編者按 : 近日,OpenAI釋出其第一個視訊生成模型「Sora」,該模型生成的視訊內容可以呈現出多個角色、特定動作以及復雜場景,為構建能夠理解和模擬現實世界的人工智慧模型奠定了基礎。
本文解析的重點即是 Sora 背後的核心技術 Spacetime Patches,作者認為該技術透過創新的時空數據建模方法,讓 Sora 學會預測時空維度上事件和物件的變化、運動和互動,從而建立起視訊世界的物理模型,生成極其逼真的視訊。
這確實是生成模型領域的裏程碑,也是一個 AGI 的裏程碑。編者相信,沒準有一天,哆啦A夢的二次元口袋照相機也可能成為現實。
作者 | Vincent Koc
編譯 | 嶽揚
人工智慧如何將靜態影像轉換為動態、逼真的視訊?OpenAI的 Sora 透過創新性地使用時空修補程式技術(spacetime patches)給出了一個答案。
在快速發展的生成模型領域,OpenAI 的 Sora [1] 是一個重要的裏程碑,有望重塑我們對視訊生成的理解和認識。本文將解讀 Sora 背後的技術 [2] 以期激發新一代模型在影像、視訊和3D內容建立方面的潛力。
OpenAI Sora演示 —— 床上的貓。來源:OpenAI
上述演示是 OpenAI 使用以下提示詞生成的: A cat waking up its sleeping owner demanding breakfast. The owner tries to ignore the cat, but the cat tries new tactics and finally the owner pulls out a secret stash of treats from under the pillow to hold the cat off a little longer. —— 透過Sora生成的視訊內容幾乎達到了無以倫比的逼真程度。 由於 Sora 正在進行測試,完整模型尚未完全向公眾釋出。
01
Sora 的獨特方法如何改變視訊生成的方式
在生成模型(generative models)領域的發展過程中,我們見證了從生成式對抗網路(GAN)到自回歸(auto-regressive)和擴散模型(diffusion models)等多種方法的演變,它們都有各自的優勢和局限性。Sora透過采用新的模型技術和憑借其高度靈活性帶來了範式轉變,能夠處理多種多樣的視訊時長(duration)、寬高比(aspect ratio)和分辨率(resolution)。
Sora結合了擴散原理(diffusion)和 transformer 架構,提出了diffusion transformer model ,並具有如下特性:
文字到視訊 :這種功能我們應該已經見到過很多次了
影像到視訊 :為靜態影像賦予生命
視訊到視訊 :將視訊的風格轉換為其他樣式
修改視訊時間 :擴充套件和縮短視訊
建立無縫迴圈視訊 :建立看起來無限迴圈的平鋪視訊 (譯者註:在視訊編輯領域,Tile(平鋪)是一個專業術語,指的是將一個視訊片段復制並拼接,重復排列形成一個新的視訊畫面的技術。)
影像生成 :雖然只是單幀靜止畫面,但是稱得上一部「單幀電影」(分辨率高達2048 x 2048)
生成任何分辨率的視訊 :從1920 x 1080 到 1080 x 1920,應有盡有
模擬虛擬世界 : 像 Minecraft 和其他視訊遊戲
建立視訊 : 最長1分鐘,包含多個短視訊
想象一下,你正在一個廚房裏。像Pika [3] 和RunwayML [4] 這樣的傳統視訊生成模型就像嚴格遵循食譜的廚師,他們能夠制作美味佳肴(視訊),但受限於他們所知的食譜(演算法)。這些「廚師」可能專攻制作蛋糕(短視訊)或義大利直麵(某型別視訊),使用特定的「食材」(數據格式)和「烹調技術」(模型架構)。
相比之下,Sora像是全能大廚,對食品風味的構成與變化了如指掌。 Sora不僅能遵循食譜,還持續創造新的菜式。 數據和模型架構的靈活性,讓 Sora 能生產出一系列高品質的視訊,堪比大師廚藝的多變與精湛。
02
探索 Sora 秘方的核心:Spacetime Patches 技術
Spacetime Patches 是 Sora 創新的核心,它建立在谷歌 DeepMind 早先對 NaViT [5] 和 ViT(Vision Transformers)的研究基礎之上,其基礎是一篇 2021 年的論文【An Image is Worth 16x16 Words [6] 】。
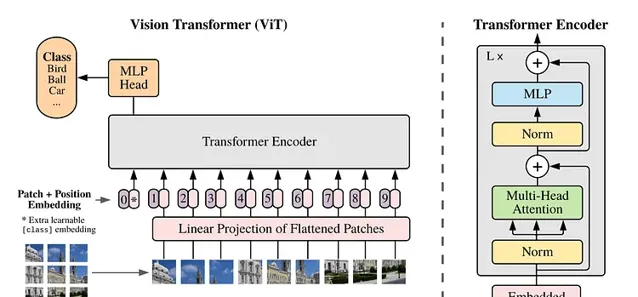
「Vanilla」 Vision Transformer 架構 —— 圖片來源:Dosovitskiy等,2021 [6]
在傳統的 Vision Transformers 中,我們使用一系列影像 "修補程式(patches)" 來訓練模型進行影像辨識,而不是像訓練 language transformers 那樣使用單詞來進行訓練。透過 "修補程式(patches)",我們可以擺脫摺積神經網路對影像處理的束縛。
如何將幀/影像「打修補程式」 —— 圖片來源:Dehghani等,2023 [5]
