【编者按】2024年3月5日,Stability AI 发布了研究论文【Scaling Rectified Flow Transformers for High-Resolution Image Synthesis】,详细地介绍了 Stable Diffusion 3 的底层技术。Stable Diffusion 3采用了与 Sora 相同的 DiT(Diffusion Transformer)架构,在排版和提示遵守方面表现优于 DALL·E 3、Midjourney v6 和 Ideogram v1等最先进的文本到图像生成系统。
原文链接:https://stability.ai/news/stable-diffusion-3-research-paper
整理 | 梦依丹
出品 | AI 科技大本营
继 2 月份发布 Stable Diffusion 3 预览版之后, Stable Diffusion 官方团队直接给出了这一版本背后的研究论文,跟大家分享技术细节。
Stable Diffusion 3 模型套件的参数范围在 800M 和 8B 之间, 使用了分离权重集合的 多模态扩散变换器(MMDiT)架构, 相比之前的 SD3 版本,它改善了文本理解和拼写能力。
基于人类偏好的评估结果显示, Stable Diffusion 3 在 排版和提 示遵循方面要比 DALL·E 3、Midjourney v6 和 Ideogram v1 强大,在使用 50 个采样步骤时,生成分辨率为 1024x1024 的图像需要 34 秒。

Prompt: A beautiful painting of flowing colors and styles forming the words "The SD3 research paper is here!"the background is speckled with drops and splashes of paint
性能
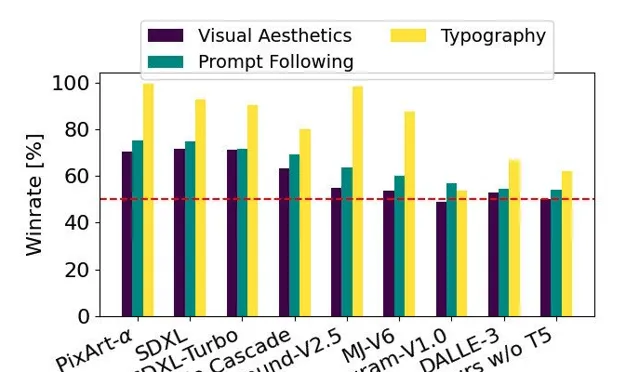
该图表以 SD3 为基准,基于人类偏好评估,展示了 SD3 在视觉美学、提示遵循和排版等方面相对于其他竞争模型的优势
他们将 Stable Diffusion 3 的输出图像和其他开放模型, 包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α 以及闭源系统,如 DALL·E 3、Midjourney v6 和 Ideogram v1 进行 性能评估和 人类反馈,要求每位评估人员提供 每个模型的示例输出,并要求他们根据模型输出与给定提示内容的一致性程度("prompt following"),根据提示内容对文本的渲染效果("typography") 以及哪个图像具有更高的美学质量("visual aesthetics")来选择最佳结果。
结果发现,Stable Diffusion 3 在与上述模型进行对比之后,要么与当前最先进的文本到图像生成系统持平,要么表现更好。
在早期未经优化的消费级硬件推理测试中, 拥有 80 亿个参数的最大 SD3 模型适配 RTX 4090 的 24GB VRAM,使用 50 个采样步骤生成 1024x1024 分辨率的图像需要 34 秒。 此外,Stable Diffusion 3 初步发布时会有多个版本,包括 8 亿到 80 亿个参数的模型,以进一步消除硬件限制。

架构细节
在文本到图像生成中,模型需要同时考虑文本和图像两种信息。这种新架构称为 MMDiT,意味着它可以处理多种不同的信息。与之前的稳定扩散版本一样,SD 3 团队使用预训练模型来获取适当的文本和图像表示。具体来说,他们使用了三种不同的文本嵌入器 - 两个 CLIP 模型和 T5 模型 - 来编码文本信息,并使用了改进的自编码模型来编码图像信息。
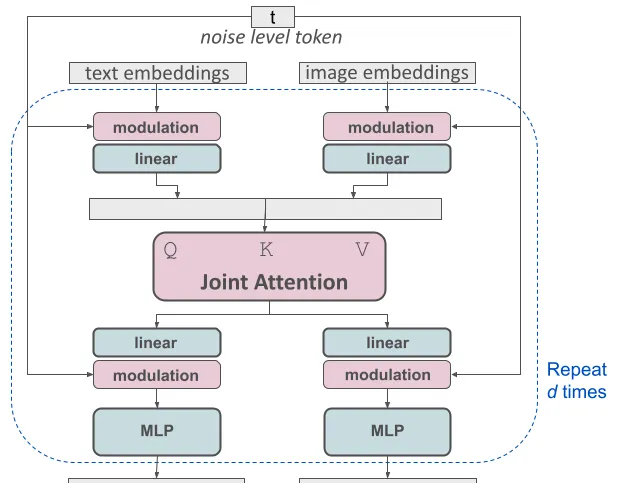
修改后的多模态扩散变压器(MMDiT)的一个块进行概念可视化
SD3 架构建立在扩散变压器("DiT",Peebles & Xie,2023年)的基础上。由于文本和图像的嵌入概念上有很大的差异,他们为这两种模态使用了两套独立的权重。如上图所示,这相当于每个模态都有两个独立的变压器,但在注意力操作中,他们将两种模态的序列连接在一起,使得两种表示可以在各自的空间中工作,同时考虑到对方的信息。
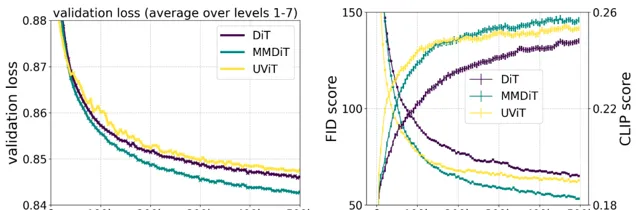
在训练过程中,SD3 创新的 MMDiT 架构在视觉保真度和文本对齐度方面表现优于已有的文本到图像的骨干架构,如 UViT(Hoogeboom 等,2023 年)和DiT(Peebles&Xie,2023年)。
通过采用这种方法,可以在图像和文本标记之间允许信息的流动,以提高生成的输出的整体理解度和排版效果。这种架构还可以轻松扩展到多种模态,例如视频,我们在论文(https://arxiv.org/pdf/2403.03206.pdf)中进行了讨论。

