokens": 200,
"temperature": 0.5,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "input",
"description": "诗的主题",
"defaultValue": ""
}
]
}
}
创建插件目录和文件后,在代码中以提示模板的方式加载:
// 加载插件,表示该插件是提示模板
builder.Plugins.AddFromPromptDirectory("./plugins/WriterPlugin");
var kernel = builder.Build();
Console.WriteLine("输入诗的主题:");
var input = Console.ReadLine();
// WriterPlugin 插件名称,与插件目录一致,插件目录下可以有多个子模板目录。
FunctionResult result = await kernel.InvokeAsync("WriterPlugin", "ShortPoem", new() {
{ "input", input }
});
Console.WriteLine(result.GetValue<string>());
输入问题以及 AI 回复:
输入诗的主题:
春天
春天,春天,你是生命的诗篇,
万物复苏,爱的季节。
郁郁葱葱的小草中,
是你轻响的诗人的脚步音。
春天,春天,你是花芯的深渊,
桃红柳绿,或妩媚或清纯。
在温暖的微风中,
是你舞动的裙摆。
春天,春天,你是蓝空的情儿,
百鸟鸣叫,放歌天际无边。
在你湛蓝的天幕下,
是你独角戏的绚烂瞬间。
春天,春天,你是河流的眼睛,
如阿瞒甘霖,滋养大地生灵。
你的涓涓细流,
是你悠悠的歌声。
春天,春天,你是生命的诗篇,
用温暖的手指,照亮这灰色的世间。
你的绽放,微笑与欢欣,
就是我心中永恒的春天。
插件文件的编写可参考官方文档:https://learn.microsoft.com/en-us/semantic-kernel/prompts/saving-prompts-as-files?tabs=Csharp
根据 AI 自动调用插件函数
使用 Semantic Kernel 加载插件类后,Semantic Kernel 可以自动根据 AI 对话调用这些插件类中的函数。
比如有一个插件类型,用于修改或获取灯的状态。
代码如下:
public classLightPlugin
{
publicbool IsOn { get; set; } = false;
[KernelFunction]
[Description("获取灯的状态.")]
publicstringGetState() => IsOn ? "亮" : "暗";
[KernelFunction]
[Description("修改灯的状态.'")]
publicstringChangeState(bool newState)
{
this.IsOn = newState;
var state = GetState();
Console.WriteLine($"[灯的状态是:{state}]");
return state;
}
}
每个函数都使用了
[Description]
特性设置了注释信息,这些注释信息非常重要,AI 靠这些注释理解函数的功能作用。
然后加载插件类,并在聊天中被 Semantic Kernel 调用:
// 加载插件类
builder.Plugins.AddFromType<LightPlugin>();
var kernel = builder.Build();
var history = new ChatHistory();
// 聊天服务
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
while (true)
{
Console.Write("User > ");
var userInput = Console.ReadLine();
// 添加到聊天记录中
history.AddUserMessage(userInput);
// 开启函数调用
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
};
// 获取函数
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
Console.WriteLine("Assistant > " + result);
// 添加到聊天记录中
history.AddMessage(result.Role, result.Content ?? string.Empty);
}
可以先断点调试 LightPlugin 中的函数,然后在控制台输入问题让 AI 调用本地函数:
User> 灯的状态
Assistant > 当前灯的状态是暗的。
User> 开灯
[灯的状态是:亮]
Assistant > 灯已经开启,现在是亮的状态。
User> 关灯
[灯的状态是:暗]
读者可以在官方文档了解更多:https://learn.microsoft.com/en-us/semantic-kernel/agents/plugins/using-the-kernelfunction-decorator?tabs=Csharp
由于几乎没有文档资料说明原理,因此建议读者去研究源码,这里就不再赘述了。
聊天中明确调用函数
我们可以在提示模板中明确调用一个函数。
定义一个插件类型 ConversationSummaryPlugin,其功能十分简单,将历史记录直接返回,input 参数表示历史记录。
public classConversationSummaryPlugin
{
[KernelFunction, Description("给你一份很长的谈话记录,总结一下谈话内容.")]
