引言
AI經過長時間的發展,已經能夠生成從一維到四維的內容了。
從一維的生成文字,到二維生成圖片和視訊再到生成三維模型,再到在三維模型的基礎之上加上動作生成四維模型。
而從一維到三維的生成人工智慧方面已經有了較為不錯的研究成果,一維的ChatGPT、二維的Sora、三維的Google的CAT3等,唯獨四維還沒有較好的模型出現。
直到最近 由多倫多大學,北京交通大學,德克薩斯大學奧斯丁分校和劍橋大學團隊最新提出的4D生成擴散模型 Diffusion出現 。
詳細介紹
那有人可能就問了,不就是個4D合成嗎,又不是第一個,有什麽牛的?
那你可就不知道了吧!
在 Diffusion4D模型 釋出之前,早期的4D合成工作借鑒了預訓練的影像或視訊擴散模型中的外觀和運動經驗,並利用 得分蒸餾采樣(SDS) 進行最佳化。
這種策略由於需要大量的監督反向傳播,使得計算效率低下,耗時長,限制了其廣泛的套用性。
並且在生成4D模型時會產生最佳化速度慢和多檢視不一致問題。簡而言之就是形成4D模型的速度慢且生成的模型不一定好。
而我們今天要介紹的這個Diffision4D模型,是第一個利用 大規模數據集 , 訓練視訊生成模型生成4D內容 的框架。這可真謂是大姑娘上轎——頭一回!
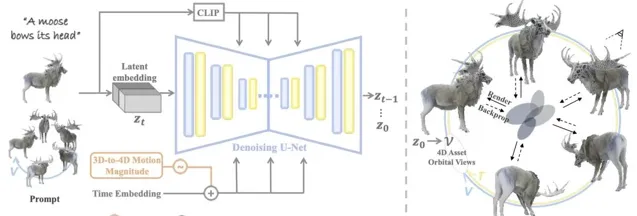
透過該種訓練模式, Diffusion4D 在 生成效率 和各種提示模式的4D 幾何一致性 方面超越了現有技術。
不管是文字內容,圖片內容還是視訊內容,它都能很好地將其轉化成4D形式。
文字轉4D
影像轉4D
視訊轉4D
套用前景
看到這有人可能會接著疑惑了,它再厲害和我們有什麽關系呢。
害。這你可能就又有所不知了,它跟我們日常生活的關系可大著呢!
讓我們想象一下,在我們參觀博物館時,出現在我們眼前的不只是放在展台裏的展品,還有漂浮在空中的全方位的展品,並能感受到展品隨著時間的變遷產生的變化。
當醫學生在上課時,白板上出現的不再只是一張張圖片,而是一個個4D的正在蠕動著的器官,這樣的課堂豈不是很生動自然,學生們學習的熱情也會更加高漲。
諸如此類的套用還有很多等著我們去開發,為我們的生活帶來更多的便捷。
計畫連結:
https://vita-group.github.io/Diffusion4D/
掃碼加入AI交流群
獲得更多技術支持和交流

關註「 向量光年 」公眾號
加速全行業向AI的改變
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新資訊











