引入
如何開啟套用Kubernetes的第一步?Kubernetes是一套功能強大的工具,用於管理分布式雲原生應用程式,並保證其自動擴充套件和高可用性。然而,許多使用者在使用Kubernetes時往往會犯一些常見錯誤。
本文旨在揭示在使用Kubernetes時經常遇到的誤區,並提供避免錯誤的建議。
1. 不設定資源請求
資源請求設定,無疑是值得最多關註的一項。 CPU請求經常出現未設定,或者設定得過低 (以便在單個節點上安裝大量pod),導致節點超負荷執行。需求高峰時,節點的CPU資源會被充分利用,而工作負載只能獲得有限的資源,導 致CPU受到限制 ,進而導致應用程式延遲增加或超時等問題。
以下情況為演示案例,請勿隨意嘗試:
BestEffort配置 (pod的requests與limits均為0) :
resources: {}
CPU 效能極低的情況:
resources: requests: cpu: "1m"
另一方面,即使CPU未被充分利用,不恰當的CPU限制也會限制pod的執行,同樣會導致延遲。
關於Linux內核中的CPU CFS配額,以及基於CPU設定的CPU節流和關閉CFS配額的問題,曾有過公開討論: 過度限制CPU帶來的問題比它解決的問題多得多 。
記憶體過度使用會給你帶來更多麻煩。達到CPU限制會導致限制,達到記憶體限制會導致pod被終止。如何減少 OOMkill 情況發生的頻率?在使用Kubernetes時,應合理設定記憶體請求,不要過度占用記憶體,並透過保證QoS(服務品質),設定記憶體請求與限制量相等。
如下例:
Burstable (可能更頻繁地被 OOMkilled) :
resources:requests:memory: "128Mi"cpu: "500m"limits:memory: "256Mi"cpu: 2
Guaranteed:
resources:requests:memory: "128Mi"cpu: 2limits:memory: "128Mi"cpu: 2
如何最佳化資源設定?
使用 metrics-server,檢視 pod(及其容器)當前的 CPU 和記憶體使用情況。
你很可能已經在執行這項程式,需要執行以下程式碼:
kubectltop pods kubectltop pods --containers kubectltop nodes
然而,這些數據只反映了當前的使用狀態。為了更全面地了解資源使用情況, 及時看到不同時間段 (比如高峰期、昨天早上等) 的使用指標 ,可以采用Prometheus等工具。這些工具能夠收集並儲存指標數據,方便後續的查詢和圖表繪制。
VerticalPodAutoscaler(VPA)可以幫助 自動完成 這項手動過程——根據檢視到的CPU/記憶體使用情況,動態調整請求和限制。
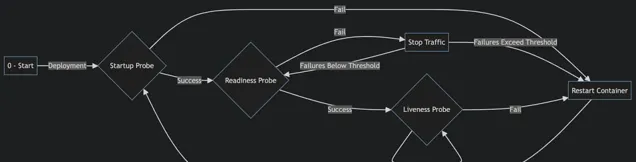
2. 忽略健康檢查
在Kubernetes環境中,健康檢查對於維護服務的穩定性至關重要。然而,健康檢查功能的利用率普遍較低。透過健康檢查,可以即時監測pod及其容器的健康狀況。
Kubernetes 有三種主要工具可用於健康檢查:
配置存活檢查(Liveness Check) 用於檢查應用程式是否存活。節點上執行的Kubelet 代理都會使用該探針,確保容器按預期執行。
就緒檢查(Readiness Checks) 用於確定容器何時準備好接收流量,容器的整個周期內都會執行。
啟動探針(Startup Probe) 確定容器套用何時成功啟動,檢查到啟動失敗後,即會重新啟動pod。
3. 濫用latest標簽
使用latest標簽沒有明確目的性,難以統一管理。Kubernetes文件對於在生產環境中使用docker images:latest標簽有明確規定:
在生產環境中應避免使用latest標簽部署容器,因為這會增加跟蹤映像版本和回滾的難度。
在生產環境中部署容器時,應避免使用 :latest 標簽,因為它很難跟蹤執行的是哪個版本的映像,也很難回滾。
隨著經驗積累,我們已經逐漸減少了對 :latest 標簽的使用,轉而采用別的替代方案。
4. 許可權過高的容器
為容器賦予過多許可權(如存取普通容器無法存取的資源),是開發人員在使用 Kubernetes時的常見錯誤,這會增加安全風險。
比如,在Docker容器內執行Docker守護行程,就可能構成特權容器的安全風險。
