向量存储是一种专门用于存储和管理向量嵌入的数据库。
向量存储旨在高效处理大量向量,提供根据特定标准添加、查询和检索向量的功能。它可用于支持语义搜索等应用程序,在这些应用程序中,您可以查找与给定查询在语义上相似的文本段落或文档。
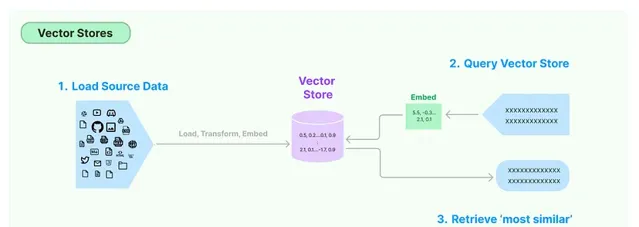
内容和含义相似的文本会具有相似的向量,也就是说,它们在嵌入空间中的向量之间的距离会很小。
例如,「猫在沙发上睡觉」和「小猫在沙发上打盹」这两个句子的单词不同,但含义相似。它们的嵌入向量在嵌入空间中彼此接近,反映了它们的语义相似性。嵌入向量的这一特性对于各种自然语言处理任务至关重要,例如语义搜索、文本聚类和机器翻译,在这些任务中,理解文本的含义至关重要。
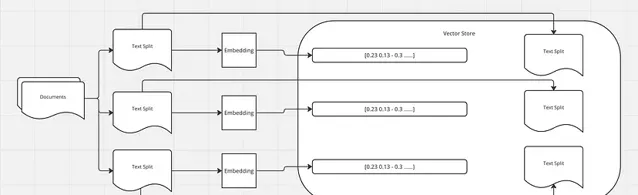
如前所述,我们使用文档加载器加载文档,然后使用文档转换器将文本分成块。接下来,我们为每个块生成嵌入,并将这些嵌入及其相应的拆分存储在向量存储中。
将查询转换为嵌入后,向量存储会根据相似度度量(例如余弦相似度)搜索最相似的向量(即最相似的文本)。然后检索与这些相似向量相对应的文本作为查询结果。
在 Langchain 工作流中,这些检索到的文本可以进一步处理,方法是将它们与原始查询一起传递给大型语言模型 (LLM) 进行进一步分析或处理。例如,LLM 可以根据查询和检索到的文本生成响应,或者可以执行一些需要理解类似文本提供的上下文的任务。Langchain 中存在不同的向量存储实现,每种实现都针对不同的用例和存储要求进行了优化。一些向量存储可能使用内存存储以实现快速访问,而另一些向量存储可能使用基于磁盘的存储以实现可扩展性。完整列表:
https://python.langchain.com/v0.2/docs/integrations/vectorstores/
import os
os.environ["OPENAI_API_KEY"] = "your-key"
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
embeddings = OpenAIEmbeddings()
llm_model = "gpt-4"
llm = ChatOpenAI(temperature=0.0, model=llm_model)
loader = PyPDFLoader("book.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
text_splits = text_splitter.split_documents(docs)
print(len(text_splits))
# 6
OpenAIEmbeddings
是为了生成嵌入而创建的,并且 的实例
ChatOpenAI
是为了与
GPT-4
模型交互而创建的。
PyPDFLoader
从名为「book.pdf」的
PDF
文件中加载文本。加载的文本存储在变量中docs。
RecursiveCharacterTextSplitter
将加载的文本拆分为较小的块,每个块的最大大小为
1500
个字符,连续块之间有
150
个字符的重叠。该
split_documents
方法用于执行拆分,并将生成的文本块列表存储在 中
text_splits
。
unset unset Chroma unset unset
Chroma是一个开源向量数据库,专为高效存储和查询向量嵌入而设计。它与 Langchain 集成良好,使其成为在该环境中使用嵌入的开发人员的热门选择。
pip install chromadb
Chroma 优先考虑开发人员的易用性。它提供了一个简单的 API,其中包含添加、获取、更新和删除等常见数据库操作,以及基于相似性的查询功能。
from langchain.vectorstores import Chroma
persist_directory = "./data/db/chroma"
vectorstore = Chroma.from_documents(
documents=text_splits,
embedding=embeddings,
persist_directory=persist_directory
)
print(vectorstore._collection.count()) # 6
persist_directory
是
Chroma
将持久存储其数据的路径。这可确保即使应用程序终止后数据仍然可用。
该
from_documents
方法采用以下参数:
documents
:要存储在向量存储中的文本文档(或文本拆分)列表。在本例中,
text_splits
假定为先前从较大文档中拆分出来的文本块列表。
embeddingOpenAIEmbeddings
:用于为文档生成嵌入的嵌入模型。这应该是可以从文本(例如对话中较早的文本)生成嵌入的类的实例。
persist_directory
:矢量存储将在磁盘上保存其数据的目录。这设置为
persist_directory
先前定义的变量。
query = "what is the purpose of the book?"
docs_resp = vectorstore.similarity_search(query=query, k=3)
print(len(docs_resp))
print(docs_resp[0].page_content)
vectorstore.persist()
"""
Our goal with this book is to provide the guidance and framework for you, the reader, to grow on
the path to being a truly excellent database reliability engineer (DBRE). When naming the book we
chose to use the words reliability engineer , rather than administrator.
Ben Treynor, VP of Engineering at Google, says the following about reliability engi‐ neering:
fundamentally doing work that has historically been done by an operations tea...
"""
该查询将用于在向量存储中搜索类似的文档。
该
similarity_search
方法采用以下参数:
query
:用于搜索类似文档的文本查询。
k
:要检索的最相似文档的数量。在本例中,
k=3
表示将返回前
3
个最相似的文档。结果,
docs_resp
是与查询最相似的文档列表。
persist
方法使用创建向量存储时指定的当前状态保存到vectorstore磁盘的persist_directory`
unset unset Faiss unset unset
FAISS 是Facebook AI Similarity Search的缩写,是 Facebook 开发的一款功能强大的开源库,用于对高维向量进行高效的相似性搜索。
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(text_splits, embeddings)
print(db.index.ntotal) # 6
docs = db.similarity_search(query)
print(docs[0].page_content)
"""
Our goal with this book is to provide the guidance and framework for you, the reader, to grow on
the path to being a truly excellent database reliability engineer (DBRE). When naming the book we
chose to use the words reliability engineer , rather than administrator.
Ben Treynor, VP of Engineering at Google, says the following about reliability engi‐ neering:
fundamentally doing work that has historically been done by an operations team, but using engineers with software
expertise, and banking on the fact that these engineers are inherently both predisposed to, and have the ability to,
substitute automation for human labor.
...
"""
db.save_local("faiss_index")
可以加载Embedding模型构建Faiss
from langchain_huggingface import HuggingFaceEmbeddings
# from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.faiss import FAISS
from langchain_core.documents import Document
documents = [
Document(
meta_data={'text': 'PC'},
page_content='个人电脑',
),
Document(
meta_data={'text': 'doctor'},
page_content='医生办公室',
)
]
embedding_path = r'H:\pretrained_models\bert\english\paraphrase-multilingual-mpnet-base-v2'
embedding_model = HuggingFaceEmbeddings(model_name=embedding_path)
db = FAISS.from_documents(documents, embedding=embedding_model)
db.save_local('../.cache/faiss.index')
db = FAISS.load_local('../.cache/faiss.index', embeddings=embedding_model, index_name='index',allow_dangerous_deserialization=True)
docs = db.similarity_search_with_score('台式机电脑')
print(docs)