publicasync Task<string> SummarizeConversationAsync(
[Description("长对话记录\r\n.")] string input, Kernel kernel)
{
await Task.CompletedTask;
return input;
}
}
为了在聊天记录中使用该插件函数,我们需要在提示模板中使用
{{ConversationSummaryPlugin.SummarizeConversation $history}}
,其中
$history
是自定义的变量名称,名称可以随意,只要是个字符串即可。
var chat = kernel.CreateFunctionFromPrompt(
@"{{ConversationSummaryPlugin.SummarizeConversation $history}}
User: {{$request}}
Assistant: "
);
完整代码如下:
// 加载总结插件
builder.Plugins.AddFromType<ConversationSummaryPlugin>();
var kernel = builder.Build();
var chat = kernel.CreateFunctionFromPrompt(
@"{{ConversationSummaryPlugin.SummarizeConversation $history}}
User: {{$request}}
Assistant: "
);
var history = new ChatHistory();
while (true)
{
Console.Write("User > ");
var request = Console.ReadLine();
// 添加到聊天记录中
history.AddUserMessage(request);
// 流式对话
var chatResult = kernel.InvokeStreamingAsync<StreamingChatMessageContent>(
chat, new KernelArguments
{
{ "request", request },
{ "history", string.Join("\n", history.Select(x => x.Role + ": " + x.Content)) }
});
string message = "";
awaitforeach (var chunk in chatResult)
{
if (chunk.Role.HasValue)
{
Console.Write(chunk.Role + " > ");
}
message += chunk;
Console.Write(chunk);
}
Console.WriteLine();
history.AddAssistantMessage(message);
}
由于模板的开头是
{{ConversationSummaryPlugin.SummarizeConversation $history}}
,因此,每次聊天之前,都会先调用该函数。
比如输入
吃饭睡觉打豆豆
的时候,首先执行 ConversationSummaryPlugin.SummarizeConversation 函数,然后将返回结果存储到模板中。
最后生成的提示词对比如下:
@"{{ConversationSummaryPlugin.SummarizeConversation $history}}
User: {{$request}}
Assistant: "
user:吃饭睡觉打豆豆
User:吃饭睡觉打豆豆
Assistant:
可以看到,调用函数返回结果后,提示词字符串前面自动使用 User 角色。
实现总结
Semantic Kernel 中有很多文本处理工具,比如
TextChunker
类型,可以帮助我们提取文本中的行、段。设定场景如下,用户提问一大段文本,然后我们使用 AI 总结这段文本。
Semantic Kernel 有一些工具,但是不多,而且是针对英文开发的。
设定一个场景,用户可以每行输入一句话,当用户使用
000
结束输入后,每句话都推送给 AI 总结(不是全部放在一起总结)。
这个示例的代码比较长,建议读者在 vs 中调试代码,慢慢阅读。
// 总结内容的最大 token
constint MaxTokens = 1024;
// 提示模板
conststring SummarizeConversationDefinition =
@"开始内容总结:
{{$request}}
最后对内容进行总结。
在「内容到总结」中总结对话,找出讨论的要点和得出的任何结论。
不要加入其他常识。
摘要是纯文本形式,在完整的句子中,没有标记或标记。
开始总结:
";
// 配置
PromptExecutionSettings promptExecutionSettings = new()
{
ExtensionData = new Dictionary<string, object>()
{
{ "Temperature", 0.1 },
{ "TopP", 0.5 },
{ "MaxTokens", MaxTokens }
}
};
// 这里不使用 kernel.CreateFunctionFromPrompt 了
// KernelFunctionFactory 可以帮助我们通过代码的方式配置提示词
var func = KernelFunctionFactory.CreateFromPrompt(
SummarizeConversationDefinition, // 提示词
description: "给出一段对话记录,总结这部分对话.", // 描述
executionSettings: promptExecutionSettings); // 配置
#pragmawarning disable SKEXP0055 // 类型仅用于评估,在将来的更新中可能会被更改或删除。取消此诊断以继续。
var request = "";
while (true)
{
Console.Write("User > ");
var input = Console.ReadLine();
if (input == "000")
{
break;
}
request += Environment.NewLine;
request += input;
}
// SK 提供的文本拆分器,将文本分成一行行的
List<string> lines = TextChunker.SplitPlainTextLines(request, MaxTokens);
// 将文本拆成段落
