PART 1
點選上方 藍字 關註我們
本文繼續探討超長上下文LLM時代的RAG套用。(上篇: )
01
超長上下文LLM下的RAG
SPRING HAS ARRIVED
當具備超長上下文的LLM橫空出時候,我們當然有理由期望能夠把所有的東西塞給LLM來一次生成,而忘掉諸如Split、Chunk_size、向量、索引等一系列RAG的概念,這就像扔一本百科全書給一名記憶力足夠好的優秀學生:
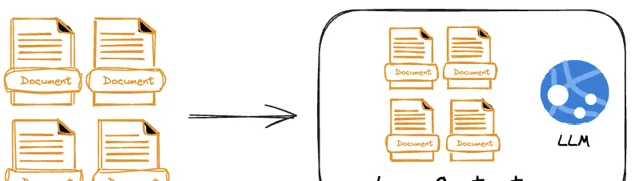
但這裏的問題是,在一個超長的「百科全書」中精確的定位知識條目是需要代價的。我們在 上篇中看到了超長上下文LLM的「大海撈針」能力的系列測試,其很大程度上需要依賴於知識的位置、數量以及上下文長度,具有一定的不確定性,如果再考慮到工程上的一次性知識攝入、響應效能、tokens成本等問題,把所有的知識一股腦塞給LLM顯然並不現實。
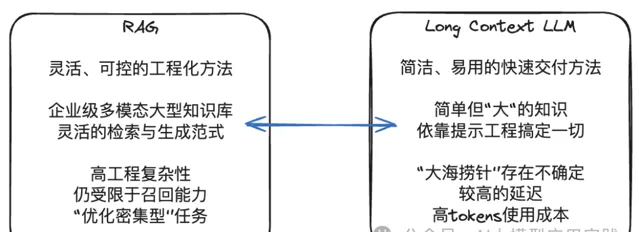
另一方面,RAG套用發展到現在,盡管更加靈活與可控,但由於其具備的工程復雜性、涉及更多的調優參數、不同的索引型別、生成模式等,都需要根據實際套用與數據特點做靈活調整,否則很容易掉進「看上去很簡單,做起來很困難」的陷阱。
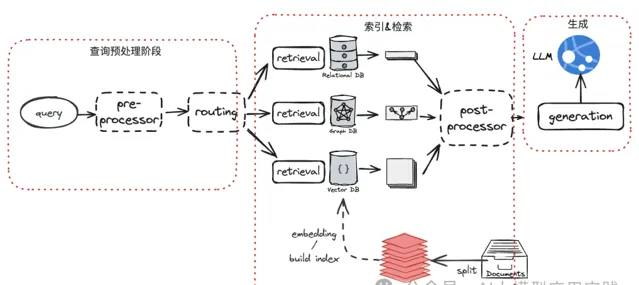
越來越復雜的RAG架構
所以更現實的問題或許是,
如何在RAG與長上下文的LLM之間取得平衡?
LangChain公司的Lance在最近的分享中提出了這樣一種可能:
既然LLM帶來了足夠大的上下文視窗,那麽未來的RAG或授權以 使用文件(Document)而不是文本塊(Chunk)作為檢索召回的最小單位,因此也不再需要分割(split)這個環節。這在超長上下文的LLM環境中或許更合理,因為大部份的文件將完全可以容納在未來的LLM上下文視窗之中。
這樣的RAG將繞過在Chunk層的拆分、索引以及精準召回的需要(這也是目前RAG中最佳化最復雜的部份),而是提升到在Document層。
在文件層面實作索引與召回,或許還可以解決的一個棘手問題是:目前在多模態非結構化文件內容的拆分、解析與嵌入的復雜性。
02
基於文件的索引與召回
SPRING HAS ARRIVED
如果期望在Document這個單位上去實作召回,以利用超長上下文視窗的LLM簡化RAG工程,在整個流程中影響最大的顯然是
索引與檢索環節
。
【直接文件嵌入】
當前RAG普遍使用嵌入模型生成向量後的相似性來實作語意搜尋;所以如果把這種方法直接套用到文件級別也是成立的: 將整個文件嵌入然後透過相似演算法獲取top_K相關文件。
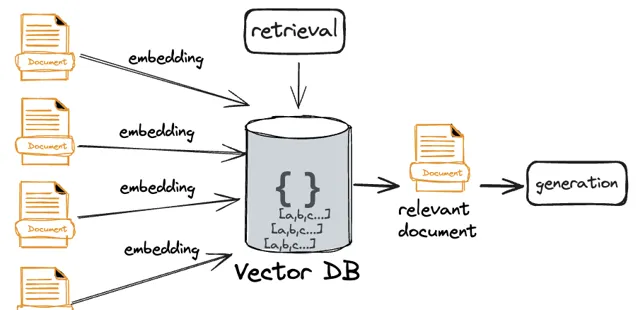
但這裏的潛在問題是: 盡管試圖透過向量相似來召回相關的文件,但會進一步放大召回精準性的問題。 其根源來自於一個事實: 文本向量的語意精確性與豐富性是一對矛盾體。不再經過拆分的文件盡管具有更加豐富的上下文資訊,但嵌入的向量卻缺乏足夠的語意精準度,這在實際的檢索環節可能會體現出幾種可能:
你的top_K較小,可能導致你需要的文件沒有被檢索出來
