点击上方蓝字关注我们
❝
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用。Segment Anything Model(SAM)是一个基于Transformer的深度学习模型,主要应用于图像分割领域。在本文中,我们将演示如何在C#中使用OpenVINO™部署 Segment Anything Model 实现任意目标分割。
OpenVINO™ C# API项目链接:
https://github.com/guojin-yan/OpenVINO-CSharp-API.git
使用 OpenVINO™ C# API 部署 Segment Anything Model 全部源码:
https://github.com/guojin-yan/segment-anything-csharp/blob/master/src/segment_anything_openvino/Program.cs
1. 前言
1.1 OpenVINO™ C# API
英特尔发行版 OpenVINO™ 工具套件基于 oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO™ 可赋能开发者在现实世界中部署高性能应用程序和算法。
2024年4月25日,英特尔发布了开源 OpenVINO™ 2024.1 工具包,用于在各种硬件上优化和部署人工智能推理。更新了更多的 Gen AI 覆盖范围和框架集成,以最大限度地减少代码更改。同时提供了更广泛的 LLM 模型支持和更多的模型压缩技术。通过压缩嵌入的额外优化减少了 LLM 编译时间,改进了采用英特尔®高级矩阵扩展 (Intel® AMX) 的第 4 代和第 5 代英特尔®至强®处理器上 LLM 的第 1 令牌性能。通过对英特尔®锐炫™ GPU 的 oneDNN、INT4 和 INT8 支持,实现更好的 LLM 压缩和改进的性能。最后实现了更高的可移植性和性能,可在边缘、云端或本地运行 AI。
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用,使用习惯与 OpenVINO™ C++ API 一致。OpenVINO™ C# API 由于是基于 OpenVINO™ 开发,所支持的平台与 OpenVINO™ 完全一致,具体信息可以参考 OpenVINO™。通过使用 OpenVINO™ C# API,可以在 .NET、.NET Framework等框架下使用 C# 语言实现深度学习模型在指定平台推理加速。
1.2 Segment Anything Model (SAM)
Segment Anything Model(SAM)是一个基于Transformer的深度学习模型,主要应用于图像分割领域。SAM采用了Transformer架构,主要由编码器和解码器组成,编码器负责将输入的图像信息编码成上下文向量,而解码器则将上下文向量转化为具体的分割输出。

SAM的核心思想是「自适应分割」,即能够根据不同图像或视频中的对象,自动学习如何对其进行精确分割;并且具有零样本迁移到其他任务中的能力,这意味着它可以对训练过程中未曾遇到过的物体和图像类型进行分割;SAM被视为视觉领域的通用大模型,其泛化能力强,可以涵盖广泛的用例,并且可以在新的图像领域上即时应用,无需额外的训练。