List<string> paragraphs = TextChunker.SplitPlainTextParagraphs(lines, MaxTokens);
string[] results = newstring[paragraphs.Count];
for (int i = 0; i < results.Length; i++)
{
// 一段段地总结
results[i] = (await func.InvokeAsync(kernel, new() { ["request"] = paragraphs[i] }).ConfigureAwait(false))
.GetValue<string>() ?? string.Empty;
}
Console.WriteLine($"""
总结如下:
{string.Join("\n", results)}
""");
输入一堆内容后,新的一行使用
000
结束提问,让 AI 总结用户的话。
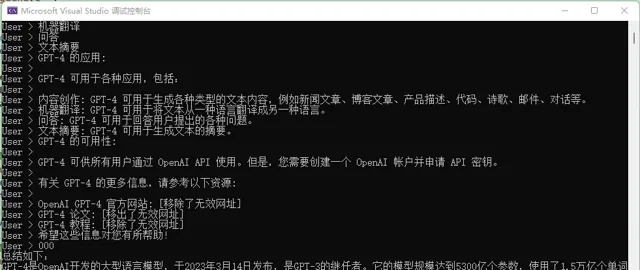
不过经过调试发现,TextChunker 对这段文本的处理似乎不佳,因为文本这么多行只识别为一行、一段。
可能跟 TextChunker 分隔符有关,SK 主要是面向英语的。

本小节的演示效果不佳,不过主要目的是,让用户了解
KernelFunctionFactory.CreateFromPrompt
可以更加方便创建提示模板、使用 PromptExecutionSettings 配置温度、使用 TextChunker 切割文本。
配置 PromptExecutionSettings 时,出现了三个参数,其中 MaxTokens 表示机器人回复最大的 tokens 数量,这样可以避免机器人废话太多。
其它两个参数的作用是:
Temperature
:值范围在 0-2 之间,简单来说,
temperature
的参数值越小,模型就会返回越确定的一个结果。值越大,AI 的想象力越强,越可能偏离现实。一般诗歌、科幻这些可以设置大一些,让 AI 实现天马行空的回复。
TopP :与 Temperature 不同的另一种方法,称为核抽样,其中模型考虑了具有 TopP 概率质量的令牌的结果。因此,0.1 意味着只考虑构成前10% 概率质量的令牌的结果。
一般建议是改变其中一个参数就行,不用两个都调整。
更多相关的参数配置,请查看 https://learn.microsoft.com/en-us/azure/ai-services/openai/reference
配置提示词
前面提到了一个新的创建函数的用法:
var func = KernelFunctionFactory.CreateFromPrompt(
SummarizeConversationDefinition, // 提示词
description: "给出一段对话记录,总结这部分对话.", // 描述
executionSettings: promptExecutionSettings); // 配置
创建提示模板时,可以使用 PromptTemplateConfig 类型 调整控制提示符行为的参数。
// 总结内容的最大 token
constint MaxTokens = 1024;
// 提示模板
conststring SummarizeConversationDefinition = "...";
var func = kernel.CreateFunctionFromPrompt(new PromptTemplateConfig
{
// Name 不支持中文和特殊字符
Name = "chat",
Description = "给出一段对话记录,总结这部分对话.",
Template = SummarizeConversationDefinition,
TemplateFormat = "semantic-kernel",
InputVariables = new List<InputVariable>
{
new InputVariable{Name = "request", Description = "用户的问题", IsRequired = true }
},
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = MaxTokens,
Temperature = 0
}
},
}
});
ExecutionSettings 部分的配置,可以针对使用的模型起效,这里的配置不会全部同时起效,会根据实际使用的模型起效。
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = 1000,
Temperature = 0
}
},
{
"gpt-3.5-turbo", new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-3.5-turbo-0613",
MaxTokens = 4000,
Temperature = 0.2
}
},
{
"gpt-4",
new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-4-1106-preview",
MaxTokens = 8000,
Temperature = 0.3
}
}
}
聊到这里,重新说一下前面使用文件配置提示模板文件的,两者是相似的。
我们也可以使用文件的形式存储与代码一致的配置,其目录文件结构如下:
└─── chat
|
└─── config.json
└─── skprompt.txt
模板文件由 config.json 和 skprompt.txt 组成,skprompt.txt 中配置提示词,跟 PromptTemplateConfig 的 Template 字段配置一致。
config.json 中涉及的内容比较多,你可以对照下面的 json 跟 实现总结 一节的代码,两者几乎是一模一样的。
{
"schema": 1,
"type": "completion",
"description": "给出一段对话记录,总结这部分对话",
"execution_settings": {
"default": {
"max_tokens": 1000,
"temperature": 0
},
"gpt-3.5-turbo": {
"model_id": "gpt-3.5-turbo-0613",
"max_tokens": 4000,
"temperature": 0.1
},
"gpt-4": {
"model_id": "gpt-4-1106-preview",
"max_tokens": 8000,
