評估過程與評估結果
作為解決大模型幻覺的利器,RAG的搭建簡單,成本低,現在也有各種開源的RAG工具,像Langchain-chatchat、ragflow、qanything等,不用懂編程,直接就能上手部署。
不過這麽多RAG工具,到底該怎麽選?或者我們自己編寫一個RAG,怎麽知道好壞?
如何評估RAG的好壞是絕對繞不過的一個話題。
評估RAG除了能幫助我們選擇更適合RAG工具,還能在最佳化RAG的時候讓我們有據可依,透過評估可以知道應該如何最佳化和調整參數。
不過如何評估一個RAG可是個復雜的問題,大模型的結果不是固定的,就意味著這不是一道判斷題或者數學題,每個問答都是作文題。
為了解決這個復雜的問題,一般評估可分為按元件評估( 評估過程 )和端到端評估( 評估結果 ):
按元件評估就是把RAG看做一個工廠流水線,透過評估流水線中各個元件的效能,然後把這些元件的結果匯總成一個總的得分。
比如可以透過 上下文相關性(問題和檢索結果的關聯程度) 和 上 下文召回率(是否找到了最相似的結果) 來評估檢索階段的成績,透過 答案和問題的相關性、答案和檢索內容的相關性和正確性 來評估生成階段的結果是否及格。
元件評估一般是在測試階段,可以便於透過設定標準答案和錯誤答案的數據集來詳細驗證RAG的結果。
端到端評估( 結果評估 )也至關重要,因為它直接影響使用者體驗。一般透過評估忠誠度(衡量了生成的答案在給定的上下文中的事實一致性)和答案正確性(避免錯誤的答案或者錯誤的格式)來評估流水線整體效能的度量標準。
評估框架
但是這些指標需要怎麽套用在RAG程式裏呢?別擔心,有現成的。
Trulens
TruLens是一款旨在評估和改進 LLM 套用的軟體工具,它相對獨立,可以整合 LangChain 或 LlamaIndex 等 LLM 開發框架。它使用反饋功能來客觀地衡量 LLM 套用的品質和效果。這包括分析相關性、適用性和有害性等方面。TruLens 提供程式化反饋,支持 LLM 套用的快速叠代,這比人工反饋更快速、更可延伸。
開源連結:https://github.com/truera/trulens
使用手冊:https://www.trulens.org/trulens_eval/install/
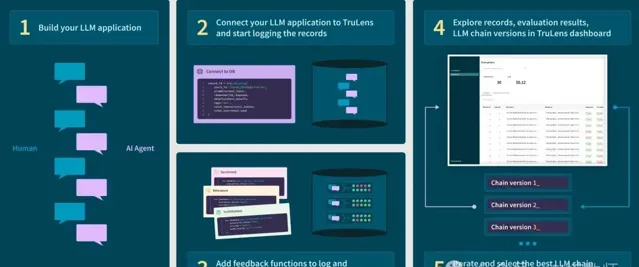
使用的步驟:
(1)建立LLM套用
(2)將LLM套用與TruLens連線,記錄日誌並上傳
(3)添加 feedback functions到日誌中,並評估LLM套用的品質
(4)在TruLens的看板中視覺化檢視日誌、評估結果等
(5)叠代和最佳化LLM套用,選擇最優的版本
其對於RAG的評估主要有三個指標:
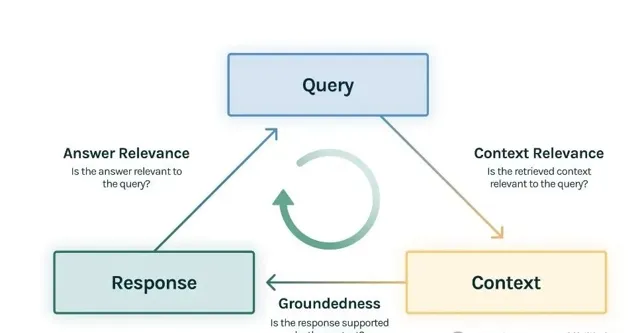
上下文相關性(context relevance): 衡量使用者提問與查詢到的參考上下文之間的相關性
忠實性(groundedness ):
衡量大模型生成的回復有多少是來自於參考上下文中的內容
答案相關性(answer relevance):
衡量使用者提問與大模型回復之間的相關性
TruLens的好處就是對RAG的評估不需要有提前收集的測試數據集和相應的答案。
RAGAS
RAGAS應該是最著名的RAG評估框架了,最初是作為一種無需參照標準的評估框架而設計的。這意味著,RAGAs 不需要依賴評估數據集中人工標註的標準答案,而是利用底層的大語言模型進行評估。
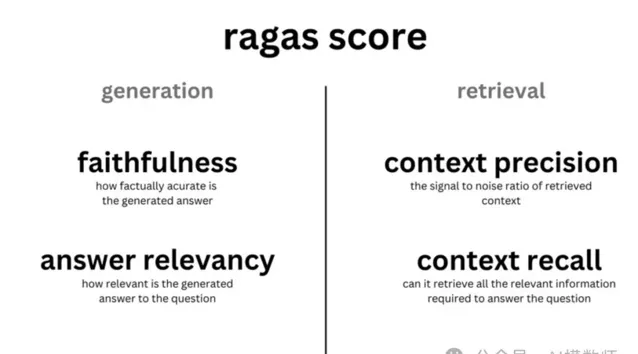
RAGAS包含四個指標,與Trulens的評估指標有些類似:
評估檢索品質:
context_relevancy(上下文相關性,也叫 context_precision)
context_recall(召回性,越高表示檢索出來的內容與正確答案越相關)
評估生成品質:
faithfulness(忠實性,越高表示答案的生成使用了越多的參考文件(檢索出來的內容))
answer_relevancy(答案的相關性)
自動化評估
雖然有了評估的標準和工具,但是上面的方法只是告訴我們這些指標的結果。就像去醫院體檢一樣,但是體檢結果還是看不懂啊。但是RAG去哪找大夫解讀呢?