你的top_K較大,可能也就喪失了文件檢索的意義
還有一種復雜的情況是,如果輸入問題需要結合多個文件中的內容回答,很難保障召回的相關文件中包含所必需的更完整的上下文
這裏介紹兩種可能的最佳化解決方案,以在一定程度上緩解這個問題:既無需分塊以充分利用超長的LLM上下文能力;也能提供更精準的文件級索引與召回能力。
【摘要索引方案】
在這種方案中,透過對文件生成另外一種更適合檢索的語意表示來實作。
在構建索引時 :借助LLM生成文件的摘要內容(也可以自己編寫與補充針對文件的摘要提示),並對摘要內容進行嵌入,同時建立其與原始文件的連結關系
在輸入檢索時 :根據問題與摘要的相似性做檢索,再透過連結關系獲取到全部的完整原始文件
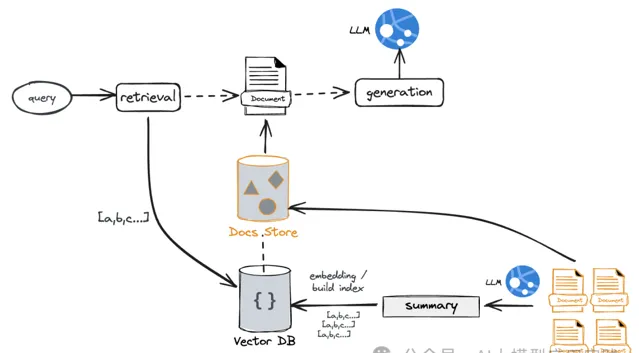
這種方案的好處是:
透過摘要生成語意更集中、更緊湊的文件表示,並基於此進行檢索,具備更高的檢索精準性
對於一些很長,但是內容很松散的文件,可以大大的減少其中無關資訊對檢索的幹擾
透過關聯關系,你仍然可以獲取到完整的文件資訊,將其組裝到足夠的上下文視窗進行生成
這種方案的主要挑戰來自於摘要的有效性。因為摘要是嵌入與檢索的物件,因此其品質決定了後續召回的品質,在實際套用中需要充分評估摘要生成使用的LLM以及Prompt,適當的人工摘要補充也是必要的。
【文件樹方案(RAPTOR)】
這種方案的思想來自於一篇關於RAG檢索的實驗性方法的論文( RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL)。
RAPTOR本意是針對目前基於分塊的向量檢索限制了對上下文的整體資訊獲取與理解,從而采用了一種構造「從上至下不同級別的摘要樹「的最佳化方法(試想下,很多問題是需要對整個甚至多個文件知識進行理解後才能回答,僅有top_K的分塊是不夠的)。
這裏嘗試把RAPTOR的思想套用到基於文件的檢索方案中:
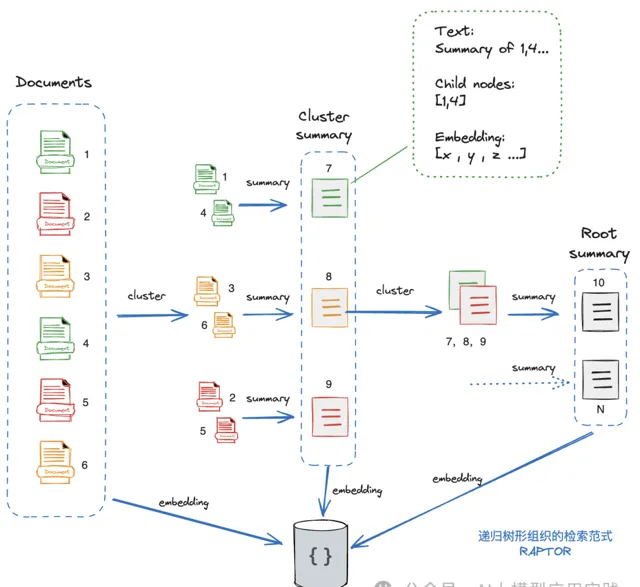
基本的思想是:從基礎節點開始(Leaf Nodes,在這裏就是原始文件,比如這裏有6個),對這些文件做嵌入並生成向量表示;然後對這些文件進行聚類(透過聚類演算法,這裏分成了3組),可以簡單的理解成把「相關」的文件進行智慧分組;然後對每個分組文件生成摘要Summary,然後可以把生成的摘要看成一組具備更高抽象與語意的文件(即3個新的摘要文件);然後遞迴執行前面的操作(embedding->cluster->summary),直到沒有新的聚類產生。
最後,就完成了一棵完整的文件樹。在這個圖中可以看到,這裏的文件樹由從1到10共10個文件組成,其中1-6是原始文件,7-9是中間層文件,10是根級文件(不一定只有一個根文件),可以把
高層的文件理解成是低層若幹個文件的精簡版
。同時,
所有這些文件的embedding向量資訊會被儲存到向量庫。
RAPTOR方案在檢索時有兩種方式:
一種是樹遍歷檢索:
從根級節點開始,基於向量相似性與父子關系,進行逐層向下檢索,最後檢索出全部相關的節點文件,作為最終輸出的相關文件。
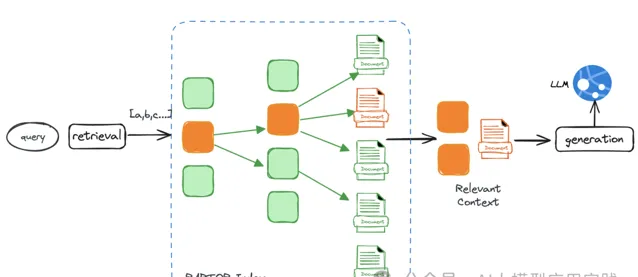