"temperature": 0.3
}
},
"input_variables": [
{
"name": "request",
"description": "用户的问题.",
"required": true
},
{
"name": "history",
"description": "用户的问题.",
"required": true
}
]
}
C# 代码:
// Name 不支持中文和特殊字符
Name = "chat",
Description = "给出一段对话记录,总结这部分对话.",
Template = SummarizeConversationDefinition,
TemplateFormat = "semantic-kernel",
InputVariables = new List<InputVariable>
{
new InputVariable{Name = "request", Description = "用户的问题", IsRequired = true }
},
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = 1000,
Temperature = 0
}
},
{
"gpt-3.5-turbo", new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-3.5-turbo-0613",
MaxTokens = 4000,
Temperature = 0.2
}
},
{
"gpt-4",
new OpenAIPromptExecutionSettings()
{
ModelId = "gpt-4-1106-preview",
MaxTokens = 8000,
Temperature = 0.3
}
}
}
提示模板语法
目前,我们已经有两个地方使用到提示模板的语法,即变量和函数调用,因为前面已经介绍过相关的用法,因此这里再简单提及一下。
变量
变量的使用很简单,在提示工程中使用
{{$变量名称}}
标识即可,如
{{$name}}
。
然后在对话中有多种方法插入值,如使用 KernelArguments 存储变量值:
new KernelArguments
{
{ "name", "工良" }
});
函数调用
在 实现总结 一节提到过,在提示模板中可以明确调用一个函数,比如定义一个函数如下:
// 没有 Kernel kernel
[KernelFunction, Description("给你一份很长的谈话记录,总结一下谈话内容.")]
publicasync Task<string> SummarizeConversationAsync(
[Description("长对话记录\r\n.")] string input)
{
await Task.CompletedTask;
return input;
}
// 有 Kernel kernel
[KernelFunction, Description("给你一份很长的谈话记录,总结一下谈话内容.")]
publicasync Task<string> SummarizeConversationAsync(
[Description("长对话记录\r\n.")] string input, Kernel kernel)
{
await Task.CompletedTask;
return input;
}
[KernelFunction]
[Description("Sends an email to a recipient.")]
publicasync Task SendEmailAsync(
Kernel kernel,
string recipientEmails,
string subject,
string body
)
{
// Add logic to send an email using the recipientEmails, subject, and body
// For now, we'll just print out a success message to the console
Console.WriteLine("Email sent!");
}
函数一定需要使用
[KernelFunction]
标识,
[Description]
描述函数的作用。函数可以一个或多个参数,每个参数最好都使用
[Description]
描述作用。
函数参数中,可以带一个
Kernel kernel
,可以放到开头或末尾 ,也可以不带,主要作用是注入
Kernel
对象。
在 prompt 中使用函数时,需要传递函数参数:
总结如下:{{AAA.SummarizeConversationAsync $input}}.
其它一些特殊字符的转义方法等,详见官方文档:https://learn.microsoft.com/en-us/semantic-kernel/prompts/prompt-template-syntax
文本生成
前面劈里啪啦写了一堆东西,都是说聊天对话的,本节来聊一下文本生成的应用。
文本生成和聊天对话模型主要有以下模型:
| Model type | Model |
|---|---|
| Text generation | text-ada-001 |
| Text generation | text-babbage-001 |
| Text generation | text-curie-001 |
| Text generation | text-davinci-001 |
| Text generation | text-davinci-002 |
| Text generation | text-davinci-003 |
| Chat Completion | gpt-3.5-turbo |
| Chat Completion | gpt-4 |
当然,文本生成不一定只能用这么几个模型,使用 gpt-4 设定好背景提示,也可以达到相应效果。
文本生成可以有以下场景:
使用文本生成的示例如下,让 AI 总结文本:
按照这个示例,我们先在 Env.cs 中编写扩展函数,配置使用
.AddAzureOpenAITextGeneration()
文本生成,而不是聊天对话。
publicstatic IKernelBuilder WithAzureOpenAIText(this IKernelBuilder builder)
{
var configuration = GetConfiguration();
// 需要换一个模型,比如 gpt-35-turbo-instruct