总的来说,Segment Anything Model(SAM)是一个先进的图像分割模型,以其强大的自适应分割能力、零样本迁移能力和通用性而著称。然而,在实际应用中仍需注意其泛化能力和域适应方面的挑战。
2. 模型下载与转换
2.1 安装环境
该代码要求「python>=3.8」,以及「pytorch>=1.7」和「torchvision>=0.8」。请按照此处的说明操作(https://pytorch.org/get-started/locally/)以安装PyTorch和TorchVision依赖项。
pip install git+https://github.com/facebookresearch/segment-anything.git
然后安装一些其他的依赖项:
pip install opencv-python pycocotools matplotlib onnxruntime onnx
2.2 下载模型
此处直接下载官方训练好的模型:
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
2.3 模型转换
此处模型转换使用Python实现,上面我们已经安装好了模型转换环境,下面首先导入所需要的程序包,如下所示:
import torch
from segment_anything import sam_model_registry
from segment_anything.utils.onnx import SamOnnxModel
然后导出编码器模型,编码器负责将输入的图像信息编码成上下文向量,因此其模型输入输出结构相对较为简单,转换代码如下所示:
torch.onnx.export(
f="vit_b_encoder.onnx",
model=sam.image_encoder,
args=torch.randn(1, 3, 1024, 1024),
input_names=["images"],
output_names=["embeddings"],
export_params=True)
接下来转换解码器模型,解码器则将上下文向量转化为具体的分割输出,因此在输入时需要指定分割的位置信息,所以其输入比较多,,分别为:
image_embeddings: 编码器模型对图片编码后的输出内容,在使用时直接将编码器模型运行后的输出加载到该模型输入节点即可。
point_coords: 输入的提示坐标或位置,对应点输入和框输入。方框使用两个点进行编码,一个用于左上角,另一个用于右下角。坐标必须已转换为长边1024。具有长度为1的批索引。
point_labels: 稀疏输入提示的标签,0是负输入点,1是正输入点,2是输入框左上角,3是输入框右下角,-1是填充点。如果没有框输入,则应连接标签为-1且坐标为(0.0,0.0)的单个填充点。
mask_input: 形状为1x1x256x256的模型的掩码输入,如果没有掩码输入,也必须提供全为0的输入。
has_mask_input: 掩码输入的指示符。1表示掩码输入,0表示没有掩码输入。
orig_im_size: 表示原始图片形状大小,输入格式(H,W)。
模型转换代码如下所示:
checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
onnx_model = SamOnnxModel(sam, return_single_mask=True)
embed_dim = sam.prompt_encoder.embed_dim
embed_size = sam.prompt_encoder.image_embedding_size
mask_input_size = [4 * x for x in embed_size]
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),
"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float),
"has_mask_input": torch.tensor([1], dtype=torch.float),
"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float),
}
output_names = ["masks", "iou_predictions", "low_res_masks"]
torch.onnx.export(
f="vit_b_decoder.onnx",
model=onnx_model,
args=tuple(dummy_inputs.values()),
input_names=list(dummy_inputs.keys()),
output_names=output_names,
dynamic_axes={
"point_coords": {1: "num_points"},
"point_labels": {1: "num_points"}
},
export_params=True,
opset_version=17,
do_constant_folding=True
)
3. 模型部署代码
3.1 编码器模型部署代码
staticfloat[] ImageEmbeddings(Mat img, string model_path)
{
Core core = new Core();
Model model = core.read_model(model_path);
OvExtensions.printf_model_info(model);
CompiledModel compiled = core.compile_model(model, "CPU");
Console.WriteLine("Compile Model Sucessfully!");
InferRequest request = compiled.create_infer_request();
Mat mat = new Mat();
Cv2.CvtColor(img, mat, ColorConversionCodes.BGR2RGB);
float factor = 0;
mat = Resize.letterbox_img(mat, 1024, out factor);
mat = Normalize.run(mat, newfloat[] { 123.675f, 116.28f, 103.53f }, newfloat[] { 1.0f / 58.395f, 1.0f / 57.12f, 1.0f / 57.375f }, false);
Tensor input_tensor = request.get_input_tensor();
float[] input_data = Permute.run(mat);
input_tensor.set_data(input_data);
Stopwatch sw = new Stopwatch();
sw.Start();
request.infer();
sw.Stop();
Console.WriteLine("Inference time: " + sw.ElapsedMilliseconds);
Tensor output_tensor = request.get_output_tensor();
Console.WriteLine(output_tensor.get_shape().to_string());
return output_tensor.get_data<float>((int)output_tensor.get_size());
}
3.2 解码器模型部署代码
staticbyte[] ImageDecodings(string model_path, float[] image_embeddings, float[] onnx_coord,
float[] onnx_label, float[] onnx_mask_input, float[] onnx_has_mask_input, float[] img_size)
{
Core core = new Core();
Model model = core.read_model(model_path);
OvExtensions.printf_model_info(model);
CompiledModel compiled = core.compile_model(model, "CPU");
Console.WriteLine("Compile Model Sucessfully!");
InferRequest request = compiled.create_infer_request();
Tensor tensor1 = request.get_tensor("image_embeddings");
tensor1.set_data(image_embeddings);
Tensor tensor2 = request.get_tensor("point_coords");
tensor2.set_shape(new Shape(1, 3, 2));
tensor2.set_data(onnx_coord);
Tensor tensor3 = request.get_tensor("point_labels");
tensor3.set_shape(new Shape(1, 3));
tensor3.set_data(onnx_label);
Tensor tensor4 = request.get_tensor("mask_input");
tensor4.set_data(onnx_mask_input);
Tensor tensor5 = request.get_tensor("has_mask_input");
tensor5.set_data(onnx_has_mask_input);
Tensor tensor6 = request.get_tensor("orig_im_size");
tensor6.set_data(img_size);
Stopwatch sw = new Stopwatch();
sw.Start();
request.infer();
sw.Stop();
Console.WriteLine("Inference time: " + sw.ElapsedMilliseconds);
Tensor output_tensor = request.get_tensor("masks");
float[] mask_data = output_tensor.get_data<float>((int)output_tensor.get_size());
byte[] mask_data_byte = newbyte[mask_data.Length];
for (int i = 0; i < mask_data.Length; i++)
{
mask_data_byte[i] = (byte)(mask_data[i] > 0 ? 255 : 0);
}
return mask_data_byte;
}
4. 模型部署测试代码
下面是模型部署案例测试代码,通过调用
staticvoidMain(string[] args)
{
string embedding_model = "./../../../../../model/vit_b_encoder/vit_b_encoder.onnx";
string decoding_model = "./../../../../../model/vit_b_decoder.onnx";
string image_path = "./../../../../../images/dog.jpg";
string image_embedding_path = "./../../../../../images/dog.bin";
Mat img = Cv2.ImRead(image_path);
float factor = 0;
Resize.letterbox_img(img, 1024, out factor);
if (!File.Exists(image_embedding_path))
{
float[] data = ImageEmbeddings(img, embedding_model);
SaveToFile(data, image_embedding_path);
}
float[] image_embedding_data = LoadFromFile(image_embedding_path);
float[] onnx_coord = newfloat[6] { 600f / factor, 200f / factor, 480 / factor, 130 / factor, (480 + 190)/factor, (130 + 140)/factor };
float[] onnx_label = newfloat[3] { 1f, 2f, 3f };
float[] onnx_mask_input = newfloat[256 * 256];
float[] onnx_has_mask_input = newfloat[1] { 0 };
float[] img_size = newfloat[2] { img.Height, img.Width };
byte[] result = ImageDecodings(decoding_model, image_embedding_data, onnx_coord, onnx_label, onnx_mask_input, onnx_has_mask_input, img_size);
Cv2.Rectangle(img, new Rect(600, 200, 20, 20), new Scalar(0, 0, 255), -1);
Cv2.Rectangle(img, new Rect(480, 130, 190, 140), new Scalar(0, 255, 255), 2);
Mat mask = new Mat(img.Rows, img.Cols, MatType.CV_8UC1, result);
Mat rgb_mask = Mat.Zeros(new Size(img.Cols, img.Rows), MatType.CV_8UC3);
Cv2.Add(rgb_mask, new Scalar(255.0, 144.0, 37.0, 0.6), rgb_mask, mask);
Mat new_mat = new Mat();
Cv2.AddWeighted(img, 0.5, rgb_mask, 0.5, 0.0, new_mat);
Cv2.ImShow("mask", new_mat);
Cv2.WaitKey(0);
}
5. 预测效果
下面展示了几个预测效果情况:

