微软亚洲研究院昨天发了一个帖子,论文看了,但又没有完全看懂(流下了缺乏知识的泪水),感觉是个特别牛逼的东西,这是一种新的1-bit大语言模型(LLM)BitNet b1.58,到底牛逼在哪儿呢?我们一起探讨吧,看下回能不能在亚研院请个同事来给大家再解释一下。
与传统的FP16 LLM相比,BitNet b1.58在速度、内存使用、能耗等方面具有显著优势,同时在语言模型困惑度和下游任务性能方面能够与之媲美。
等一下,FP16 LLM是啥来着,FP16也叫做 float16,全称是Half-precision floating-point(半精度浮点数),具体是啥…反正我们就说FP16大模型一开始就是想让大模型瘦身,能用在更小的设备上,比如你在英伟达4090显卡的电脑上跑个30亿参数的大模型是不是好慢?FP16 LLM可以让Flash的速度快上个几倍。
但是,BitNet b1.58一上来就整了个开创性的开局,将FP16这种慢吞吞瘦身而且有极限的办法抛弃了,它将每个参数表示为三进制(-1, 0, 1),而不是传统的二进制(0, 1)。然后你的大模型就突然:
1.速度kuchakucha地变快:BitNet b1.58的推理速度比FP16 LLM快2-4倍,这主要得益于它在矩阵乘法操作中只需要整数加法,而不需要浮点数乘法或加法。
2.内存使用更少:BitNet b1.58的参数只需要1.58位来表示,因此与FP16 LLM相比,其内存占用减少了3-4倍。
3.能耗更低:BitNet b1.58的能耗比FP16 LLM低70倍以上,这使得它更加适合在移动设备和物联网等资源受限的设备上部署。
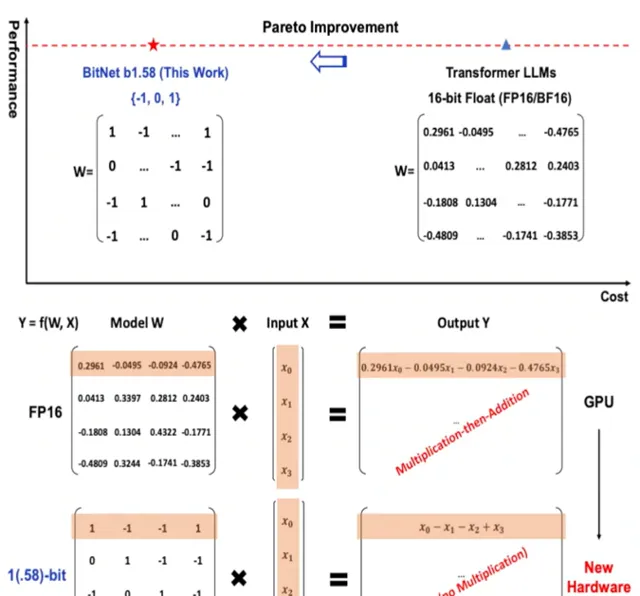
你等一等,三进制,三进制,这...是那个前苏联搞出来的三进制么?是的,就是那个1958年前苏联计算机用的三进制,你别说,因为二进制现在看起来边际收益越来越窄的情况下,什么量子信号传输、半导体、光子计算机都开始三进制的研究和使用了。那在这个场景下为啥从二进制变成三进制有好处呢?
1. 大幅降低了模型的存储和计算成本
传统的二进制 LLM 使用 0 和 1 两种状态来表示每个参数,因此每个参数需要 1 位存储空间。而三进制 LLM 使用 -1、0 和 1 三种状态来表示每个参数,因此每个参数只需要 1.58 位存储空间。
此外,三进制 LLM 在矩阵乘法操作中只需要整数加法,而不需要浮点数乘法或加法。这使得三进制 LLM 的计算速度比二进制 LLM 快得多。
2. 提高了模型的性能
三进制 LLM 可以表示更丰富的参数值,这使得它能够更好地拟合训练数据,从而提高模型的性能。
3. 开辟了新的研究方向
三进制 LLM 的出现为大语言模型的未来发展开辟了新的研究方向。例如,研究人员可以探索如何使用三进制 LLM 来训练更加复杂和强大的模型。
你再稍等等,三进制LLM每个参数需要 1.58 位存储空间那不是比二进制需要的存储空间更大么,这是怎么就是好处了?
说得没错,在论文中提到的三进制 LLM ,每个参数需要 1.58 位存储空间,确实比二进制 LLM 需要的 1 位存储空间要大。
但这并不意味着这是一个坏处。实际上,三进制 LLM 在存储空间方面仍然具有优势,主要体现在以下几个方面:
1. 存储空间的节省并非线性关系
虽然每个参数需要 1.58 位存储空间,但由于三进制 LLM 可以表示更丰富的参数值,因此它可以更好地拟合训练数据,从而提高模型的性能。在很多情况下,三进制 LLM 可以使用更少的参数来达到与二进制 LLM 相同的性能。
2. 计算速度的提升
三进制 LLM 在矩阵乘法操作中只需要整数加法,而不需要浮点数乘法或加法。这使得三进制 LLM 的计算速度比二进制 LLM 快得多。
3. 能耗的降低
由于计算速度的提升,三进制 LLM 的能耗也比二进制 LLM 低得多。
所以 BitNet b1.58 的出现,为大语言模型的未来发展开辟了新的道路。它有可能使大语言模型更加普及,并应用于更广泛的领域。
以下是一些具体的应用场景:
移动设备 :BitNet b1.58可以使手机、平板电脑或者车总可以吧等移动设备上运行更加复杂的大语言模型,从而提供更加丰富的用户体验。
物联网 :BitNet b1.58可以使智能家居、可穿戴设备等物联网设备具备更强大的语言理解能力,从而实现更加智能化的交互。
云计算 :BitNet b1.58可以帮助云服务提供商降低大语言模型的部署和运营成本,从而为用户提供更加经济实惠的服务。

当然, BitNet b1.58 也还存在一些需要改进的地方,比如:
1. 模型容量 :目前BitNet b1.58的最大模型容量为70B参数,而FP16 LLM已经可以达到1.5T参数。
2. 训练难度 :BitNet b1.58的训练过程比FP16 LLM更加复杂,需要更多的计算资源和时间。
BitNet b1.58
是一项具有突破性的研究成果,它为大语言模型的未来发展开辟了新的方向。要知道,这货被提出到突飞猛进一共也才用了五个月不到,照此势头发展下去,大模型在端设备上跑起来看起来就不远了啊。
想知道智用人工智能应用研究院还在做啥么?下面这个二维码备上。