另外一種是直接全量檢索: 將樹展開單層,然後直接對所有文件節點進行向量相似性檢索,檢索出所有的相關節點文件。這種方式更快速且不會遺漏。

RAPTOR方案的好處是:
在不同層次的多個級別上構建了語意表示並實施嵌入,提高了檢索的召回能力
可以有效且高效的回答不同層次的問題,有的問題在低階節點解決,有的則由高階節點來完成
適合需要多個文件的理解才能回答的輸入問題,因此對於綜合性的問題有更好的支持
RAPOR還是一種實驗性的方案,感興趣的可以研究其公開的論文與程式碼。
03
生成階段:進一步完善
SPRING HAS ARRIVED
相對於索引與召回階段,我們相信響應生成環節在更長的上下文空間下並不會有太多的本質變化。超長上下文的LLM對生成階段帶來的積極意義有:
由於視窗的增加,可以攜帶更豐富的內容與語意交給LLM,幻覺的機率可以進一步降低
更長的上下文有利於回答更多型別的問題以及更細節的輸出,比如回答基於全文與高層語意理解的問題
簡化了開發與調優過程。在上下文空間受限條件下需要精確的對視窗內的tokens進行控制的需求會降低
事情總有兩面性,就像RAG中的chunk_size大小一樣。超長上下文帶來的消極一面是
幹擾與噪音也更多了
,在檢索環節如果召回的文件缺乏足夠的精度,或者受到關聯知識在上下文中的位置影響,以及LLM對超長上下文理解的一些偏差現象,仍然可能導致生成品質的下降。
當然,RAG發展到現在,生成環節也 已經不再是丟給LLM一個巨大的上下文然後要求它回答問題。 在這個環節已經有很多成熟的模式, 甚至一些復雜的工作流範式。比如透過多個召回知識進行叠代Refine的模式、自我糾正並借助外部搜尋的C-RAG模式、自省式的Self-RAG等。
以之前介紹過的Self-RAG為基礎,在超長上下文與以文件為單位做召回的背景下,我們設計一個改進的的RAG範式如下圖:
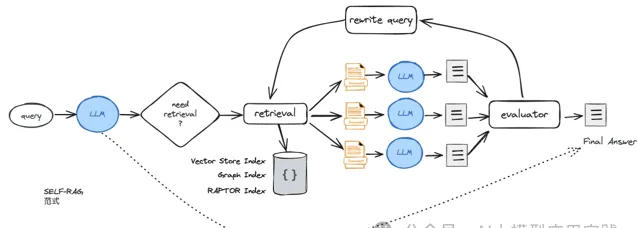
在這個範式裏,召回多個document以後,會進行多次生成,然後對生成結果的品質進行反思、評估並「擇優錄用」;如果無法獲得滿意的評估結果,則在Rewrite後重新召回新的文件進行生成,直到滿足評估要求或者達到叠代次數的限制。
Self-RAG的範式在框架LlamaIndex與Langchain中都有一個實作,但兩者有較大的區別。LlamaIndex的實作更貼近原論文的實作,但依賴於微調模型;LangChain則基於自身的LangGraph做改進與構建,無需依賴於微調模型。
04
結束語
SPRING HAS ARRIVED
以上就是我們對超長上下文的LLM背景下,RAG套用的共存以及變化的一些粗淺思考與分析,這裏結合了一些來自諸如LangChain、LlamaIndex開發框架的觀點以及一些實驗性的計畫,後續還將對其中的一些方案做實際論證與測試。
無論怎樣,一個能夠容納更多上下文的LLM視窗會讓套用有著更加遊刃有余的空間,但指望LLM解決所有的問題無疑也是不現實的,如何在LLM與RAG方案兩者之間取長補短,並達到1+1>2的效果才是在後續工程中最應該去探討與實作的問題。
END
點選下方關註我,不迷路
交流請辨識以下名片並說明來源