最傳統的方式還是進行人工評估,透過邀請行業專家或人工評估員對RAG生成的結果進行評估。他們可以根據預先定義的標準對生成的答案進行品質評估,如準確性、連貫性、相關性等。
這種評估方法可以提供高品質的反饋,但可能會消耗大量的時間和人力資源。只適合在測試評估階段使用,在生產環境的監控中,可沒辦法一直依靠人工評估。自動化評估肯定是RAG評估的主流和發展方向,現在最常用的就是LangSmith和Langfuse了。
LangSmith
LangSmith是一個用於偵錯、測試和監控LLM應用程式的統一平台。會記錄大模型發起的所有請求,除了輸入輸出,還能看到具體的所有細節,包括:
請求的大模型、模型名、模型參數
請求的時間、消耗的 token 數量
請求中的所有上下文訊息,包括系統訊息
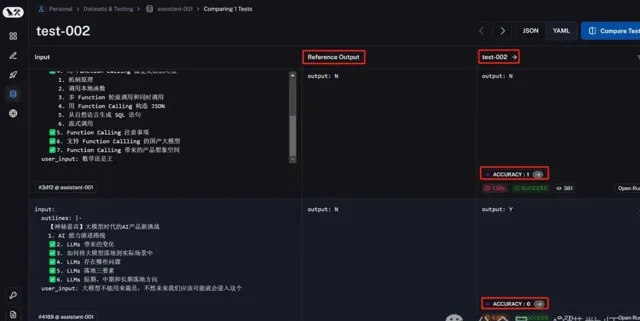
Langfuse
Langfuse作為LangSmith的平替,可以幫助開發者和運維團隊更好地理解和最佳化他們的LLM套用。透過提供即時的和視覺化的跟蹤功能,LangFuse使得辨識和解決套用效能問題變得更加簡單和高效。
主要是基於可觀察性和分析技術來監控和最佳化 LLM 套用。它提供了一套完整的解決方案,透過收集、處理和分析 LLM 套用在執行過程中產生的各種數據,來生成即時的結果。
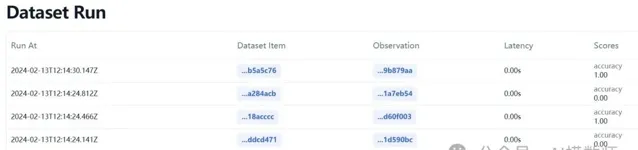
以上兩個平台對RAG的評估,都可以自訂自己的評估函式。當然其也支持一些內建的評估函式。不僅可以開箱即用,還支持持續叠代和客製化,絕對 LLM 運維過程中必不可少的工具。
總結
隨著人工智慧技術的飛速發展,RAG工具的評估和最佳化已成為我們不可或缺的技能。TruLens、RAGAS、LangSmith和Langfuse等工具的出現,為我們提供了強大的支持,讓我們能夠更精準地評估和最佳化LLM套用,推動AI技術的進步。讓我們攜手並進,共同探索AI的無限可能!
在這個AI為王的時代,評估不再是選擇題,而是必答題。掌握它,你就掌握了開啟智慧世界的鑰匙。
如果未來的AI能夠自我評估和最佳化,我們人類的角色將會怎樣轉變?是成為旁觀者,還是成為引導者和創造者?
作者丨AI模數師
來源丨公眾號:AI模數師(ID:ai_Modular)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












