阿 里云 EMR Serverless Spark 版是一款云原生,专为大规模数据处理和分析而设计的全托管 Serverless 产品。 它为企业提供了一站式的数据平台服务,包括任务开发、调试、调度和运维等,极大地简化了数据处理的全生命周期工作流程。 使用 EMR Serverless Spark 版,企业可以更专注于数据分析和价值提炼,提高工作效率。
阿里云 EMR Serverless Spark 版 现已开启公测,欢迎广大开发者及企业用户参与,解锁全托管、一站式数据开发体验。
产品优势
云原生极速计算引擎 :内置 Spark Native Engine,相对开源版本 性能提升200% ;内置 Celeborn,支持 PB 级 Shuffle 数据,计算资源总成本 最高下降 30% 。
开放化的数据湖架构 :支持计算存储分离,计算可弹性伸缩、存储可按量付费;对接 OSS-HDFS,完全兼容 HDFS 的云上存储,无缝平滑迁移上云;中心化的 DLF 元数据,全面打通湖仓元数据。
一站式的开发体验 :提供作业开发、调试、发布、调度等一站式数据开发体验;内置版本管理、开发与生产隔离,满足企业级开发与发布标准。
Serverless 的资源平台 :开箱即用,无需手动管理和运维云基础设施;弹性伸缩,秒级资源弹性与供给。
应用场景
基于 EMR Serverless Spark 版建立数据平台
得益于EMR Serverless Spark 版开放的产品架构,使得其在数据湖中对结构化和非结构化数据进行分析与处理变得简单高效。此外,还内置了任务调度系统,允许用户轻松构建和管理数据 ETL 任务,实现数据管道的自动化和周期性数据处理。
EMR Serverless Spark 版还内嵌了先进的版本管理系统,并提供了开发与生产环境的完全隔离,确保符合企业级用户在研发和发布流程方面的严格要求。这些特性共同保障了数据处理的可靠性和效率,同时满足企业级应用的高标准要求。

公测说明
EMR Serverless Spark 版免费公测已开启,预计于2024年06月25日结束。公测阶段面向所有用户开放,您可以免费试用。免费试用结束后,产品将正常计费。
免费公测限制
公测期间,有以下限制:
工作空间的资源配额上限为100计算单元(CU)。
单个Spark任务所能处理的Shuffle数据量最大限制为5TB。
工作空间内所有并行运行的任务共写入Shuffle数据的总量上限为10TB。
同一工作空间内允许并发执行的任务数量上限为100个。
不保障服务等级协议(SLA),但服务不降级。
公测期间包年包月的工作空间仅支持续费一个月。
操作步骤
进入 EMR Serverless Spark 页面。
登录 E-MapReduce控制台(https://emr-next.console.aliyun.com/#/region/cn-hangzhou/resource/all/overview) 。
在左侧导航栏,选择 EMR Serverless > Spark 。
在顶部菜单栏处,根据实际情况选择地域。
在 Spark 页面,单击 创建工作空间 。
在 E-MapReduce Serverless Spark 页面,完成相关配置。
参数 | 说明 | 示例 |
地域 | 建议选择与您数据所在地相同的地域。 | 华东1(杭州) |
付费类型 | 目前仅支持 按量付费 。 | 按量付费 |
工作空间名称 | 以字母开头,仅支持英文字母、数字和短划线(-),长度限制为1~60个字符。 说明 同一个阿里云账号下的工作空间名称是唯一的,请勿填写已有的名称,否则会提示您重新填写。 | emr-serverless-spark |
DLF Catalog | 用于存储和管理您的元数据。 开通DLF后,系统会为您选择默认的DLF数据目录,默认为UID。如果针对不同集群您期望使用不同的数据目录,则可以按照以下方式新建目录。
| emr-dlf |
瞬时资源上限 | 工作空间同时处理任务的最大并发CU数量。 | 100 |
工作空间基础路径 | 用于存储作业日志、运行事件、资源等数据文件。建议选择一个开通了OSS-HDFS服务的Bucket。 | emr-oss-hdfs |
工作空间类型 | 支持 基础版 和 专业版 。更多信息,请参见 工作空间类型说明(https://help.aliyun.com/zh/emr/emr-serverless-spark/getting-started/create-a-workspace?spm=a2c4g.11186623.0.i5#2458cb0494a4h) 。 | 专业版 |
高级设置 | 打开该开关后,您需要配置以下信息: 执行角色 :指定EMR Serverless Spark运行作业所采用的角色名,角色名称为AliyunEMRSparkJobRunDefaultRole。 EMR Spark使用该角色来访问您在其他云产品中的资源,包括OSS和DLF等产品的资源。 | AliyunEMRSparkJobRunDefaultRole |
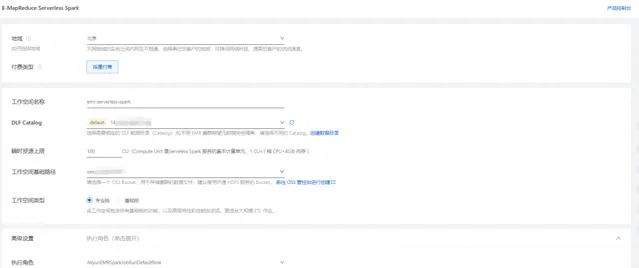
4.当所有的信息确认正确后,单击 创建工作空间 。
联系我们
如果您在使用 EMR Serverless Spark 版的过程中遇到任何疑问,可加入钉钉群 58570004119 咨询。
快速跳转
EMR Serverless Spark 版 官网: https://www.aliyun.com/product/bigdata/serverlessspark
产品控制台: https://emr-next.console.aliyun.com/
产品文档: https://help.aliyun.com/zh/emr/emr-serverless-spark/
SQL 任务快速入门: https://help.aliyun.com/zh/emr/emr-serverless-spark/getting-started/get-started-with-sql-task-development
点 击「 阅读原文 」立即参与 EMR Serverless Spark 版免费公测!