為了避免這種情況,建議避免為容器提供 CAP_SYS_ADMIN 功能,因為它包含所有內核漏洞的25%以上。
此外,避免向容器授予完全許可權和賦予容器的主機檔案系統許可權也很重要。這意味著可以利用容器可以透過惡意二進制檔替換二進制檔,進而危害整個主機。
為防止容器許可權過高,必須謹慎配置許可權設定,切勿以高於所需許可權的狀態執行行程。
此外,註意使用監控和日誌來檢測和解決問題。
5. 缺乏監控和日誌記錄
Kubernetes 環境中缺乏監控和日誌記錄會損害其安全性和整體效能。在故障排查和響應工作中,缺乏日誌記錄和監控會導致問題難以定位及解決。
一個常見的陷阱是,由於缺乏相關日誌或指標,無法找到 Kubernetes 平台和應用程式中的故障點。
因此,必須 設定適當的監控和日誌工具 ,如 Prometheus、Grafana、Fluentd 和 Jaeger等,以 收集、分析和視覺化指標、日誌和跟蹤資訊 ,進一步了解 Kubernetes 環境的效能和健康狀況。
透過實施嚴格的監控和日誌記錄實踐,企業能夠高效地整合資訊,獲取更深刻的洞察,並成功應對Kubernetes環境因其動態性和復雜性所帶來的挑戰。
6. 所有物件的預設名稱空間
在Kubernetes環境中,如果對所有物件使用預設的名稱空間,會導致組織和管理上的不便。由於default名稱空間是預設建立服務和應用程式的地方,並且在沒有明確指定的情況下會成為活動的名稱空間,過度依賴預設設定會使得集群內的不同元件或團隊在資源隔離和組織上顯得混亂。這進一步導致資源管理、存取控制和可見性方面的難題。
因此, 建議根據不同的計畫、團隊或應用程式需求,建立自訂的名稱空間 ,從而在Kubernetes集群中實作更清晰的組織結構、更合理的資源分配和更嚴格的存取控制。
透過利用多個名稱空間,使用者能更有條理地劃分和管理資源,提高 Kubernetes 環境的整體執行效率和安全性。
7. 安全配置不足
在部署應用程式時,安全性應始終是首要考慮的因素。使用集群外部可存取的端點、不保護機密、不考慮如何安全執行有許可權容器等,都是安全方面需要重視的關鍵點。
Kubernetes的安全性是任何部署都不可或缺的一環。面臨的安全挑戰包括:
授權: 身份驗證和授權機制對於控制Kubernetes集群中的資源存取至關重要。
網路: Kubernetes網路涉及管理覆蓋網路和伺服端點,以確保容器間的流量在集群內安全地路由。
儲存: 確保集群的儲存安全,包括確保數據不會被未經授權的使用者或行程存取,並保障數據的安全。
Kubernetes API伺服器提供了一個REST介面,可以存取儲存的所有資訊,這意味著,使用者只需向 API 發送 HTTP 請求,即可存取 API 中儲存的任何資訊。因此必須采取措施防止未經身份驗證的使用者存取這些數據。這可以透過使用使用者名稱/密碼或基於令牌的身份驗證等支持的方法為API伺服器配置身份驗證來實作。
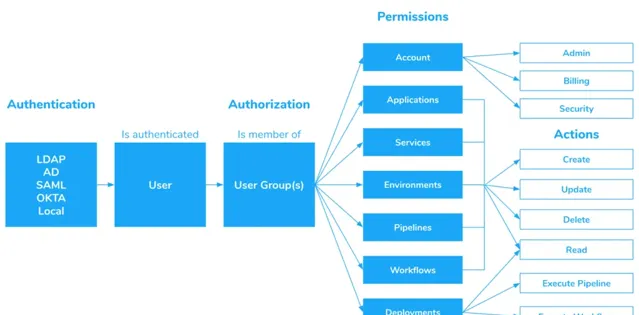
這不僅關系到集群自身的安全,還關系到集群上儲存的機密和配置安全。為防範潛在的漏洞攻擊,必須在集群上實施一套完善的安全控制。
使用基於角色的存取控制(RBAC)是一種保護Kubernetes集群的強大安全機制:根據分配給使用者的角色(比如「管理員」或「操作員」等不同的許可權級別)來限制對資源的存取,從而保護集群的安全。
管理員角色擁有完整的存取許可權,而操作員角色對集群內的資源擁有有限的許可權。透過這種方法,我們能夠更有效地控制和管理存取集群的所有使用者許可權。
8. poddisruptionbudget缺失
當您在Kubernetes上執行生產工作負載時,節點和集群可能需要經常進行升級或退休。PodDisruptionBudget(PDB)是集群管理員和集群使用者之間的服務保證API,它確保了服務的高可用性。
為避免因節點耗盡而導致的不必要服務中斷,強烈建議您建立PDB。
apiVersion: policy/v1kind: PodDisruptionBudgetmetadata:name: db-pdbspec:minAvailable: 2selector:matchLabels:app: database
作為集群使用者,你可以這樣告訴集群管理員:「嘿,我這裏有一個資料庫服務,無論你要做什麽,我都希望至少有兩個副本始終可用。」
9. pod 的自我反親緣性(self anti-affinities)
