所谓的「打宽」,就是将明细表和可能来自多个数据源的多张维表进行关联,汇总成一个大宽表,便于后续处理分析的过程。
时至今日,打宽 + 实时分析仍然是流处理领域内最常见的场景。然而,真正面对这个问题时,许多人还是难以理解为何如此普遍而具体的场景却需要考虑种种疑难杂症。
在深入这些问题之前,我们可以先回顾一下业内已经解决了什么:
1 过去基于 StarRocks 的打宽方案
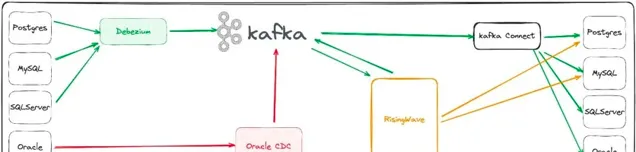
业务数据库的 CDC 抽取: 如今主流的 MySQL、Postgres、MongoDB 等数据库的同步均已被 RisingWave、FlinkCDC 等开源工具原生支持。
实时写入到数仓中: 流行的数据仓库系统,如 StarRocks,其产品已支持了相对高效的写入能力:
主键表: 这一表类型在 StarRocks 存储内部维护了主键索引,可以高效地处理更新和删除。RisingWave 写入 StarRocks 默认就需要这一表类型。
部分列更新: 非常适合大宽表下,每次更新只有少部分列(一般低于30%)被变更的场景。
StreamLoad: StarRocks 支持通过 HTTP 进行数据批量写入,实测下来写入吞吐在绝大多数场景都能满足需求。
小状态的数据清洗和打宽: 许多开源或商业的流处理软件都提供了标准 SQL支持,这使得数据清洗时不需要担心表达能力的缺失。
2 大状态的无奈
但需要注意的是,不论是 FlinkSQL 还是 Materialize,在超大状态维护上都或多或少地会遇到一些挑战,用户需要在复杂的内存磁盘调优与牺牲状态大小这两害之间选其轻。例如 FlinkSQL 就提供了许多减少状态的技巧,包括但不限于时间窗口+Watermark,Lookup Join,状态清理(TTL)等功能,而同时用户也不得不去学习大状态下 Checkpoint 的调优方式。
但如果手里钞票充足的话,还有一种选择,就是采购单台数十万成本的大规格服务器。

回到我们最初的讨论,即使基本的 ETL(即 CDC → 数据清洗 → 数仓实时写入)已被解决,事实上行业内仍然有许多尚未解决的痛点:
复杂流处理逻辑的大状态维护
如何长时间地(例如数月)保留中间状态
如何基于大宽表做实时物化视图
3 实时打宽的最后一公里
相信有深入过以上问题的朋友都能意识到,这其中所缺乏的恰恰是一个面向流计算的大状态存储:
它的存储成本必须低,不常访问的数据应当被放在相对廉价的存储上,例如 HDFS 或 S3。
它应该能够高效地处理流 Join 的频繁更新。
它应该可查询,从而能在一些查询固定的监控场景里,直接基于流计算结果构建实时指标视图。
它应该能够迅速地从故障中恢复。
RisingWave 旨在提供的就是这样的能力。
在实时打宽这一场景里,RisingWave 能够在较低的机器成本下,利用存算分离的能力,无需调优技巧,来支撑一个过去难以维护的 Join 链路。

上图引用自 RisingWave 用户案例 「 」,里面提到即使是 13 个表的 Join(如今已有数十个表的 Join),RisingWave 依然能够游刃有余地处理。
4 完善的实时分析技术栈
随着 RisingWave 的打宽能力在许多用户场景里逐步被验证,我们也更多地将精力投入到对这一场景的全方面打磨。
在刚刚发布的 1.7 版本,我们优化了对 StarRocks 的写入,使得整个过程更加丝滑。

除了打宽,用户还可以将 RisingWave 视作一个数仓的实时缓存。在实时性要求低的场景,用户可以基于 StarRocks 完成离线分析,而当实时性无法满足的时候,用户就可以基于 RisingWave 的大宽表开发物化视图。在这套技术栈里,用户依照具体情况选择合适的技术即可。
除了通过 StarRocks Sink 写入外,RisingWave 也可以被用作 StarRocks 的外表,实现离线和在线的查询入口统一。
CREATEEXTERNALRESOURCE rw_jdbc
PROPERTIES (
"type"="jdbc",
"user"="postgres",
"password"="",
"jdbc_uri"="jdbc:postgresql://risingwave-standalone:4566/dev",
"driver_url"="https://repo1.maven.org/maven2/org/postgresql/postgresql/42.3.3/postgresql-42.3.3.jar",
"driver_ class"="org.postgresql.Driver"
);
CREATEEXTERNALTABLEusers (
idBIGINT,
description VARCHAR(255),
nameTEXT,
created_at DATETIME
) ENGINE=jdbc
properties (
"resource"="rw_jdbc",
"table"="users"
);
5 未来展望
即使大状态的问题解决了,我们仍然需要面对 Schema change 的挑战。上游 MySQL 表加列了,下游的 StarRocks 是否能同步加列?RisingWave 自身的表是否也能同步加列?
我们看到有些行业实践能够自动捕获上游的 DDL,同时对 StarRocks 也进行加列。未来我们或许也会提供类似的能力。目前而言,RisingWave 提供了 手动的加减列功能 [1] ,我们仍然在围绕这一能力不断加强。
参考资料
[1]
手动的加减列功能:
https://docs.risingwave.com/docs/current/alter-streaming/
关于 RisingWave
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于为用户提供极致简单、高效的流数据处理与管理能力。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,并助力用户极大地简化流计算架构,轻松搭建稳定且高效的流计算应用。
RisingWave 始终聆听来自社区的声音,并积极回应用户的反馈。目前,RisingWave 已汇聚了近 150 名开源贡献者和近 3000 名社区成员。全球范围内,已有上百个 RisingWave 集群在生产环境中部署。

往期推荐
技术内幕
用户案例