var AzureOpenAIDeploymentName = "ca";
var AzureOpenAIModelId = "gpt-35-turbo-instruct";
var AzureOpenAIEndpoint = configuration["AzureOpenAI:Endpoint"]!;
var AzureOpenAIApiKey = configuration["AzureOpenAI:ApiKey"]!;
builder.Services.AddLogging(c =>
{
c.AddDebug()
.SetMinimumLevel(LogLevel.Trace)
.AddSimpleConsole(options =>
{
options.IncludeScopes = true;
options.SingleLine = true;
options.TimestampFormat = "yyyy-MM-dd HH:mm:ss ";
});
});
// 使用 Chat ,即大语言模型聊天
builder.Services.AddAzureOpenAITextGeneration(
AzureOpenAIDeploymentName,
AzureOpenAIEndpoint,
AzureOpenAIApiKey,
modelId: AzureOpenAIModelId
);
return builder;
}
然后编写提问代码,用户可以多行输入文本,最后使用
000
结束输入,将文本提交给 AI 进行总结。进行总结时,为了避免 AI 废话太多,因此这里使用
ExecutionSettings
配置相关参数。
代码示例如下:
builder = builder.WithAzureOpenAIText();
var kernel = builder.Build();
Console.WriteLine("输入文本:");
var request = "";
while (true)
{
var input = Console.ReadLine();
if (input == "000")
{
break;
}
request += Environment.NewLine;
request += input;
}
var func = kernel.CreateFunctionFromPrompt(new PromptTemplateConfig
{
Name = "chat",
Description = "给出一段对话记录,总结这部分对话.",
// 用户的文本
Template = request,
TemplateFormat = "semantic-kernel",
ExecutionSettings = new Dictionary<string, PromptExecutionSettings>
{
{
"default",
new OpenAIPromptExecutionSettings()
{
MaxTokens = 100,
Temperature = (float)0.3,
TopP = (float)1,
FrequencyPenalty = (float)0,
PresencePenalty = (float)0
}
}
}
});
var result = await func.InvokeAsync(kernel);
Console.WriteLine($"""
总结如下:
{string.Join("\n", result)}
""");
Semantic Kernel 插件
Semantic Kernel 在 Microsoft.SemanticKernel.Plugins 开头的包中提供了一些插件,不同的包有不同功能的插件。大部分目前还是属于半成品,因此这部分不详细讲解,本节只做简单说明。
目前官方仓库有以下包提供了一些插件:
├─Plugins.Core
├─Plugins.Document
├─Plugins.Memory
├─Plugins.MsGraph
└─Plugins.Web
nuget 搜索时,需要加上
Microsoft.SemanticKernel.
前缀。
Semantic Kernel 还有通过远程 swagger.json 使用插件的做法,详细请参考文档:https://learn.microsoft.com/en-us/semantic-kernel/agents/plugins/openai-plugins
Plugins.Core 中包含最基础简单的插件:
// 读取和写入文件
FileIOPlugin
// http 请求以及返回字符串结果
HttpPlugin
// 只提供了 + 和 - 两种运算
MathPlugin
// 文本大小写等简单的功能
TextPlugin
// 获得本地时间日期
TimePlugin
// 在操作之前等待一段时间
WaitPlugin
因为这些插件对本文演示没什么帮助,功能也非常简单,因此这里不讲解。下面简单讲一下文档插件。
文档插件
安装 Microsoft.SemanticKernel.Plugins.Document(需要勾选预览版),里面包含了文档插件,该文档插件使用了 DocumentFormat.OpenXml 项目,DocumentFormat.OpenXml 支持以下文档格式:
DocumentFormat.OpenXml 项目地址 https://github.com/dotnet/Open-XML-SDK
WordprocessingML :用于创建和编辑 Word 文档 (.docx)
SpreadsheetML :用于创建和编辑 Excel 电子表格 (.xlsx)
PowerPointML :用于创建和编辑 PowerPoint 演示文稿 (.pptx)
VisioML :用于创建和编辑 Visio 图表 (.vsdx)
ProjectML :用于创建和编辑 Project 项目 (.mpp)
DiagramML :用于创建和编辑 Visio 图表 (.vsdx)
PublisherML :用于创建和编辑 Publisher 出版物 (.pubx)
InfoPathML :用于创建和编辑 InfoPath 表单 (.xsn)
文档插件暂时还没有好的应用场景,只是加载文档提取文字比较方便,代码示例如下:
DocumentPlugin documentPlugin = new(new WordDocumentConnector(), new LocalFileSystemConnector());
string filePath = "(完整版)基础财务知识.docx";
string text = await documentPlugin.ReadTextAsync(filePath);