例如,當執行某個部署的多個Pod副本時,可能會遇到由於節點宕機而導致所有副本同時宕機的情況。
這是因為Kubernetes排程器預設不會為您的Pod強制執行anti-affinity策略。為了解決這個問題,需要明確地在Pod定義中指定affinity和podAntiAffinity規則:
......labels:app: db......affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:-labelSelector:matchExpressions:-key: "app"operator: Invalues:-dbtopologyKey: "kubernetes.io/hostname"
如上,這將確保 pod 被排程到不同的節點上(僅在排程時檢查,而不是在執行時,因此需要在排程時忽略執行期間檢查),從而提高系統的可用性和容錯能力。
我們說的是不同節點名稱上的 podAntiAffinity 而不是不同的可用性區域,即 topologyKey:"kubernetes.io/hostname。如果您真的需要適當的 HA,請深入了解這一主題。
10. 每個 HTTP 服務的負載均衡
你的集群中可能有更多的希望向外界公開的HTTP服務。
如果將 kubernetes 服務公開為 type:LoadBalancer ,其控制器(供應商特定)將提供並協調外部LoadBalancer,而在建立許多資源的情況下,這些資源可能會變得昂貴(外部靜態 IPv4 地址、按秒計價......)。
在這種情況下,共享一個外部負載均衡可能更有意義,將服務公開為 type:NodePort 公開,或者部署如 nginx-ingress-controller (或traefik、Istio等)作為暴露給外部負載平衡器的單一NodePort端點,並基於kubernetes ingress 資源在集群中路由流量。
集群內其他相互對話的(微)服務可透過ClusterIP服務和開箱即用的DNS服務發現進行對話。
註意:請避免使用服務的公共DNS/IP進行通訊,因為這會增加延遲並提升雲成本。
11. 未感知集群自動擴充套件
對於非Kubernetes感知的集群自動擴充套件,單純依賴簡單的指標(如CPU利用率)來添加或刪除節點是不夠的。在排程pod時,需要綜合考慮眾多 排程約束 條件,如pod和節點的親和性、汙點和容忍度、資源請求以及QoS等。如果外部自動擴充套件工具不了解這些約束,可能會導致排程問題。
例如,當所有可用CPU資源均被請求時,即使有新的pod需要排程,也可能因為資源不足而陷入 Pending狀態 。如果外部自動擴充套件器僅基於當前使用的CPU平均值(而非已請求的資源)來決策,可能就不會觸發擴充套件,從而導致pod無法排程。
向內擴充套件(即從集群中移除節點)同樣復雜。特別是對於有狀態的pod(如繫結了持久卷的pod),由於 持久卷 通常與 特定可用區域 繫結,自訂自動擴充套件器若移除帶有此類pod的節點,可能導致排程器無法在其他節點上重新排程該pod,因為其他節點可能沒有相應的持久卷。
幸運的是,社群中有成熟的cluster-autoscaler(CA元件),它們與主流公有雲供應商的API整合,了解上述各種限制,並能在不影響既定約束的條件下進行優雅伸縮,從而幫助節省計算成本。
總結
總之,Kubernetes 是管理容器化應用程式的強大工具,但使用時也需註意其帶來的挑戰。為避免常見錯誤和陷阱,需深入了解Kubernetes的工作原理及其與已部署服務的互動方式。
不要期望一切都能自動執行,投入時間和精力讓您的套用真正雲原生化,將有助於提高Kubernetes環境的穩定性、效能和安全性。
作者丨Seifeddine Rajhi 編譯丨onehunnit
來源丨medium.com/@seifeddinerajhi/most-common-mistakes-to-avoid-when-using-kubernetes-anti-patterns-️-f4d37586528d
*本文為dbaplus社群編譯整理,如需轉載請取得授權並標明出處! 歡迎廣大技術人員投稿,投稿信箱:[email protected]
活動推薦
2024 XCOPS智慧運維管理人年會·廣州站將於5月24日舉辦 ,深究大模型、AI Agent等新興技術如何落地於運維領域,賦能企業智慧運維水平提升,構建全面運維自治能力! 碼上報名,享早鳥優惠。