Stable Diffusion 3 提示跟随功能的改进使得模型能够创造出聚焦于不同主题和特征的图像, 并且在图像风格上保持高度的灵活性。

通过重新加权调整矫正流
Stable Diffusion 3 采用矫正流(Rectified Flow,RF)的思想(Liu等,2022年;Albergo & Vanden-Eijnden,2022年;Lipman等,2023年),在训练过程中,数据和噪声按照线性轨迹相互关联。这种方法能够获得更加直接的推理路径,从而减少采样所需的步骤。同时,我SD 3 团队还引入了一种新颖的轨迹采样计划。这个计划更注重轨迹中间部分的采样,因为他们认为这些部分对于预测任务更具挑战性。他们通过与其他 60 种扩散轨迹(如 LDM、EDM 和 ADM)进行比较,使用了多个数据集、评估指标和采样设置。
结果显示,虽然之前的矫正流方法在少量采样步骤时表现出改进的性能,但随着步骤增加,性能相对下降。相反地,他们提出的重新加权矫正流方法在各种步骤下都能持续提升性能。
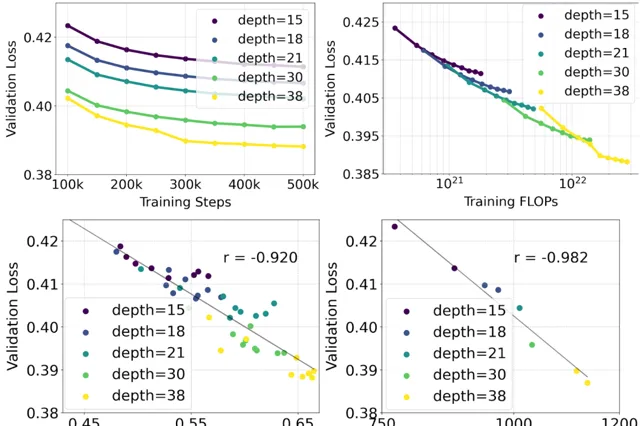
他们对采用重新加权的矫正流公式和 MMDiT 骨干网络进行了文本到图像合成的规模化研究。他们训练了不同规模的模型,从小到大,观察到随着模型大小和训练步骤的增加,验证损失逐渐减小(顶部行)。 为了测试这是否能够带来模型输出的实质性改进,他 们还进行了自动图像对齐度量(GenEval)和人类偏好评分(ELO)的评估(底部行)。
研究结果显示,这些评估指标与验证损失之间存在明显的相关性,验证损失可以很好地预测模型的整体性能。 此外,还 发现模型的性能随着规模的增加并未达到饱和状态,这让他们对未来能够进一步提升模型性能持有积极的态度。
灵活的文本编码器
他们 通过在推理过程中移除庞大的 4.7B 参数的 T5 文本编码器,可以显著减少 SD3 的内存需求,只会带来轻微的性能损失。移除该文本编码器不会影响视觉美感(无T5时的胜率:50%),仅会导致略微降低的文本一致性(胜率46%),如上图所示的「性能」部分。然而,团队建议在生成书面文本时使用T5,以充分发挥 SD3 的能力,因为他们观察到在没有 T5 的情况下排版生成的性能下降更为明显(胜率 38%),如下面的示例所示。

仅在生成过程中移除 T5 会导致性能显著下降,特别是在处理涉及许多细节或大量书面文本的复杂提示时。上图展示了每个示例的三个随机样本。
要了解更多关于 MMDiT、矫正流(Rectified Flows)以及 Stable Diffusion 3 背后的研究,可以阅读他们的完整论文:https://arxiv.org/pdf/2403.03206.pdf。
随着 AI 大模型研究与应用领域地不断扩展,越来越多的计算机人才加入这一浪潮变革之中。 由 CSDN 和 Boolan 打造的【基于大语言模型的应用开发】课程让开发者深入理解大模型背后的核心技术,吃透其原理与应用,紧跟时代潮流。












