作者 | 周周
责编 | 唐小引
出品丨AI 科技大本营(ID:rgznai100)
4 月 27 日上午,国产 AI 视频大模型 Vidu 在中关村论坛未来人工智能先锋论坛上发布。
「中国首个长时 长、高一致性、高动态性视频」是 Vidu 的代名词,Vidu 模型由清华大学和生数科技联合开发,具有以下 6 大特征: 模拟真实物理世界、富有想象力、具有多镜头语言、出色的视频时长、时空一致性高、理解中国元素。

模拟真实物理世界:展现复杂、细节丰富的场景,模拟真实世界的物理特性,符合物理规律,例如具有光影效果和人物表情等。
富有想象力:具备虚构场景能力,创造超现实主义画面
具有多镜头语言:支持实现复杂动态镜头,体现远、近、中景、特写,长镜头、追焦等效果
出色视频时长:一镜到底 16s 视频生成,单一大模型,端到端生成
时空一致性高:不同镜头之间的视频连贯,人物和场景在时空中保持一致
理解中国元素:可以理解、生成熊猫、龙等中国元素。

Vidu 背后依托的是一家名为生数科技的创业公司,北京生数科技有限公司成立于 2023年 3 月,核心团队成员来自清华大学人工智能研究院,生数科技的 CEO 唐家渝、首席科学家朱军以及 CTO 鲍凡,皆在人工智能和扩散模型领域有深厚研究。

该公司致力打造世界领先的多模态大模型,融合文本、图像、视频、3D 等多模态信息,探索生成式 AI 在艺术设计、游戏制作、影视后期、内容社交等场景的商业赋能,通过 AI 提升人类的创造力和生产力。
自 2023 年成立以来,生数科技已完成数亿元融资。据了解,生数科技是目前国内在多模态大模型赛道估值最高的创业团队。
与 SORA 不同的是,Vidu 已经开放了合作伙伴计划申请表,都可以填写申请表申请使用,链接如下:
https://shengshu.feishu.cn/share/base/form/shrcnybSDE4Id1JnA5EQ0scv1Ph