Console.WriteLine(text);
由于这些插件目前都是半成品,因此这里就不展开说明了。
planners
依然是半成品,这里就不再赘述。
因为我也没有看明白这个东西怎么用 。
Kernel Memory 构建文档知识库
Kernel Memory 是一个歪果仁的个人项目,支持 PDF 和 Word 文档、 PowerPoint 演示文稿、图像、电子表格等,通过利用大型语言模型(llm)、嵌入和矢量存储来提取信息和生成记录,主要目的是提供文档处理相关的接口,最常使用的场景是知识库系统。读者可能对知识库系统不了解,如果有条件,建议部署一个 Fastgpt 系统研究一下。
但是目前 Kernel Memory 依然是半产品,文档也不完善,所以接下来笔者也只讲解最核心的部分,感兴趣的读者建议直接看源码。
Kernel Memory 项目文档:https://microsoft.github.io/kernel-memory/
Kernel Memory 项目仓库:https://github.com/microsoft/kernel-memory
打开 Kernel Memory 项目仓库,将项目拉取到本地。
要讲解知识库系统,可以这样理解。大家都知道,训练一个医学模型是十分麻烦的,别说机器的 GPU 够不够猛,光是训练 AI ,就需要掌握各种专业的知识。如果出现一个新的需求,可能又要重新训练一个模型,这样太麻烦了。
于是出现了大语言模型,特点是什么都学什么都会,但是不够专业深入,好处时无论医学、摄影等都可以使用。
虽然某方面专业的知识不够深入和专业,但是我们换种部分解决。
首先,将 docx、pdf 等问题提取出文本,然后切割成多个段落,每一段都使用 AI 模型生成相关向量,这个向量的原理笔者也不懂,大家可以简单理解为分词,生成向量后,将段落文本和向量都存储到数据库中(数据库需要支持向量)。
然后在用户提问 「什么是报表」 时,首先在数据库中搜索,根据向量来确定相似程度,把几个跟问题相关的段落拿出来,然后把这几段文本和用户的问题一起发给 AI。相对于在提示模板中,塞进一部分背景知识,然后加上用户的问题,再由 AI 进行总结回答。
笔者建议大家有条件的话,部署一个开源版本的 Fastgpt 系统,把这个系统研究一下,学会这个系统后,再去研究 Kernel Memory ,你就会觉得非常简单了。同理,如果有条件,可以先部署一个 LobeHub ,开源的 AI 对话系统,研究怎么用,再去研究 Semantic Kernel 文档,接着再深入源码。
从 web 处理网页
Kernel Memory 支持从网页爬取、导入文档、直接给定字符串三种方式导入信息,由于 Kernel Memory 提供了一个 Service 示例,里面有一些值得研究的代码写法,因此下面的示例是启动 Service 这个 Web 服务,然后在客户端将文档推送该 Service 处理,客户端本身不对接 AI。
由于这一步比较麻烦,读者动手的过程中搞不出来 ,可以直接放弃 , 后面会说怎么自己写一个 。
打开 kernel-memory 源码的
service/Service
路径。
使用命令启动服务:
dotnet run setup
这个控制台的作用是帮助我们生成相关配置的。启动这个控制台之后,根据提示选择对应的选项(按上下键选择选项,按下回车键确认),以及填写配置内容,配置会被存储到 appsettings.Development.json 中。
如果读者搞不懂这个控制台怎么使用,那么可以直接将替换下面的 json 到 appsettings.Development.json 。
有几个地方需要读者配置一下。
AccessKey1、AccessKey2 是客户端使用该 Service 所需要的验证密钥,随便填几个字母即可。
AzureAIDocIntel、AzureOpenAIEmbedding、AzureOpenAIText 根据实际情况填写。
{
"KernelMemory": {
"Service": {
"RunWebService": true,
"RunHandlers": true,
"OpenApiEnabled": true,
"Handlers": {}
},
"ContentStorageType": "SimpleFileStorage",
"TextGeneratorType": "AzureOpenAIText",
"ServiceAuthorization": {
"Enabled": true,
"AuthenticationType": "APIKey",
"HttpHeaderName": "Authorization",
"AccessKey1": "自定义密钥1",
"AccessKey2": "自定义密钥2"
},
"DataIngestion": {
"OrchestrationType": "Distributed",
"DistributedOrchestration": {
"QueueType": "SimpleQueues"
},
"EmbeddingGenerationEnabled": true,
"EmbeddingGeneratorTypes": [
"AzureOpenAIEmbedding"
],
"MemoryDbTypes": [
"SimpleVectorDb"
],
"ImageOcrType": "AzureAIDocIntel",
"TextPartitioning": {
"MaxTokensPerParagraph": 1000,
"MaxTokensPerLine": 300,
"OverlappingTokens": 100
},
"DefaultSteps": []
},
"Retrieval": {
"MemoryDbType": "SimpleVectorDb",
"EmbeddingGeneratorType": "AzureOpenAIEmbedding",
"SearchClient": {
"MaxAskPromptSize": -1,
"MaxMatchesCount": 100,
"AnswerTokens": 300,
"EmptyAnswer": "INFO NOT FOUND"
}
},
"Services": {
"SimpleQueues": {
"Directory": "_tmp_queues"
},
"SimpleFileStorage": {
"Directory": "_tmp_files"
},
"AzureAIDocIntel": {
"Auth": "ApiKey",
"Endpoint": "https://aaa.openai.azure.com/",