然而,Vision transformers 受到影像訓練數據的限制,這些數據的大小和長寬比都是固定的,這就限制了影像的品質,並需要對影像進行大量的預處理。
切割視訊時態數據的視覺化 —— 資料來源:kitasenjudesign [7]
透過將視訊處理為修補程式序列(sequences of patches),Sora保持了原始的長寬比和分辨率,這與 NaViT 處理影像的方式類似。 這種保留對於捕捉視覺數據的真實本質至關重要,可使模型從更準確的世界表征中學習,從而賦予Sora其近乎魔法的準確性。
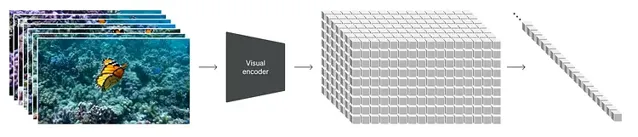
Spacetime Patching(處理)的視覺化 —— 圖片來源:OpenAI(Sora)
透過這種方法,Sora 可以高效地處理各種視覺數據,而無需調整大小或進行填充等預處理步驟。這種靈活性確保了每一條數據都有助於模型的理解,就像廚師使用各種配料來提升菜肴的風味一樣。
透過 Spacetime Patching 技術詳細而靈活地處理視訊數據,為Sora擁有精確的物理模擬和三維一致性等復雜特性奠定了基礎。 這些能力對於建立不僅看起來逼真,而且符合世界物理規則的視訊至關重要,讓我們看到了人工智慧建立復雜、動態視覺內容的潛力。
03
餵養Sora:多樣化數據在訓練中的作用
生成模型的表現與訓練數據的品質和多樣性密不可分。 現有的視訊模型傳統上是在更受限的數據集上訓練的,時長較短,目標較窄。
Sora的訓練數據集廣泛多樣,包含不同長度、分辨率和長寬比的視訊與影像。其重現 Minecraft 等數位世界的能力 [8] ,極有可能吸收了來自Unity、Unreal等系統的模擬鏡頭數據,以捕捉更豐富視角和風格的視訊內容。這讓Sora類似GPT語言模型,達到視訊生成的「全能」境界。
豐富數據訓練使Sora能夠深刻理解復雜動力學,生成既多樣又高品質的內容。 這種方法模仿了大語言模型在多樣化文本上的訓練方式,將類似理念套用於視覺數據,以獲得通用能力。

使用可變修補程式(patches)的 NaVit vs. 傳統的 Vision Transformers —— 圖片來源:Dehghani等,2023 [5]
正如 NaViT 模型透過將來自不同影像的多個修補程式(patches)打包到單個序列中,能夠顯著提高訓練效率和效能一樣,Sora 利用時空修補程式(Spacetime Patching)實作了在視訊生成場景中類似的生成效率。 這種方法可以更有效地學習龐大的數據集,提高模型生成高保真視訊的能力,同時與現有模型架構相比還可以顯著降低所需的計算量。
04
讓模擬的物理世界栩栩如生:Sora 對三維空間和視訊連貫性的掌控
三維空間以及物體的運動和互動具有邏輯性和一致性是 Sora 演示中的一大亮點。透過對大量視訊數據進行訓練,而不對視訊進行調整或預處理,Sora 可以學習對物理世界進行建模,而且其準確性令人印象深刻,因為它能夠以原始形式消化訓練數據。
它能生成數位世界和視訊,在這些視訊中,其中的物體和角色在三維空間中移動和互動,即使在它們被遮擋或離開畫面時也能保持連貫性,令人信服。
05
展望未來:Sora對生成模型的啟示
Sora為生成模型樹立一種新的高標準。這種技術極有可能激發開源社群繼續探索視覺生成領域的新邊界,驅動新一代生成模型的發展,打破創造力和內容真實性的限制。
Sora 的征程才剛剛開始,正如 OpenAI 所說: 「擴大視訊生成模型的規模是建立物理世界通用模擬器的一條大有可為的道路。」
Sora技術與最新的AI研究和實踐套用的融合,預示著生成模型的光明前景。隨著這些技術的持續演化,必將重新定義我們與數位內容的互動,使高保真、動態視訊生成變得更加便捷和多樣。
Thanks for reading!
END
參考資料
[1]https://openai.com/sora
[2]https://openai.com/research/video-generation-models-as-world-simulators
[3]https://pika.art/home
[4]https://runwayml.com/ai-tools/gen-2/
[5]https://arxiv.org/abs/2307.06304
[6]https://arxiv.org/abs/2010.11929
[7]https://twitter.com/kitasenjudesign/status/1489260985135157258
[8]https://techcrunch.com/2024/02/15/openais-sora-video-generating-model-can-render-video-games-too/
原文連結:
https://towardsdatascience.com/explaining-openai-soras-spacetime-patches-the-key-ingredient-e14e0703ec5b
如果覺得有幫助,就點點 『在看』 哦!