该图在输入时指定了两个标记点,同时标注在了车身和车窗上,那么就会根据所标记的点提取,两个点都是在车上,因此最后分割出来的结果是车身。

与上一张图片不同的shi,在这张图片中我们只标记了车窗位置,因此分割结果只分割了车窗位置。

同样地在这张图片中我们标记了狗狗,因此他最终分割出来了狗狗的位置。
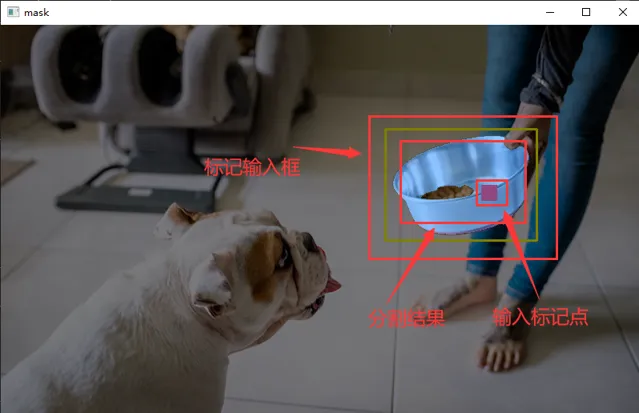
下面我们对图片中的饭盆进行分割,我们标记了饭盆,并输入了一个范围框,这样模型在这个范围里分割出了饭盆。
6. 总结
在该项目中,我们演示了如何在C#中使用OpenVINO™部署 Segment Anything Model 实现任意目标分割。最后如果各位开发者在使用中有任何问题,以及对该接口开发有任何建议,欢迎大家与我联系。

推荐阅读
●
●
●
●
●
●