"APIKey": "aaa"
},
"AzureOpenAIEmbedding": {
"APIType": "EmbeddingGeneration",
"Auth": "ApiKey",
"Endpoint": "https://aaa.openai.azure.com/",
"Deployment": "aitext",
"APIKey": "aaa"
},
"SimpleVectorDb": {
"Directory": "_tmp_vectors"
},
"AzureOpenAIText": {
"APIType": "ChatCompletion",
"Auth": "ApiKey",
"Endpoint": "https://aaa.openai.azure.com/",
"Deployment": "myai",
"APIKey": "aaa",
"MaxRetries": 10
}
}
},
"Logging": {
"LogLevel": {
"Default": "Warning"
}
},
"AllowedHosts": "*"
}
详细可参考文档: https://microsoft.github.io/kernel-memory/quickstart/configuration
启动 Service 后,可以看到以下 swagger 界面。
然后编写代码连接到知识库系统,推送要处理的网页地址给 Service。创建一个项目,引入 Microsoft.KernelMemory.WebClient 包。
然后按照以下代码将文档推送给 Service 处理。
// 前面部署的 Service 地址,和自定义的密钥。
var memory = new MemoryWebClient(endpoint: "http://localhost:9001/", apiKey: "自定义密钥1");
// 导入网页
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02");
Console.WriteLine("正在处理文档,请稍等...");
// 使用 AI 处理网页知识
while (!await memory.IsDocumentReadyAsync(documentId: "doc02"))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500));
}
// 提问
var answer = await memory.AskAsync("比特币是什么?");
Console.WriteLine($"\nAnswer: {answer.Result}");
此外还有 ImportTextAsync、ImportDocumentAsync 来个导入知识的方法。
手动处理文档
本节内容稍多,主要讲解如何使用 Kernel Memory 从将文档导入、生成向量、存储向量、搜索问题等。
新建项目,安装 Microsoft.KernelMemory.Core 库。
为了便于演示,下面代码将文档和向量临时存储,不使用数据库存储。
全部代码示例如下:
using Microsoft.KernelMemory;
using Microsoft.KernelMemory.MemoryStorage.DevTools;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
var memory = new KernelMemoryBuilder()
// 文档解析后的向量存储位置,可以选择 Postgres 等,
// 这里选择使用本地临时文件存储向量
.WithSimpleVectorDb(new SimpleVectorDbConfig
{
Directory = "aaa"
})
// 配置文档解析向量模型
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aitext",
Endpoint = "https://aaa.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = "aaa"
})
// 配置文本生成模型
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "myai",
Endpoint = "https://aaa.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIKey = "aaa",
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})
.Build();
// 导入网页
await memory.ImportWebPageAsync(
"https://baike.baidu.com/item/比特币挖矿机/12536531",
documentId: "doc02");
// Wait for ingestion to complete, usually 1-2 seconds
Console.WriteLine("正在处理文档,请稍等...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02"))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500));
}
// Ask a question
var answer = await memory.AskAsync("比特币是什么?");
Console.WriteLine($"\nAnswer: {answer.Result}");
首先使用 KernelMemoryBuilder 构建配置,配置的内容比较多,这里会使用到两个模型,一个是向量模型,一个是文本生成模型(可以使用对话模型,如 gpt-4-32k)。
接下来,按照该程序的工作流程讲解各个环节的相关知识。
首先是讲解将文件存储到哪里,也就是导入文件之后,将文件存储到哪里,存储文件的接口是 IContentStorage,目前有两个实现:
AzureBlobsStorage
// 存储到目录
SimpleFileStorage
使用方法:
var memory = new KernelMemoryBuilder()
.WithSimpleFileStorage(new SimpleFileStorageConfig
{
Directory = "aaa"
})
.WithAzureBlobsStorage(new AzureBlobsConfig
{
Account = ""
})
...