U-ViT 架构
U-ViT 是 Vidu 架构的核心技术,于 2022 年提出,全球首个 Diffusion 与 Transformer 融合的架构,被 CVPR2023 所收录。2023 年 3 月,团队开源全球首个基于 U-ViT 架构的多模态扩散大模型 UniDiffuser,被 ICML2023 所收录。
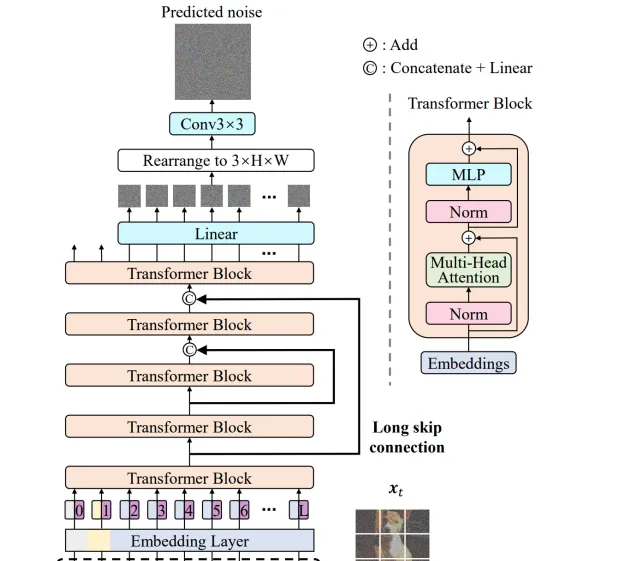
U-ViT 网络是将在图像领域热门的 Vision Transformer 结合 U-Net,应用在了 DiffisionModel 中。基于 ViT 将时间,条件,和图像块视作 token 输入到 Transformer block,受到基于 CNN 的 U-Net 在扩散模型中成功应用的启发,U-ViT 在网络浅层和深层之间引入长跳跃连接。同时,该架构选择性地在输出前添加一个 3×3 的卷积块以提高视觉质量。网络相关细节如下:
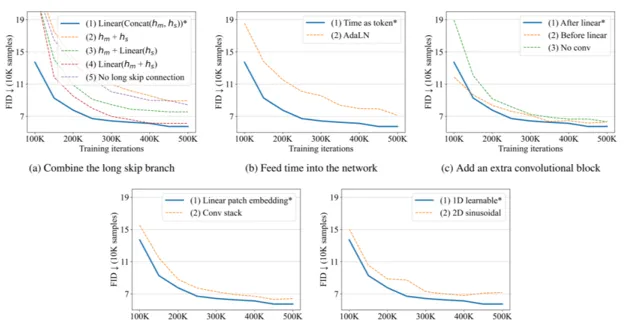
长跳跃连接组合方式: 长跳跃连接是融合特征的有效方式,U-ViT 对网络特征ℎ𝑚和ℎ𝑠的融合方式进行对比,包括以下几种:𝐿𝑖𝑛𝑒𝑎𝑟(𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑚, ℎ𝑠)),ℎ𝑚 + ℎ𝑠,ℎ𝑚 + 𝐿𝑖𝑛𝑒𝑎𝑟(ℎ𝑠),𝐿𝑖𝑛𝑒𝑎𝑟(ℎ𝑚, ℎ𝑠),𝑁𝑜 𝑙𝑜𝑛𝑔 𝑠𝑘𝑖𝑝 𝑐𝑜𝑛𝑛𝑒𝑐𝑡𝑖𝑜𝑛。其中,𝐿𝑖𝑛𝑒𝑎𝑟(𝐶𝑜𝑛𝑐𝑎𝑡(ℎ𝑚, ℎ𝑠))融合形式的性能最佳。
将时间嵌入网络的方式: 1.将时间视为 token;2.在 transformer 中加入层归一化的时间𝐴𝑑𝑎𝐿𝑁(ℎ, 𝑦) = 𝑦𝑠𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(ℎ) + 𝑦𝑏。实验结果表明第一种方法性能更佳。
在 transformer 后添加额外卷积块的方法: 1.在将 token 嵌入映射到图像块的线性投影后,添加 3*3 的卷积块;2.在线性投影前添加 3*3 的卷积块;3.不添加任何的卷积块。实验结果表明第一种方法优于其他两种方法。
补丁嵌入的变体: 1.对其采用线性投影,映射至 token 嵌入;2.使用 3*3 卷积块堆和 1*1 卷积块,将图像映射至 token 嵌入。实验结果表明线性投影效果更佳。
位置嵌入的变体: 1.采用一维可学习的位置嵌入;2.采用二维正弦位置嵌入。实验结果表明一维可学习的位置嵌入效果更佳。
U-ViT 为扩散模型提供了一个简单通用的基于 ViT 的主干网络。
UniDiffuser 扩散模型框架

UniDiffuser 扩散模型框架,通过一个统一的模型来建模多模态数据相关的所有分布,包括边缘、条件和联合分布,具备图像生成、文本生成、文本到图像生成、图像到文本生成以及图像-文本对生成等任务的能力。
模型统一预测所有分布
学习多模态数据集相关的所有分布,可以通过统一预测扰动数据中的对应的噪声期望来实现:UniDiffuser 模型同时对所有模态的数据进行扰动,给不同模态的数据设置各自时间步,并预测所有模态的噪声。不同的时间步长对应不同的扰动级别,零级表示给定相应模态的条件生成,最大级别表示通过忽略相应模态来进行无条件生成,绑定同样的时间步长意味着对两种模态进行联合生成。
对 UniDiffuser 应用 classifier-Free Guidance
classifier-Free Guidance 常用来提高条件扩散模型的生成样本质量,通过线性组合条件模型和无条件模型来采样
UniDiffuser 在图像和文本多模态的应用
首先,通过图像和文本编码器将分别图像和文本转换为连续的潜在嵌入,并引入两个解码器用于重建;然后,在嵌入上训练 UniDiffuser。其中,图像编码器包括两部分,第一部分是 Stable Diffusion 的 VAE,第二部分是 CLIP Image Encoder。文本编码器采用 Stable Diffusion的 CLIP text Encoder。UniDiffuser 根据上一节获取的嵌入训练联合噪声预测网络,该网络采用 U-ViT 作为主干来处理不同的模态。原始 U-ViT 将所有输入(包括数据、条件和时间步)视为标记,并在浅层和深层之间采用长跳跃连接,UniDiffuser 则将两种数据模态及其相应的时间步视为标记。
基于对 U-ViT 架构的深入理解以及长期积累的工程与数据经验,团队在短短两个月里进一步突破了长视频表示与处理的多项关键技术,研发了 Vidu 视频大模型,显著提升视频的连贯性和动态性。












