計畫簡介
到目前為止,沒有其他視訊生成模型能夠與 Sora 的效能或其支持廣泛視訊生成任務的能力相匹敵。此外,目前公開釋出的視訊生成模型寥寥無幾,大多數都是閉源的。為了填補這一空白,本文提出了一個新的多代理框架 Mora,它結合了幾個先進的視覺 AI 代理,以復制 Sora 所展示的通用視訊生成能力。
掃碼加入交流群
獲得更多技術支持和交流
(請註明自己的職業)

Mora 能夠利用多個視覺Agent,並成功模仿 Sora 在各種任務中的視訊生成能力,例如 (1) 文本到視訊的生成,(2) 基於文本條件的影像到視訊生成,(3) 擴充套件生成的視訊,(4) 視訊到視訊的編輯,(5) 連線視訊以及 (6) 模擬數位世界。我們廣泛的實驗結果表明,Mora 在各種任務中達到了與 Sora 接近的效能。然而,在全面評估時,我們的工作與 Sora 之間存在明顯的效能差距。總之,我們希望這個計畫能夠引導視訊生成的未來發展方向,透過協作的 AI Agent來實作。

與Sora效果對比
透過對比發現,mora跟sora生成的視訊是幾乎一樣的
·Sora
·Mora
基於Agent的視訊生成
Agent的定義與專業化。Agent的定義使得將復雜工作分解成更小、更具體的任務變得更加靈活。解決不同的視訊生成任務通常需要具有不同能力的Agent的合作,每個Agent都貢獻出專門的輸出。在這個框架中,有 5 個基本角色:提示選擇與生成Agent,文本到影像生成Agent,影像到影像生成Agent,影像到視訊生成Agent以及視訊到視訊Agent。
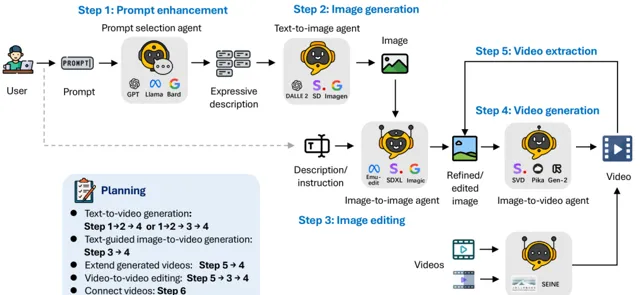
·提示選擇與生成Agent :在初始影像生成開始之前,文本提示會經過嚴格的處理和最佳化階段。這個關鍵Agent可以使用大型語言模型,如 GPT-4、Llama 。它旨在細致地分析文本,提取其中關鍵的資訊和動作,從而顯著增強最終影像的相關性和品質。這一步確保文本描述被充分準備,以便高效、有效地轉換成視覺表現。
·文本到影像生成Agent :文本到影像模型位於將這些豐富的文本描述轉換成高品質初始影像的前沿。其核心功能圍繞著對復雜文本輸入的深入理解和視覺化,使其能夠精確地建立出與提供的文本描述相匹配的詳細和準確的視覺對應物。
·影像到影像生成Agent :這個Agent工作是根據特定的文本指示修改給定的源影像。它的核心功能在於能夠高精度地解釋詳細的文本提示,並據此調整源影像。這涉及到詳細辨識文本的意圖,將這些指令轉換為從細微變更到變革性變化的視覺修改。該Agent利用預訓練的模型,橋接文本描述和視覺表現之間的差距,實作新元素的無縫整合、視覺風格的調整或影像構成方面的變更。
·影像到視訊生成Agent :在初始影像建立之後,視訊生成模型負責將靜態幀過渡到充滿活力的視訊序列。這一元件深入分析初始影像的內容和風格,為生成後續幀提供基礎。這些幀被精心制作,以確保流暢的敘事流動,結果是一個在整個過程中保持時間穩定性和視覺一致性的連貫視訊。這一過程突出了模型不僅能理解和復制初始影像,還能預測和執行場景中的邏輯進展的能力。
·視訊連線Agent :利用視訊到視訊代理,我們基於使用者提供的兩個輸入視訊建立無縫過渡視訊。這個高級Agent從每個輸入視訊中選擇性地利用關鍵幀,以確保它們之間的平滑且視覺上一致的過渡。它被設計具有準確辨識兩個視訊中共同元素和風格的能力,從而確保產出的連貫性和視覺吸重力。這種方法不僅改善了不同視訊段之間的無縫流動,而且還保留了每個段落的獨特風格。
每個Agent負責特定的輸入和輸出。這些結果可以用於不同的設計任務。
論文連結
https://arxiv.org/abs/2403.13248
關註「 開源AI計畫落地 」公眾號