Kernel Memory 还不支持 Mongodb,不过可以自己使用 IContentStorage 接口写一个。
本地解析文档后,会进行分段,如右边的
q
列所示。
接着是,配置文档生成向量模型,导入文件文档后,在本地提取出文本,需要使用 AI 模型从文本中生成向量。
解析后的向量是这样的:
将文本生成向量,需要使用 ITextEmbeddingGenerator 接口,目前有两个实现:
AzureOpenAITextEmbeddingGenerator
OpenAITextEmbeddingGenerator
示例:
var memory = new KernelMemoryBuilder()
// 配置文档解析向量模型
.WithAzureOpenAITextEmbeddingGeneration(new AzureOpenAIConfig
{
Deployment = "aitext",
Endpoint = "https://xxx.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIType = AzureOpenAIConfig.APITypes.EmbeddingGeneration,
APIKey = "xxx"
})
.WithOpenAITextEmbeddingGeneration(new OpenAIConfig
{
... ...
})
生成向量后,需要存储这些向量,需要实现 IMemoryDb 接口,有以下配置可以使用:
// 文档解析后的向量存储位置,可以选择 Postgres 等,
// 这里选择使用本地临时文件存储向量
.WithSimpleVectorDb(new SimpleVectorDbConfig
{
Directory = "aaa"
})
.WithAzureAISearchMemoryDb(new AzureAISearchConfig
{
})
.WithPostgresMemoryDb(new PostgresConfig
{
})
.WithQdrantMemoryDb(new QdrantConfig
{
})
.WithRedisMemoryDb("host=....")
当用户提问时,首先会在这里的 IMemoryDb 调用相关方法查询文档中的向量、索引等,查找出相关的文本。
查出相关的文本后,需要发送给 AI 处理,需要使用 ITextGenerator 接口,目前有两个实现:
AzureOpenAITextGenerator
OpenAITextGenerator
配置示例:
// 配置文本生成模型
.WithAzureOpenAITextGeneration(new AzureOpenAIConfig
{
Deployment = "myai",
Endpoint = "https://aaa.openai.azure.com/",
Auth = AzureOpenAIConfig.AuthTypes.APIKey,
APIKey = "aaa",
APIType = AzureOpenAIConfig.APITypes.ChatCompletion
})
导入文档时,首先将文档提取出文本,然后进行分段。
将每一段文本使用向量模型解析出向量,存储到 IMemoryDb 接口提供的服务中,如 Postgres数据库。
提问问题或搜索内容时,从 IMemoryDb 所在的位置搜索向量,查询到相关的文本,然后将文本收集起来,发送给 AI(使用文本生成模型),这些文本相对于提示词,然后 AI 从这些提示词中学习并回答用户的问题。
详细源码可以参考 Microsoft.KernelMemory.Search.SearchClient ,由于源码比较多,这里就不赘述了。
这样说,大家可能不太容易理解,我们可以用下面的代码做示范。
// 导入文档
await memory.ImportDocumentAsync(
"aaa/(完整版)基础财务知识.docx",
documentId: "doc02");
Console.WriteLine("正在处理文档,请稍等...");
while (!await memory.IsDocumentReadyAsync(documentId: "doc02"))
{
await Task.Delay(TimeSpan.FromMilliseconds(1500));
}
var answer1 = await memory.SearchAsync("报表怎么做?");
// 每个 Citation 表示一个文档文件
foreach (Citation citation in answer1.Results)
{
// 与搜索关键词相关的文本
foreach(var partition in citation.Partitions)
{
Console.WriteLine(partition.Text);
}
}
var answer2 = await memory.AskAsync("报表怎么做?");
Console.WriteLine($"\nAnswer: {answer2.Result}");
读者可以在 foreach 这里做个断点,当用户问题 「报表怎么做?」 时,搜索出来的相关文档。
然后再参考 Fastgpt 的搜索配置,可以自己写一个这样的知识库系统。
本期模特:咕咕











